为什么要学习数据结构?
随着业务场景越来越复杂,系统并发量越来也高,要处理的数据越来越多,特别是大型互联网的高并发、高性能、高可用系统,对技术要求越来越高,我们引入各种中间件,这些中间件底层涉及到的各种数据结构和算法,是其核心技术之一。如:
ElasticSearch中用于压缩倒排索引内存存储空间的FST,用于查询条件合并的SkipList,用于提高范围查找效率的BKDTree;
各种分库分表技术的核心:hash算法;
Dubbo或者Nginx等的负载均衡算法;
MySQL索引中的B树、B+树等;
Redis使用跳跃表作为有序集合键的底层实现之一;
Zookeeper的节点树;
J.U.C并发包的各种实现的阻塞队列,AQS底层实现涉及到的链式等待队列;
JDK对HashMap的Hash冲突引入的优化数据结构红黑树…
可以发现,数据结构和算法真的是无处不在,作为一个热爱技术,拒绝粘贴复制的互联网工程师,怎么能不掌握这些核心技术呢?
与此同时,如果你有耐心听8个小时通俗易懂的数据结构入门课,我强烈建议你看一下以下这个视频,来自一位热衷于分享的Google 工程师:https://www.youtube.com/watch?v=RBSGKlAvoiM
阅读完本文,你将了解到一些常见的数据结构(或者温习,因为大部分朋友大学里面其实都是学过的)。在每个数据结构最后一小节都会列出代码实现,以及相关热门的算法题,该部分需要大家自己去探索与书写。只有自己能熟练的编写各种数据结构的代码才是真正的掌握了,大家别光看,动手写起来。阅读完本文,您将了解到:
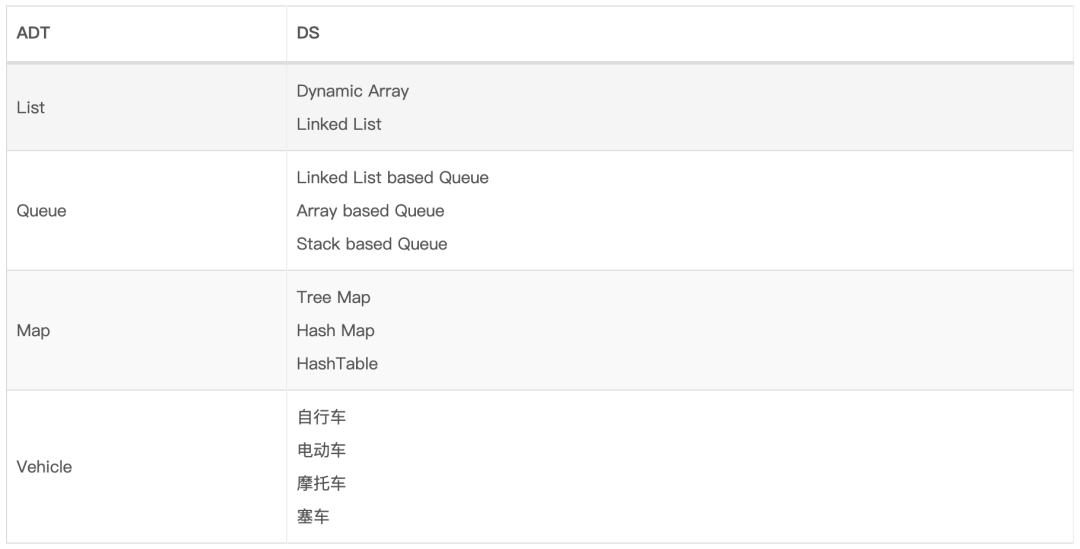
1、抽象数据类型 抽象数据类型 (ADT abstract data type):是数据结构 的抽象,它仅提供数据结构必须遵循的接口。接口并未提供有关应如何实现某种内容或以哪种编程语言的任何特定详细信息。
下标列举了抽象数据类型和数据结构之间的构成关系:
2、时间与空间复杂度 我们一般会关注程序的两个问题:
有时候时间复杂度和空间复杂度二者不能兼得,我们只能从中取一个平衡点。
下面我们通过Big O表示法来描述算法的复杂度。
2.1、时间复杂度 2.1.1、Big-O Big-O表示法给出了算法计算复杂性的上限。
T(n) = O(f(n)),该公式又称为算法的渐进时间复杂度,其中f(n)函数表示每行代码执行次数之和,O表示执行时间与之形成正比例关系。
常见的时间复杂度量级,从上到下时间复杂度越来越大,执行效率越来越低:
常数阶 Constant Time: O(1)
对数阶 Logarithmic Time: O(log(n))
线性阶 Linear Time: O(n)
线性对数阶 Linearithmic Time: O(nlog(n))
平方阶 Quadratic Time: O(n^2)
立方阶 Cubic Time: O(n^3)
n次方阶 Exponential Time: O(b^n), b > 1
指数阶 Factorial Time: O(n!)
