作者 : 荣仔!最靓的仔!专栏地址 : http://suo.im/5Rh1z1
本文目录
1 re模块 正则表达式(Regular Expression, Regex 或 RE)又称正规表示法或常规表示法,常用来检索、替换那些符合某个模式的文本。
它首先设定好一些特殊的字符及字符组合,然后通过组合的“规则字符串”来对表达式进行过滤,从而获取或匹配用户想要的特定内容。
1.1 re模块 Python 通过 re 模块提供对正则表达式的支持,但在使用正则表达式之前需要导入 re 模块才能调用该模块的功能函数。
import re其基本步骤是:
将正则表达式的字符串形式编译为 pattern 实例;
使用 pattern 实例处理文本并获得一个匹配实例;
常用函数是 findall,原型如下:
findall(String[, pos[, endpos]])|re.findall(pattern, string[, flags]) 该函数表示搜索字符串 string,然后以列表形式返回全部匹配字符串。
其中,参数 re 包括3个常见值。(括号内是完整写法)
re.I(re.IGNORECASE) # 使匹配忽略大小写 # 允许多行匹配 # 匹配包括换行在内的所有字符 另外,pattern 对象是一个编译好的正则表达式,通过 pattern 提供的一系列方法可以对文本进行匹配查找;pattern 对象不能直接实例化,必须使用 re.compile() 进行构造。
1.2 complie方法 re 模块包括一些常用的操作函数,比如 complie() 函数,其原型如下:
re.compile(pattern[, flags]) 该函数根据包含正则表达式的字符串创建模式对象,返回一个 pattern 对象。其中,参数 flags 是匹配模式,可以使用按位或“|”表示同时生效,也可以在正则表达式字符串中指定。
# 举例说明如何使用正则表达式来获取字符串中的数字内容 import re'A1.45, b5, 6.45, 8.82' r"\d+\.?\d*" )结果如下:
1.3 match方法 match 方法是从字符串的 pos 下标处开始匹配 pattern,如果 pattern 结束时已经匹配,则返回一个 match 对象;如果匹配过程中 pattern 无法匹配,或者匹配未结束就已达到 endpos,则返回 None。
match 方法原型如下:
match(string[, pos[, endpos]]) | re.match(patter, string[, flags]) 其中,参数 string 表示字符串;pos 表示下标,pos 和 endpos 的默认值分别为 0 和 len(string);参数 flags 用于编译 pattern 时指定匹配模式。
1.4 search方法 search 方法用于查找字符串中可以匹配成功的子字符串。从字符串的 pos 下标处尝试匹配 pattern,如果 pattern 结束时仍可匹配,则返回一个 match 对象,如果 pattern 结束时仍无法匹配,则将 pos 加 1 后重新尝试匹配,若知道 pos = endpos 时仍无法匹配,则返回 None。
search 方法函数原型如下:
search(string[, pos[, endpos]]) | re.search(pattern, string[, flags]) 其中,参数 string 表示字符串;pos 表示下标,pos 和 endpos 的默认值分别为 0 和 len(string);参数 flags 用于编译 pattern 时指定匹配模式。
1.5 group和groups方法
group([group1, …]) 方法用于获得一个或多个分组截获的字符串,当它指定多个参数时将以元组形式返回 None,截获多次的组返回最后一次截获的字符串。
groups([default]) 方法以元组形式返回全部分组截获的字符串,相当于多次调用 group,其中参数 default 表示没有截获字符串的组以该值代替,默认为 None。
2 Python网络数据爬取的常用模块 2.1 urllib模块 urllib 是 Python 用于获取 URL(Uniform Resource Locators,同意资源定位器)的库函数,可以用于爬取远程的数据并保存,甚至可以设置消息头(header)、代理、超时认证等。
urllib 模块提供的上策接口使用户能够像读取本地文件一样读取 WWW 或 FTP 上的数据,使用起来比C++、C#等编程语言更加方便。
2.1.1 urlopen 函数原型如下:
