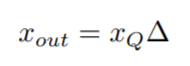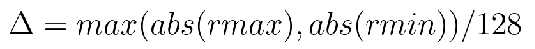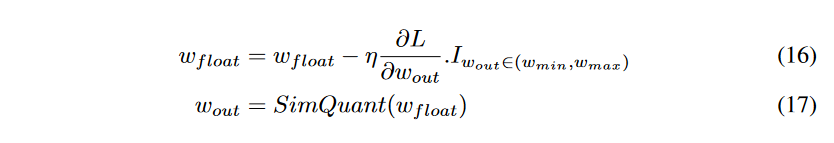1. 前言 深度学习在移动端的应用越来越广泛,而移动端相对于GPU服务来讲算力较低并且存储空间也相对较小。基于这一点我们需要为移动端定制一些深度学习网络来满足我们的日常续需求,例如SqueezeNet,MobileNet,ShuffleNet等轻量级网络就是专为移动端设计的。但除了在网络方面进行改进,模型剪枝和量化应该算是最常用的优化方法了。剪枝就是将训练好的「大模型」 的不重要的通道删除掉,在几乎不影响准确率的条件下对网络进行加速。而量化就是将浮点数(高精度)表示的权重和偏置用低精度整数(常用的有INT8)来近似表示,在量化到低精度之后就可以应用移动平台上的优化技术如NEON对计算过程进行加速,并且原始模型量化后的模型容量也会减少,使其能够更好的应用到移动端环境。但需要注意的问题是,将高精度模型量化到低精度必然会存在一个精度下降的问题,如何获取性能和精度的TradeOff很关键。
这篇文章是介绍使用Pytorch复现这篇论文:https://arxiv.org/abs/1806.08342 的一些细节并给出一些自测实验结果。注意,代码实现的是「Quantization Aware Training」 ,而后量化 「Post Training Quantization」 后面可能会再单独讲一下。代码实现是来自666DZY666博主实现的https://github.com/666DZY666/model-compression。
2. 对称量化 在上次的视频中梁德澎作者已经将这些概念讲得非常清楚了,如果不愿意看文字表述可以移步到这个视频链接下观看视频:深度学习量化技术科普 。然后直接跳到第四节,但为了保证本次故事的完整性,我还是会介绍一下这两种量化方式。
对称量化的量化公式如下:
其中
「有符号的8Bit」 就是
这里有个Trick,即对于权重是量化到
因为8bit的取值区间是[-2^7, 2^7-1],两个8bit相乘之后取值区间是 (-2^14,2^14],累加两次就到了(-2^15,2^15],所以最多只能累加两次而且第二次也有溢出风险,比如相邻两次乘法结果都恰好是2^14会超过2^15-1(int16正数可表示的最大值)。
所以把量化之后的权值限制在(-127,127)之间,那么一次乘法运算得到结果永远会小于-128*-128 = 2^14。
对应的反量化公式为:
即将量化后的值乘以
我们看一下上面橙色线的第
「黑色圆点对应的float32值」 ,将其除以缩放系数就量化为了一个在
「第
,用这个数去代替以前的数继续做网络的Forward。
那么这个缩放系数
3. 非对称量化 非对称量化相比于对称量化就在于多了一个零点偏移。一个float32的浮点数非对称量化到一个int8的整数(如果是有符号就是
然后缩放系数
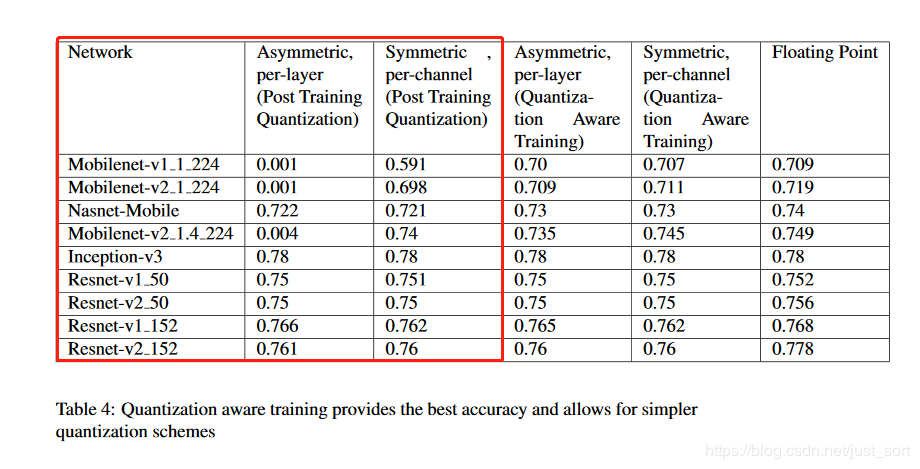
4. 中部小结 将上面两种算法直接应用到各个网络上进行量化后(训练后量化PTQ)测试模型的精度结果如下:
5. 训练模拟量化 我们要在网络训练的过程中模型量化这个过程,然后网络分前向和反向两个阶段,前向阶段的量化就是第二节和第三节的内容。不过需要特别注意的一点是对于缩放因子的计算,权重和激活值的计算方法现在不一样了。
对于权重缩放因子还是和第2,3节的一致,即:
weight scale = max(abs(weight)) / 127
但是对于激活值的缩放因子计算就不再是简单的计算最大值,而是在训练过程中通过滑动平均(EMA)的方式去统计这个量化范围,更新的公式如下:
moving_max = moving_max * momenta + max(abs(activation)) * (1- momenta)
其中,momenta取接近1的数就可以了,在后面的Pytorch实验中取0.99,然后缩放因子:
activation scale = moving_max /128
然后反向传播阶段求梯度的公式如下:
我们在反向传播时求得的梯度是模拟量化之后权值的梯度,用这个梯度去更新量化前的权值。
这部分的代码如下,注意我们这个实验中是用float32来模拟的int8,不具有真实的板端加速效果,只是为了验证算法的可行性:
class Quantizer (nn.Module) :def __init__ (self, bits, range_tracker) :'scale' , None ) # 量化比例因子 'zero_point' , None ) # 量化零点 def update_params (self) :raise NotImplementedError# 量化 def quantize (self, input) :return outputdef round (self, input) :return output# 截断 def clamp (self, input) :return output# 反量化 def dequantize (self, input) :return outputdef forward (self, input) :if self.bits == 32 :elif self.bits == 1 :'!Binary quantization is not supported !' )assert self.bits != 1 else :# 量化 # 截断 # 反量化 return output6. 代码实现 基于https://github.com/666DZY666/model-compression/blob/master/quantization/WqAq/IAO/models/util_wqaq.py 进行实验,这里实现了对称和非对称量化两种方案。需要注意的细节是,对于权值的量化需要分通道进行求取缩放因子,然后对于激活值的量化整体求一个缩放因子,这样效果最好(论文中提到)。
这部分的代码实现如下:
# ********************* range_trackers(范围统计器,统计量化前范围) ********************* class RangeTracker (nn.Module) :def __init__ (self, q_level) :def update_range (self, min_val, max_val) :raise NotImplementedError @torch.no_grad() def forward (self, input) :if self.q_level == 'L' : # A,min_max_shape=(1, 1, 1, 1),layer级 elif self.q_level == 'C' : # W,min_max_shape=(N, 1, 1, 1),channel级 3 , keepdim=True )[0 ], 2 , keepdim=True )[0 ], 1 , keepdim=True )[0 ]3 , keepdim=True )[0 ], 2 , keepdim=True )[0 ], 1 , keepdim=True )[0 ]class GlobalRangeTracker (RangeTracker) :# W,min_max_shape=(N, 1, 1, 1),channel级,取本次和之前相比的min_max —— (N, C, W, H) def __init__ (self, q_level, out_channels) :'min_val' , torch.zeros(out_channels, 1 , 1 , 1 ))'max_val' , torch.zeros(out_channels, 1 , 1 , 1 ))'first_w' , torch.zeros(1 ))def update_range (self, min_val, max_val) :if self.first_w == 0 :1 )else :class AveragedRangeTracker (RangeTracker) :# A,min_max_shape=(1, 1, 1, 1),layer级,取running_min_max —— (N, C, W, H) def __init__ (self, q_level, momentum=0.1 ) :'min_val' , torch.zeros(1 ))'max_val' , torch.zeros(1 ))'first_a' , torch.zeros(1 ))def update_range (self, min_val, max_val) :if self.first_a == 0 :1 )else :1 - self.momentum).add_(min_val * self.momentum)1 - self.momentum).add_(max_val * self.momentum)其中self.register_buffer这行代码可以在内存中定一个常量,同时,模型保存和加载的时候可以写入和读出,即这个变量不会参与反向传播。
❝