下面是我从 Big O Cheat Sheet[1] 引用过来的一张表示各种度量级的时间复杂度图表:
2.1.2、如何得出Big-O 所谓Big-O表示法,就是要得出对程序影响最大的那个因素,用于衡量复杂度,举例说明:
O(n + c) => O(n),常量可以忽略;
O(cn) => O(n), c > 0,常量可以忽略;
2log(n)3 + 3n2 + 4n3 + 5 => O(n3),取对程序影响最大的因素。
练习 :请看看下面代码的时间复杂度:
image-20200411175500608
答案依次为:O(1), O(n), O(log(n)), O(nlog(n)), O(n^2)
第三个如何得出对数?假设循环x次之后退出循环,也就是说 2^x = n,那么 x = log2(n),得出O(log(n))
2.2、空间复杂度 空间复杂度是对一个算法在运行过程中占用存储空间的大小的衡量。
O(1):存储空间不随变量n的大小而变化;
O(n):如:new int[n];
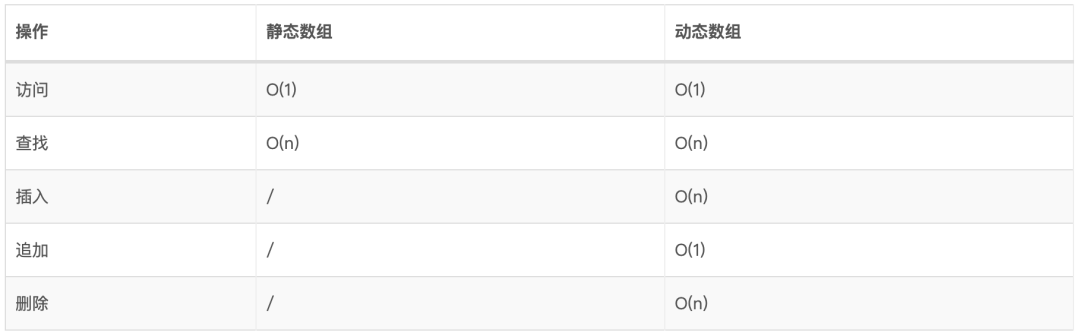
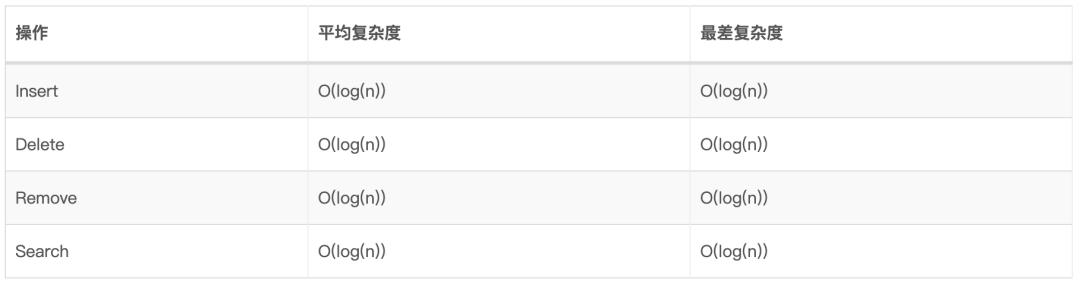
2.3、常用数据结构复杂度 一些常用的数据结构的复杂度(注:以下表格图片来源于 Big O Cheat Sheet[1] ):
2.4、常用排序算法复杂度 (注:以下表格图片来源于 Big O Cheat Sheet[1] )
关于复杂度符号
O:表示渐近上限,即最差时间复杂度;
Θ:表示渐近紧边界,即平均时间复杂度;
Ω:表示渐近下界,即最好时间复杂度;
3、静态数组和动态数组 3.1、静态数组 静态数组是固定长度的容器,其中包含n个可从[0,n-1]范围索引的元素。
问:“可索引”是什么意思?