urlopen(url, data = None , proxies = None ) 该方法用于创建一个远程 URL 的类文件对象,然后像本地文件一样操作这个类文件对象来获取远程数据。其中参数 url 表示远程数据的路径,一般是网址;参数 data 表示以 post 方式提交到 url 的数据;参数 proxies 用于设置代理;返回值是一个类文件对象。
本实例用来介绍 urllib 库函数爬取百度官网的实例
import urllib.requestimport webbrowser as web'http://www.baidu.com' # 打开链接 # 头信息 # 请求url # HTTP状态码 # 保存至本地并通过浏览器打开 'baidu.html' , 'w' ).write(response.decode('UTF-8' ))结果如下:
2.1.2 urlretrieve urlretrieve 方法是将远程数据下载到本地,函数原型如下:
urlretrieve(url, filename = None , reporthook = None , data = None ) 其中,参数 filename 指定了保存到本地的路径,如果省略该函数,则 urllib 会自动生成一个临时文件来保存数据;
参数 reporthook 是一个回调参数,当连接上服务器,响应的数据块传输完毕时,会触发该调回函数,通常使用该回调函数来显示当前的下载进度;
参数 data 是指传递到服务器的数据。
本实例用来演示如何将新浪首页爬取到本地,并保存在“F:/sina.html”文件中,同时显示下载进度。
from urllib.request import urlretrieve# 设置函数来表示下载文件至本地,并显示下载进度 def Download(a, b, c) :# a--已经下载的数据块 # b--数据块的大小 # c--远程文件的大小 100.0 * a * b / cif per >100 :100 '%.2f%%' % per)'http://www.sina.com.cn' 'F:/sina.html' 结果如下:
2.2 urlparse模块 urlparse 模块主要是对 url 进行分析,其主要的操作时拆分和合并 url 各个部件。它可以将 url 拆分成 6 个部分,并返回元组,也可以把拆分后的部分再组成一个 url。
urlparse 模块包括的函数主要有 urlparse、urlunparse 等。
# python3版本中已经将urllib2、urlparse、和robotparser并入了urllib模块中,并且修改urllib模块 from urllib.parse import urlunparsefrom urllib.parse import urlparse2.2.1 urlparse函数 函数原型如下:
urlparse(urlstring[, scheme[, allow_fragments]]) 该函数将 urlstring 值解析成 6 各部分,从 urlstring 中获取 URL,并返回元组(scheme,netloc,path、params、query、fragment)。该函数可用于确定网络协议(HTTP、FTP等)、服务器地址、文件路径等。
from urllib.parse import urlparse'https://blog.csdn.net/IT_charge/article/details/105714745' )# 输出内容包括以下六个部分scheme, netloc, path, params, query, fragment 结果如下:
2.2.2 urlunparse函数 同样可以调用 urlunparse() 函数将一个元祖内容构建成一条 url,函数原型如下:
urlunparse(parts) 该元组类似 urlparse 函数,它接收元组(scheme, netloc, path, params, query, fragment)后,会重新组成一个具有正确格式的URL,以便共 Python 的其他 HTML 解析模块使用。
from urllib.parse import urlunparsefrom urllib.parse import urlparse'https://blog.csdn.net/IT_charge/article/details/105714745' )# 输出内容包括以下六个部分scheme, netloc, path, params, query, fragment # 重组url 结果如下:
2.3 requests模块 requests 模块是用 Python 语言编写的、基于 urllib 的第三方库,其采用 Apache2 Licensed 开源协议的 HTTP 库。它比 urllib 更加方便,既可以节约大量的工作,又完全满足 HTTP 的测试需求。