pytorch一般情况下,是将网络中的参数保存成orderedDict形式的,这里的参数其实包含两种,一种是模型中各种module含的参数,即nn.Parameter,我们当然可以在网络中定义其他的nn.Parameter参数,另一种就是buffer,前者每次optim.step会得到更新,而不会更新后者。
❞
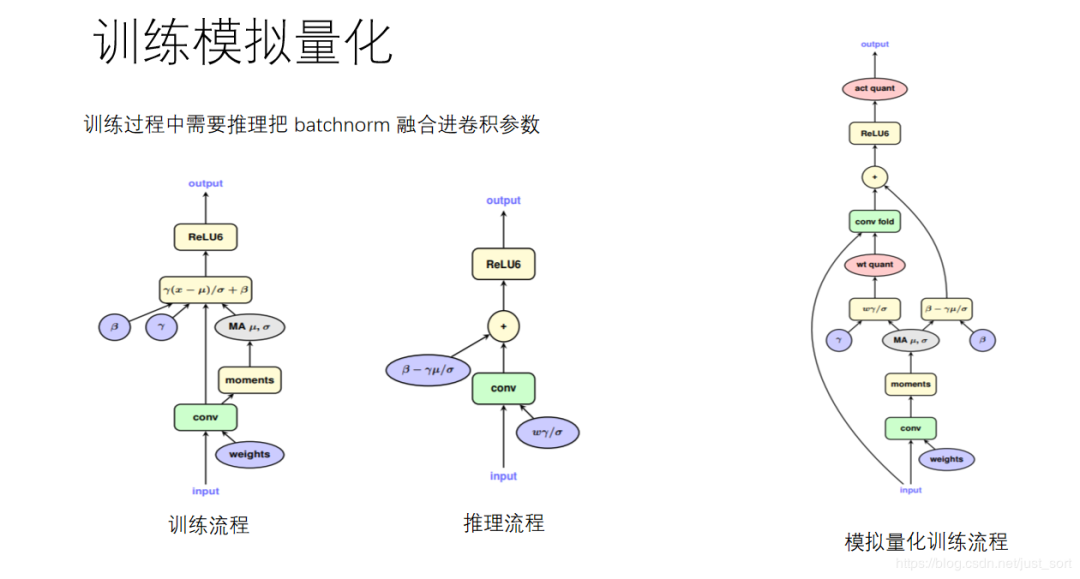
另外,由于卷积层后面经常会接一个BN层,并且在前向推理时为了加速经常把BN层的参数融合到卷积层的参数中,所以训练模拟量化也要按照这个流程。即,我们首先需要把BN层的参数和卷积层的参数融合,然后再对这个参数做量化,具体过程可以借用德澎的这页PPT来说明:
因此,代码实现包含两个版本,一个是不融合BN的训练模拟量化,一个是融合BN的训练模拟量化,而关于为什么融合之后是上图这样的呢?请看下面的公式:
所以:
公式中的,
未融合BN的训练模拟量化代码实现如下(带注释):
# ********************* 量化卷积(同时量化A/W,并做卷积) ********************* class Conv2d_Q (nn.Conv2d) :def __init__ (1 ,0 ,1 ,1 ,8 ,8 ,1 ,0 , :# 实例化量化器(A-layer级,W-channel级) if q_type == 0 :'L' ))'C' , out_channels=out_channels))else :'L' ))'C' , out_channels=out_channels))def forward (self, input) :# 量化A和W if not self.first_layer:# 量化卷积 return output而考虑了折叠BN的代码实现如下(带注释):
def reshape_to_activation (input) :return input.reshape(1 , -1 , 1 , 1 )def reshape_to_weight (input) :return input.reshape(-1 , 1 , 1 , 1 )def reshape_to_bias (input) :return input.reshape(-1 )# ********************* bn融合_量化卷积(bn融合后,同时量化A/W,并做卷积) ********************* class BNFold_Conv2d_Q (Conv2d_Q) :def __init__ (1 ,0 ,1 ,1 ,1e-5 ,0.01 , # 考虑量化带来的抖动影响,对momentum进行调整(0.1 ——> 0.01 ) ,削弱batch统计参数占比,一定程度抑制抖动。经实验量化训练效果更好,acc提升1 %左右8 ,8 ,1 ,0 , :'running_mean' , torch.zeros(out_channels))'running_var' , torch.ones(out_channels))'first_bn' , torch.zeros(1 ))# 实例化量化器(A-layer级,W-channel级) if q_type == 0 :'L' ))'C' , out_channels=out_channels))else :'L' ))'C' , out_channels=out_channels))def forward (self, input) :# 训练态 if self.training:# 先做普通卷积得到A,以取得BN参数 # 更新BN统计参数(batch和running) for dim in range(4 ) if dim != 1 ]with torch.no_grad():if self.first_bn == 0 :1 )else :1 - self.momentum).add_(batch_mean * self.momentum)1 - self.momentum).add_(batch_var * self.momentum)# BN融合 if self.bias is not None : else :# b融batch # w融running # 测试态 else :#print(self.running_mean, self.running_var) # BN融合 if self.bias is not None :else :# b融running # w融running # 量化A和bn融合后的W if not self.first_layer:# 量化卷积 if self.training: # 训练态 # 注意,这里不加bias(self.bias为None) # (这里将训练态下,卷积中w融合running参数的效果转为融合batch参数的效果)running ——> batch else : # 测试态 # 注意,这里加bias,做完整的conv+bn return output注意一个点,在训练的时候bias设置为None,即训练的时候不量化bias。
7. 实验结果 在CIFAR10做Quantization Aware Training实验,网络结构为:
import torchimport torch.nn as nnimport torch.nn.functional as Ffrom .util_wqaq import Conv2d_Q, BNFold_Conv2d_Qclass QuanConv2d (nn.Module) :def __init__ (self, input_channels, output_channels,-1 , stride=-1 , padding=-1 , groups=1 , last_relu=0 , abits=8 , wbits=8 , bn_fold=0 , q_type=1 , first_layer=0 ) :if self.bn_fold == 1 :else :0.01 ) # 考虑量化带来的抖动影响,对momentum进行调整(0.1 ——> 0.01),削弱batch统计参数占比,一定程度抑制抖动。经实验量化训练效果更好,acc提升1%左右 True )def forward (self, x) :if not self.first_layer:if self.bn_fold == 1 :else :if self.last_relu:return xclass Net (nn.Module) :def __init__ (self, cfg = None, abits=8 , wbits=8 , bn_fold=0 , q_type=1 ) :if cfg is None :192 , 160 , 96 , 192 , 192 , 192 , 192 , 192 ]# model - A/W全量化(除输入、输出外) 3 , cfg[0 ], kernel_size=5 , stride=1 , padding=2 , abits=abits, wbits=wbits, bn_fold=bn_fold, q_type=q_type, first_layer=1 ),0 ], cfg[1 ], kernel_size=1 , stride=1 , padding=0 , abits=abits, wbits=wbits, bn_fold=bn_fold, q_type=q_type),1 ], cfg[2 ], kernel_size=1 , stride=1 , padding=0 , abits=abits, wbits=wbits, bn_fold=bn_fold, q_type=q_type),3 , stride=2 , padding=1 ),2 ], cfg[3 ], kernel_size=5 , stride=1 , padding=2 , abits=abits, wbits=wbits, bn_fold=bn_fold, q_type=q_type),3 ], cfg[4 ], kernel_size=1 , stride=1 , padding=0 , abits=abits, wbits=wbits, bn_fold=bn_fold, q_type=q_type),4 ], cfg[5 ], kernel_size=1 , stride=1 , padding=0 , abits=abits, wbits=wbits, bn_fold=bn_fold, q_type=q_type),3 , stride=2 , padding=1 ),5 ], cfg[6 ], kernel_size=3 , stride=1 , padding=1 , abits=abits, wbits=wbits, bn_fold=bn_fold, q_type=q_type),6 ], cfg[7 ], kernel_size=1 , stride=1 , padding=0 , abits=abits, wbits=wbits, bn_fold=bn_fold, q_type=q_type),7 ], 10 , kernel_size=1 , stride=1 , padding=0 , last_relu=1 , abits=abits, wbits=wbits, bn_fold=bn_fold, q_type=q_type),8 , stride=1 , padding=0 ),def forward (self, x) :0 ), -1 )return x训练Epoch数为30,学习率调整策略为:
def adjust_learning_rate (optimizer, epoch) :if args.bn_fold == 1 :if args.model_type == 0 :12 , 15 , 25 ]else :8 , 12 , 20 , 25 ]else :15 , 17 , 20 ]if epoch in update_list:for param_group in optimizer.param_groups:'lr' ] = param_group['lr' ] * 0.1 return
类型
Acc
备注
原模型(nin)
91.01%
全精度
对称量化, bn不融合
88.88%
INT8
对称量化,bn融合
86.66%
INT8
非对称量化,bn不融合
88.89%
INT8
非对称量化,bn融合
87.30%
INT8
现在不清楚为什么量化后的精度损失了1-2个点,根据德澎在MxNet的实验结果来看,分类任务不会损失精度,所以不知道这个代码是否存在问题,有经验的大佬欢迎来指出问题。
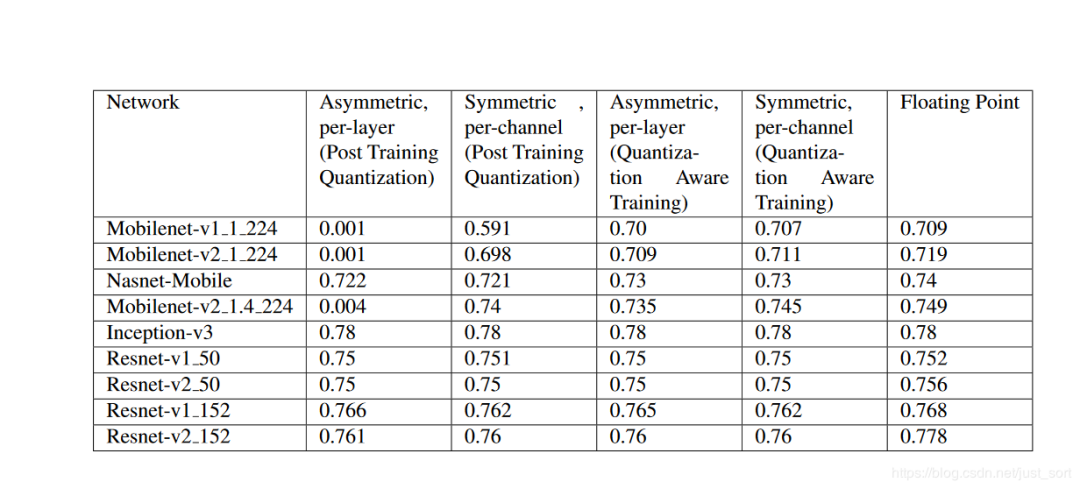
然后白皮书上提供的一些分类网络的训练模拟量化精度情况如下:
注意前面有一些精度几乎为0的数据是因为MobileNet训练出来之后某些层的权重非常接近0,使用训练后量化方法之后权重也为0,这就导致推理后结果完全错误。
8. 总结 今天介绍了一下基于Pytorch实现QAT量化,并用一个小网络测试了一下效果,但比较遗憾的是并没有获得论文中那么理想的数据,仍需要进一步研究。
福利时间:
本次联合【机械工业出版社华章公司】为大家带来3本正版新书。在下方留言板 留言,7月30日0点前,BBuf会从留言区挑选三名公众号常读用户分别送出一本书籍。没中奖的读者也可以扫描下方海报的二维码购买。
戳这里留言
今天京东购书5折优惠,这本书原价89元,今天扫描下方海报的二维码购买,只要44.05元。非常划算。无论你是想要入门OpenCV的学生或初学者,还是想要进阶提升技术水平的算法工程师或图像视频开发人员,都推荐你购买阅读。
推荐阅读:
Intel与阿里巴巴高级图形图像专家联合撰写!深入解析OpenCV DNN 模块、基于GPU/CPU的加速实现、性能优化技巧与可视化工具,以及人脸活体检测等应用,涵盖Intel推理引擎加速等鲜见一手深度信息。知名专家傅文庆、邹复好、Vadim Pisarevsky、周强(CV君)联袂推荐!
点击“阅读原文”,查看更多五折AI好书!
原文链接:https://pro.m.jd.com/mall/active/3SMUsbc3hV2BagYYJ3zkbMs9HaVQ/index.html?utm_source=iosapp&utm_medium=appshare&utm_campaign=t_335139774&utm_term=Wxfriends&ad_od=share
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:
为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。