答:这意味着数组中的每个插槽/索引都可以用数字引用。
3.1.1、使用场景
1)存储和访问顺序数据
2)临时存储对象
3)由IO例程用作缓冲区
4)查找表和反向查找表
5)可用于从函数返回多个值
6)用于动态编程中以缓存子问题的答案
3.1.2、静态数组特点
只能由数组下标访问数组元素,没有其他的方式了;
第一个下标为0;
下标超过范围了会触发数组越界错误。
3.2、动态数组 动态数组的大小可以增加和缩小。
3.2.1、如何实现一个动态数组 使用一个静态数组:
3.3、时间复杂度
3.4、编程实践
JDK中的实现:java.util.ArrayList
练习:
两数之和:https://leetcode-cn.com/problems/two-sum/
删除排序数组中的重复项:https://leetcode-cn.com/problems/remove-duplicates-from-sorted-array/
杨辉三角:https://leetcode-cn.com/problems/pascals-triangle/
最大子序和:https://leetcode-cn.com/problems/maximum-subarray/
旋转数组:https://leetcode-cn.com/problems/rotate-array/
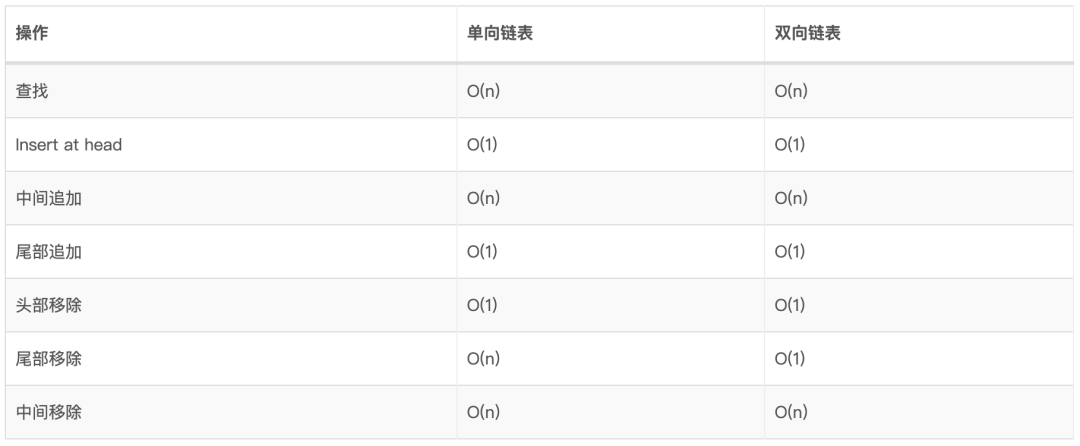
4、链表 4.1、使用场景 4.2、术语 Head:链表中的第一个节点;
Tail:链表中的最后一个节点;
Pointer:指向下一个节点;
Node:一个对象,包含数据和Pointer。
4.3、实现思路 这里使用双向链表作为例子进行说明。
4.3.1、插入节点 往第三个节点插入:x
从链表头遍历,直到第三个节点,然后执行如下插入操作:
遍历到节点位置,把新节点指向前后继节点:
后继节点回溯连接到新节点,并移除旧的回溯关系:
前继节点遍历连接到新节点,并移除旧的遍历关系:
完成:
注意指针处理顺序,避免在添加过程中导致遍历出现异常。
4.3.2、删除节点 删除c节点:
从链表头遍历,直到找到c节点,然后把c节点的前继节点连接到c的后继接节点:
把c节点的后继节点连接到c的前继节点:
移除多余指向关系以及c节点:
完成:
同样的,注意指针处理顺序,避免在添加过程中导致遍历出现异常。
4.4、时间复杂度
4.5、编程实践
JDK中的实现:java.util.LinkedList
练习:
反转链表:https://leetcode-cn.com/problems/reverse-linked-list/
回文链表:https://leetcode-cn.com/problems/palindrome-linked-list
两数相加:https://leetcode-cn.com/problems/add-two-numbers
复制带随机指针的链表:https://leetcode-cn.com/problems/copy-list-with-random-pointer