安装 requests 模块方法
pip install requests 2.3.1 导入requests模块 使用语句如下:
import requests2.3.2 发送GET/POST请求 requests 模块可以发送 HTTP 的两种请求,GET 请求和 POST 请求。其中 GET 请求可以采用 url 参数传递数据,它从服务器上获取数据,而 POST 请求是向服务器传递数据,该方法更为安全。
# 这里给出 get 和 post 请求获取某个网站网页的方法,得到一个命名为 response 的响应对象,通过这个对象获取我们所需要的信息 'https://github.com/timeline.json) https://httpbin.org/post)2.3.3 传递参数 url 通常会传递某种数据,这种数据采用键值对的参数形式置于 URL 中。
requests通过 params 关键字设置 URL 的参数,以一个字符串字典来提供这些参数。
# 传递 key1=value1 和 key2=value2 到 httpbin.org/get 后 import requests'key1' : 'value1' , 'key2' : 'value2' }'http://httpbin.org/get' , params = payload)结果如下:
2.3.4 相应内容 requests 会自动解码来自服务器的内容,并且大多数 Unicode 字符集都能被无缝解码。当请求发出后,requests 会基于 HTTP 头部对响应的编码做出有根据的推测。
import requests'https://github.com/timeline.json' )结果如下:
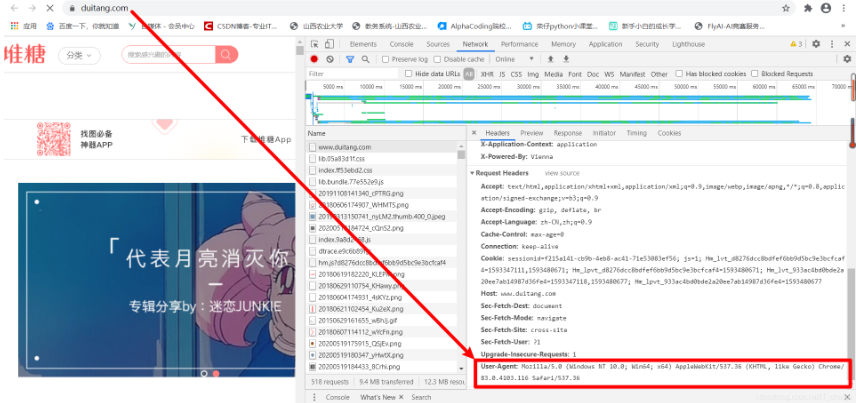
2.3.5 定制请求头 只需要简单地传递一个字典(dict)给消息头 headers 参数即可。以网站“堆糖”为例,其 headers 参数在 User-Agent 里找。
定制请求头是为了伪装爬虫程序,不会被网站轻易检测出来,亦即不会返回 403 错误。
演示如下:
# 这里假设给 堆糖 网站指定一个消息头 import requests'https://www.duitang.com/' 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36' 结果如下:
3 正则表达式爬取网络数据的常见方法 3.1 爬取标签间的内容 HTML语言是采用标签对的形式来编写网站的,包括起始标签和结束标签,比如、、等。
3.1.1 爬取title标签间的内容 首先可以采用正则表达式“‘’”来爬取起始标签之间的内容。
# 本实例用来爬取百度官网标题——“百度一下,你就知道” import reimport requests'https://www.baidu.com/?tn=78040160_5_pg&ch=8' 'utf-8' )r'<title>(.*?)</title>' , response)0 ])结果如下:
3.1.2 爬取超链接标签间的内容 在 HTML 中, 超链接标题 用于表示超链接。
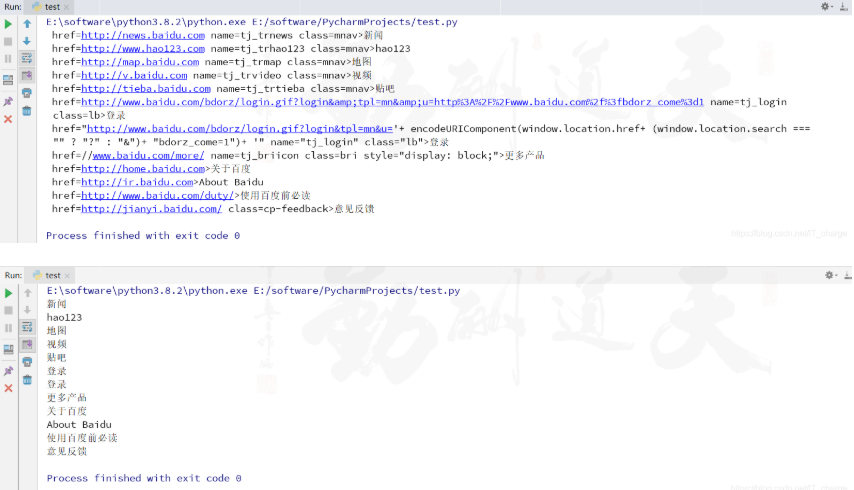
import reimport requests"http://www.baidu.com" 'utf-8' )# 获取完整的超链接 '<a(.*?)</a>' )for u1 in urls1:# 获取超链接<a>和</a>之间的内容 '<a.*?>(.*?)</a>' )for u2 in urls2:结果如下:
3.1.3 爬取re标签和td标签间的内容 网页常用的布局包括 table 布局和 div 布局,其中,table 布局中常见的标签包括tr,th和td,tr(table row)表示表格行为,td(table data)表示表格数据,th(table heading)表示表格表头。
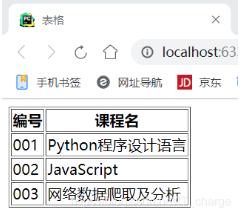
首先假设存在下面这样一个HTML代码。
<!DOCTYPE html>"en" >"UTF-8" >"1" >001 </td><td>Python程序设计语言</td></tr>002 </td><td>JavaScript</td></tr>003 </td><td>网络数据爬取及分析</td></tr> 结果如下:
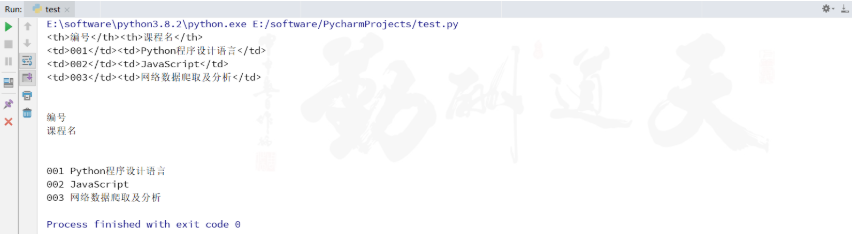
此时,看看怎么使用Python代码获取上述信息呢?
import re# 获取<tr> </tr>之间的内容 "t.html" ,"r" ,encoding="utf-8" ) # 读取文件 # 把文件内容转化为字符串 r'<tr>(.*?)</tr>' , f, re.S|re.M)for tr in trs:# 获取<th> </th>之间的内容 '\n' )for m in trs:r'<th>(.*?)</th>' , m, re.S|re.M)for th in ths:# 获取<td> </td>之间的内容 '\n' )r'<td>(.*?)</td><td>(.*?)</td>' , f, re.S|re.M)for td in tds:0 ], td[1 ])结果如下:
3.2 爬取标签中的参数 3.2.1 爬取超链接标签的URL HTML超链接的基本格式为 “ 链接内容 ”。
import re''' r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')" for url in urls:结果如下:
3.2.2 爬取图片超链接标签的URL 在HTML中,我们可以看到各式各样的图片,其中图片标签的基本格式为 “ <img src = 图片地址/> ” ,只有通过爬取这些图片原地址,才能下载对应的图片至本地。
import re''' '<img .*? src = "(.*?)"/>' 结果如下:
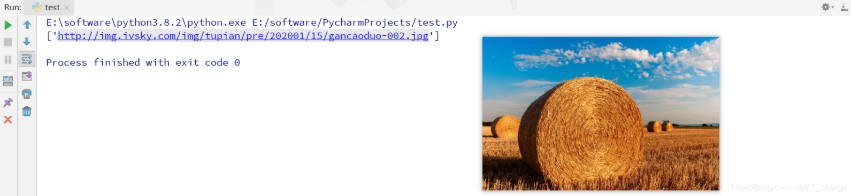
3.2.3 获取URL中的最后一个参数 在使用 Python 爬取图片的过程中,通常会遇到图片对应的 URL 最后一个字段用来对图片命名的情况,如前面的“gancaoduo-002.jpg”,因此就需要通过解析 URL “/” 后面的参数来获取图片名字。
import re''' # res = '<img .*? src = "(.*?)"/>' # urls = re.findall(res, content, re.I|re.S|re.M) # print(urls) 'http://img.ivsky.com/img/tupian/pre/202001/15/gancaoduo-002.jpg' # 采用“/”分隔字符串,进而获取最后一个值 '/' )[-1 ]结果如下:
3.3 字符串处理及替换 当使用正则表达式爬取网页文本时,首先需要调用 find() 函数来找到指定的位置,然后在进行进一步爬取。
# 比如先获取class属性为“infobox”的表格table,然后再进行定位爬取 r'<table class="infobox>' ) # 起点位置 r'</table>' ) # 终点位置 在爬取过程中可能会爬取无关变量,此时需要对无关内容进行过滤,这里推荐使用replace()函数和正则表达式进行处理。
import re''' r'<td>(.*?)</td><td>(.*?)</td>' for text in texts:0 ], text[1 ])结果如下:
此时需要过滤掉多余的字符串,如换行()、空格( )、加粗(),过滤代码如下。
import re''' r'<td>(.*?)</td><td>(.*?)</td>' for text in texts:0 ].replace('<br/>' , "" ).replace(' ' , "" )1 ].replace('<br/>' , "" ).replace(' ' , "" )if '<B>' in value1:r'<B>(.*?)</B>' , value1, re.S|re.M)0 ])else :结果如下:
采用 replace() 函数将字符串 “” 和 “< >” 转换成空白实现过滤,而加粗()则需要使用正则表达式进行过滤 。
4 本文总结 正则表达式通过组合的“规则字符串”对表达式进行过滤,从复杂内容中匹配想要的信息。它的主要对象是文本,适合文本字符串等内容,比如匹配URL、E-mail这种纯文本的字符,但不是和匹配文本意义。各种编程语言都能使用正则表达式,比如C#、Java、Python等。
正则表达式爬虫常用于获取字符串中的某些内容,比如提取博客阅读量和评论数等数字,截取URL中的某个参数,过滤掉特定的字符或检查所获取的数据是否符合某个逻辑,验证URL或日期类型等。由于其具有灵活性、逻辑性和功能性较强的特点,从而能够迅速地以极简单地方式从复杂字符串中匹配到想要的信息。
最后再补充一点,在Python网络数据爬取中,与 re 模块(正则表达式)有同样功能的还有 xpath、BeautifulSoup等。
未完,待续......
如果你觉得本文写得好,可以扫描下方二维码,关注 作者的CSDN博客 ,更多精彩文章抢先看。
关注微信公众号『 数据分析与统计学之美 』,添加作者微信号,拉你入群哦,气氛杠杠的! 看到这里, 麻烦您点个再看 ,让更多朋友看到哦!
喜欢本文点个在看