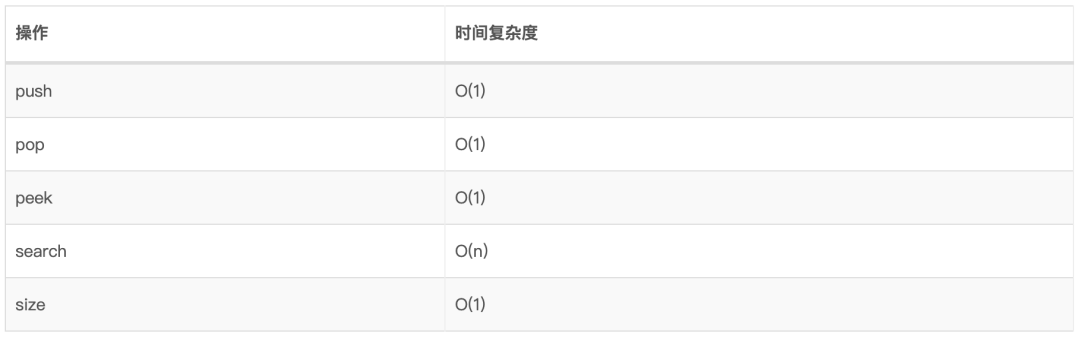
5、栈 堆栈是一种单端线性数据结构,它通过执行两个主要操作(即推入push和弹出pop)来对现实世界的堆栈进行建模。
5.1、使用场景
文本编辑器中的撤消机制;
用于编译器语法检查中是否匹配括号和花括号;
建模一堆书或一叠盘子;
在后台使用,通过跟踪以前的函数调用来支持递归;
可用于在图上进行深度优先搜索(DFS)。
5.2、编程实战 5.2.1、语法校验 给定一个由以下括号组成的字符串:()[] {},确定括号是否正确匹配。
例如:({}{}) 匹配,{()(]} 不匹配。
思路:
凡是遇到( { [ 都进行push入栈操作,遇到 ) } ] 则pop栈中的元素,看看是否与当前处理的元素匹配:
匹配完成之后,栈必须是空的。
5.3、复杂度
5.4、编程实践
基于数组的实现:java.util.Stack
基于链表的实现:stackhttps://github.com/arthinking/java-tech-stack-resource/blob/master/src/main/java/com/itzhai/algorithm/datastructures/stack/Stack.java
练习:
最小栈:https://leetcode-cn.com/problems/min-stack
有效的括号:https://leetcode-cn.com/problems/valid-parentheses
搜索旋转排序数组:https://leetcode-cn.com/problems/search-in-rotated-sorted-array
接雨水:https://leetcode-cn.com/problems/trapping-rain-water
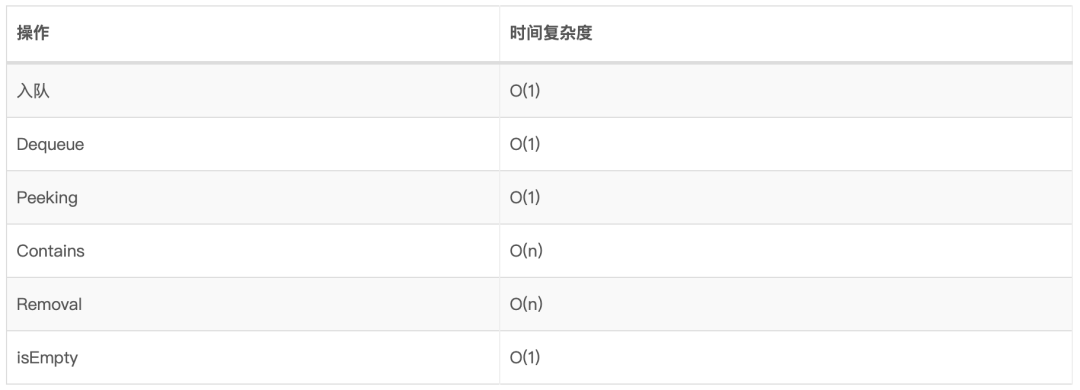
6、队列 队列是一种线性数据结构,它通过执行两个主要操作(即入队enqueue和出队dequeue)来对现实世界中的队列进行建模。
6.1、术语
队列底层可以使用数组或者链表实现
6.2、使用场景 6.2.1、请用队列实现图的广度优先遍历 提示:
遍历顺序:0 -> 2, 5 -> 6 -> 1 -> 9, 3, 2, 7 -> 3, 4, 8, 9
6.3、时间复杂度
6.4、编程实践
基于数组实现的Queue:ArrayQueuehttps://github.com/arthinking/java-tech-stack-resource/blob/master/src/main/java/com/itzhai/algorithm/datastructures/queue/ArrayQueue.java
基于链表实现的Queue:LinkedListQueuehttps://github.com/arthinking/java-tech-stack-resource/blob/master/src/main/java/com/itzhai/algorithm/datastructures/queue/LinkedListQueue.java
练习:
设计循环队列:https://leetcode-cn.com/problems/design-circular-queue/
用队列实现栈:https://leetcode-cn.com/problems/implement-stack-using-queues
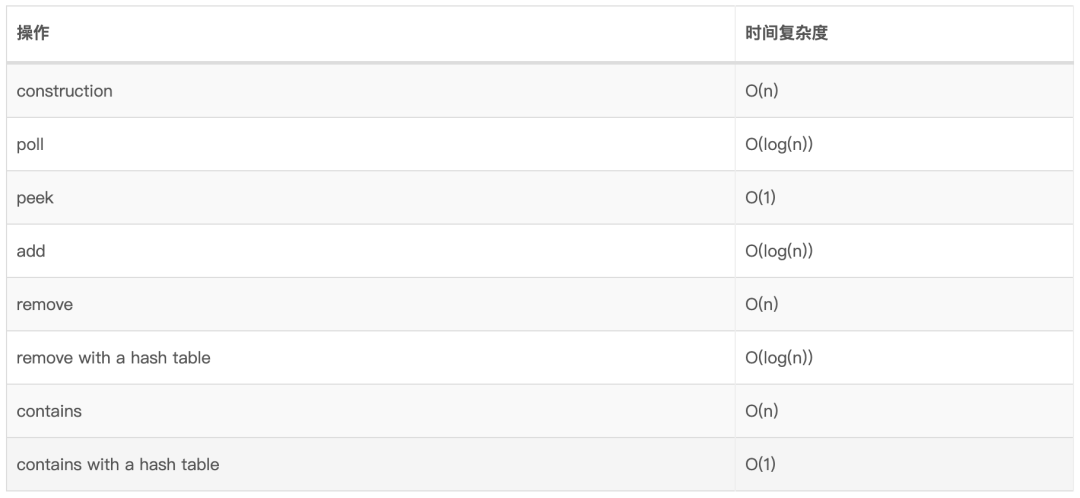
7、优先级队列PQ 优先级队列是一种抽象数据类型(ADT),其操作类似于普通队列,不同之处在于每个元素都具有特定的优先级。优先级队列中元素的优先级决定了从PQ中删除元素的顺序。
注意:优先级队列仅支持可比较的数据 ,这意味着插入优先级队列的数据必须能够以某种方式(从最小到最大或从最大到最小)进行排序。这样我们就可以为每个元素分配相对优先级。
为了实现优先级队列,我们必须使用到堆 Heap。
7.1、什么是堆 堆是基于树的非线性结构DS,它满足堆不变式:
二叉堆是一种弄特殊的堆,其满足:
将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
在同级兄弟或表亲之间没有隐含的顺序,对于有序遍历也没有隐含的顺序。
堆通常使用隐式堆 数据结构实现,隐式堆数据结构是由数组 (固定大小或动态数组)组成的隐式数据结构,其中每个元素代表一个树节点,其父/子关系由其索引隐式定义。将元素插入堆中或从堆中删除后,可能会违反堆属性,并且必须通过交换数组中的元素来平衡堆。
7.2、使用场景 7.3、最小堆转最大堆 问题 :大多数编程语言的标准库通常只提供一个最小堆,但有时我们需要一个最大PQ。
解决方法 :
7.4、实现思路 优先级队列通常使用堆来实现,因为这使它们具有最佳的时间复杂性。
优先级队列是抽象数据类型,因此,堆并不是实现PQ的唯一方法 。例如,我们可以使用未排序的列表,但这不会给我们带来最佳的时间复杂度,以下数据结构都可以实现优先级队列:
这里我们选取二叉堆来实现,二叉堆是一颗完全二叉树[2] 。
7.4.1、二叉堆排序映射到数组中 二叉堆索引与数组一一对应:
二叉堆排好序之后,即按照索引填充到数组中:
索引规则:
i节点左叶子节点:2i + 1
i节点右叶子节点:2i + 2
7.4.2、添加元素到二叉堆 insert(0)
如下图,首先追加到最后一个节点,然后一层一层的跟父节点比较,如果比父节点小,则与父节点交换位置。
7.4.3、从二叉堆移除元素 poll() 移除第一个元素
第一个元素与最后一个元素交换位置,然后删除掉最后一个元素;
第一个元素尝试sink 下沉操作 :一直与子节点对比,如果大于任何一个子节点,则与该子节点对换位置;
remove(7) 移除特定的元素
依次遍历数组,找到值为7的元素,让该元素与最后一个元素对换,然后删除掉最后一个元素;
思考:请问如何构造一个小顶堆呢?
遍历数组,所有元素依次与子节点对比,如果大于子节点则交换。
7.5、尝试让删除操作时间复杂度变为O(log(n)) 以上删除算法的效率低下是由于我们必须执行线性搜索O(n) 以找出元素的索引位置。
我们可以尝试使用哈希表进行查找以找出节点的索引位置。 如果同一个值在多个位置出现,那么我们可以维护一个特定节点值映射到的索引的Set或者Tree Set中。
数据结构如下:
这样我们在删除的时候就可以通过HashTable定位到具体的元素了。
7.6、时间复杂度
7.7、编程实践
JDK中的实现:java.util.PriorityQueue
基于最小堆实现的优先级队列 BinaryHeap:https://github.com/arthinking/java-tech-stack-resource/blob/master/src/main/java/com/itzhai/algorithm/datastructures/priorityqueue/BinaryHeap.java
最小堆实现的优先级队列,优化了删除方法:https://github.com/arthinking/java-tech-stack-resource/blob/master/src/main/java/com/itzhai/algorithm/datastructures/priorityqueue/BinaryHeapQuickRemovals.java
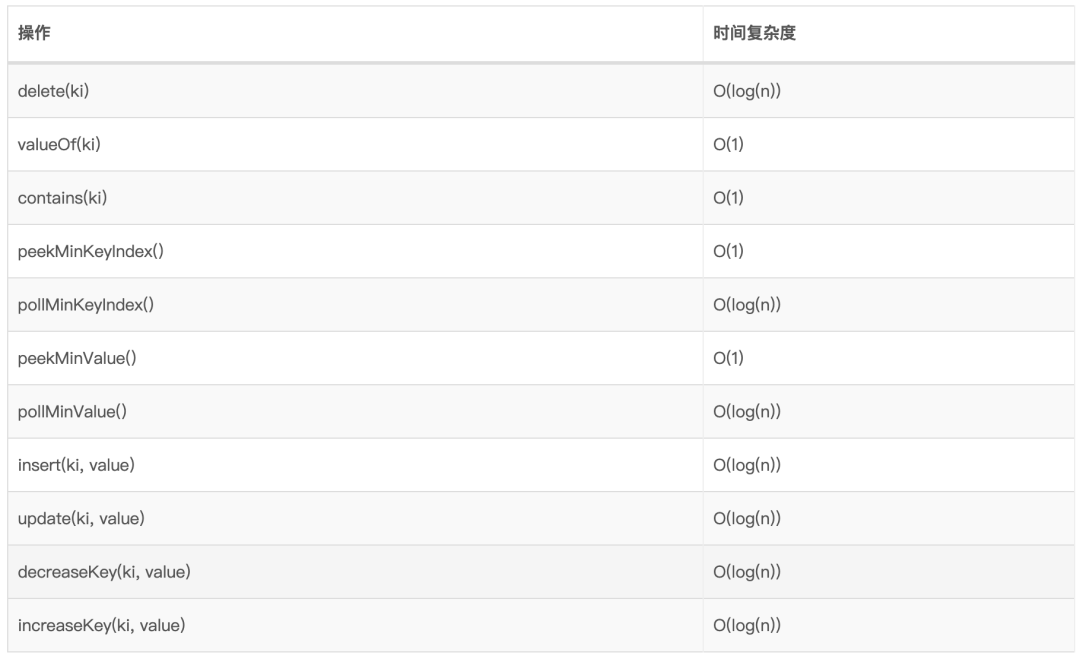
8、索引式优先队列 IPQ 索引优先级队列(Indexed Priority Queue IPQ)是传统的优先级队列变体,除了常规的PQ操作之外,它还提供了索引用于支持键值对的快速更新和删除。
我们知道前面的优先级队列的元素都是存放到一个list里面的,我们想知道知道某一个值在优先级队列中的位置,也是需要遍历一个个对比才知道的,要是有重复的值,那就区分不了了。既然找不到元素,那么对元素的更新和删除也就无从说起了。
为此,我们引入了如下两个索引:节点索引ki和位置索引im:
如:
与构造或更新删除PQ不同的是,IPQ需要额外维护这些索引的关系。
8.1、时间复杂度
8.2、编程实践 9、二叉树与二叉搜索树BST 二叉树(Binary Tree) 是每个节点最多具有两个子节点的树;
二叉搜索树(Binary Search Tree) 是满足以下条件二叉树:左子树的元素较小,右子树的元素较大。
9.1、使用场景
某些map和set的ADT的实现;
红黑树;
AVL树;
伸展树(Splay Tree 分裂树);
用于二叉堆的实现;
语法树;
Treap-概率DS(使用随机BST)
9.2、实现思路 9.2.1、插入元素 极端场景:
这种情况就变为了线性结构,比较糟糕,这就是平衡二叉搜索树出现的原因。
9.2.2、移除元素 移除元素可以分为两步:
移除会有以下三种情况:
9.2.2.1、移除的元素是一个叶子节点 找到对应待移除的节点,直接删除掉即可:
remove(16):
9.2.2.2、移除的元素下面有左子树或者右子树 如果移除的元素下面带有左子树或者右子树,那么:找到对应待移除的节点,用子树的根节点作为移除元素的后继者,替换掉需要移除的元素即可:
9.2.2.3、移除的元素下面有左子树和右子树 如果移除的元素下面带有左子树和右子树,那么应该用左子树还是右子树中的节点作为删除元素的后继者呢?
答案是两者都可以!后继者可以是左侧子树中的最大值,也可以是右侧子树中的最小值。
下面我们执行remove(8),统一选择使用右子树中的最小值。
具体步骤:
查找到需要删除的元素;
在其右子树中寻找到最小值的节点;
最小值的节点和待删除元素的值互换;
使用9.2.2.2的步骤删除掉原来最小值节点位置的节点;
9.2.3、查找元素 BST搜索元素会出现以下四种情况之一:
以下是find(6)操作:
9.3、树的遍历 可以分为深度优先遍历和广度优先遍历。而深度优先遍历又分为:前序遍历、中序遍历、后序遍历、层序遍历。
9.3.1、深度优先遍历 深度优先遍历都是通过递归来实现的,对应的数据结构为栈。
9.3.1.1、前序遍历 在递归方法最开始处理节点信息,代码逻辑:
1 void preOrder (node) 2 if (node == null ) return ;3 print(node.value);4 preOrder(node.left);5 preOrder(node.right);6 }如下二叉树将得出以下遍历结果:A B D H I E J C F K G
9.3.1.2、中序遍历 在递归调用完左子节点,准备右子节点之前处理节点信息,代码逻辑:
1 void inOrder (node) 2 if (node == null ) return ;3 inOrder(node.left);4 print(node.value);5 inOrder(node.right);6 }
二叉搜索树使用中序遍历,会得到一个排好序的列表。
以下二叉搜索树将得出如下遍历结果:1 3 4 5 6 7 8 15 16 20 21
9.3.1.3、后序遍历 在递归完左右子树之后,再处理节点信息,代码逻辑:
1 void postOrder (node) 2 if (node == null ) return ;3 postOrder(node.left);4 postOrder(node.right);5 print(node.value);6 }以下二叉树得出如下遍历结果:1 4 3 6 7 5 16 15 21 20 8
9.3.2、广度优先遍历 在广度遍历中,我们希望一层一层的处理节点信息,常用的数据结构为队列。每处理一个节点,同时把左右子节点放入队列,然后从队列中取节点进行处理,处理的同时把左右子节点放入队列,反复如此,直至处理完毕。
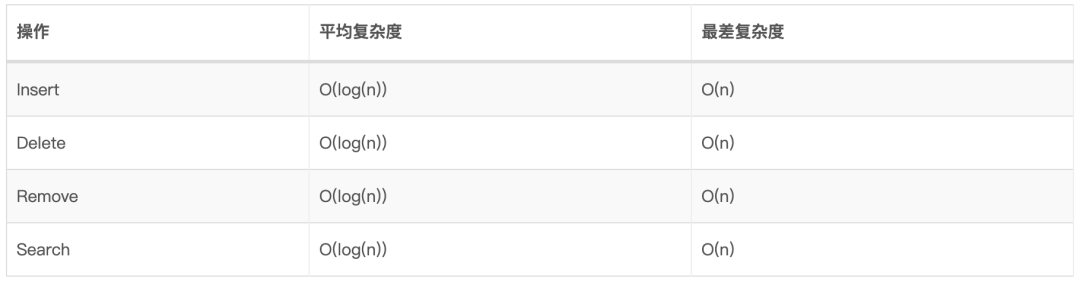
9.4、BST时间复杂度
9.5、编程实践 10、平衡二叉搜索树BBST 平衡二叉搜索树(Balanced Binary Search Tree BBST)是一种自平衡的二叉搜索树。所以自平衡意味着会自行调整,以保持较低(对数)的高度,从而允许更快的操作,例如插入和删除。
10.1、树旋转 大多数BBST算法核心组成部分是:树不变式和树旋转的巧妙用法。
树不变式 :是在每次操作后必须满足的属性/规则。为了确保始终满足不变式,通常会应用一系列树旋转 。
在树旋转的过程中需要确保保持BST的不变式:左子树比较小,右子树比较大。
10.1.1、更新单向指针的BBST 为此,我们可以使用以下操作实现右旋转,注意观察宣传前后,BST的不变式:
1 public void rightRotate (Node a) 2 Node b = a.left;3 a.left = b.right;4 b.right = a;5 return b;6 }如下图,我们准备执行rightRotate(a):
为什么可以这样变换呢?
还是那个原则:BST不变式 。
所有BBST都是BST,因此对于每个节点n,都有:n.left <n && n < n.right。(这里的前提是没有重复元素)
我们在变换操作的时候只要确保这个条件成立即可,即保持BST不变性成立的前提下,我们可以对树中的值和节点进行随机变换/旋转。
注意,如上图,如果a节点还有父节点p,那么就把p节点原来指向a节点变更为指向b节点。
10.1.2、更新双向指针的BBST 在某些需要经常方位父节点或者同级节点的BBST中,我们就不是像上面那样最多更新3个指针,而是必须更新6个指针了,操作会复制些许。
以下是代码实现:
1 public void rightRotate (Node a) 2 Node p = a.parent 3 Node b = a.left; 4 a.left = b.right; 5 if (b.right != null ) { 6 b.right.parent = a; 7 } 8 b.right = a; 9 a.parent = b;10 b.parent = p;11 // 更新父指针 12 if (p != null ) {13 if (p.left == a) {14 p.left = b;15 } else {16 p.right = b;17 }18 }19 return b;20 }
BBST通过在不满足其不变性时执行一系列左/右树旋转来保持平衡。
10.2、AVL树 AVL树 是平衡二叉搜索树的一种,它允许以O(log(n))的复杂度进行插入、搜索和删除操作。
AVL树是第一种被发现的BBST,后来出现了其他类型包括:2-3 tree、AA tree、scapegoat tree(替罪羊树)、red-black tree(红黑树)。
使AVL树保持平衡的属性称为平衡因子 (balanced factor BF)。
BF(node) = H(node.right) - H(node.left)
其中H(x)是节点的高度,为x和最远的叶子之间的边数
AVL树中使其保持平衡的不变形是要求平衡因子BF始终为-1、0或者1。
10.2.1、节点存储信息
节点存储的实际值,此值必须可以比较;
BF的值;
节点在树中的高度;
指向左右子节点的指针。
10.2.2、AVL的自平衡 当节点的BF不为-1、0或者1的时候,使用树旋转来进行调整。可以分为几种情况:
左左
左右
image-20200425154944462
右右
右左
10.3、从BBST中移除元素 参考BST小节的删除逻辑,与之不同的是,在删除元素之后,需要执行多一个自平衡的过程。
10.4、时间复杂度 普通二叉搜索树:
平衡二叉搜索树:
10.5、编程实践 11、HashTable 11.1、什么是HashTable HashTable,哈希表,是一种数据结构,可以通过使用称为hash的技术提供从键到值的映射。
key :其中key必须是唯一的,key必须是可以hash;
value :value可以重复,value可以是任何类型;
HashTable经常用于根据Key统计数量,如key为服务id,value为错误次数等。
11.2、什么是Hash函数 哈希函数 H(x) 是将键“ x”映射到固定范围内的整数的函数。
我们可以为任意对象(如字符串,列表,元组等)定义哈希函数。
11.2.1、Hash函数的特点 如果 H(x) = H(y) ,那么x和y可能相当,但是如果 H(x) ≠ H(y),那么x和y一定不相等。
Q:我们如何提高对象的比较效率呢?
A:可以比较他们的哈希值,只有hash值匹配时,才需要显示比较两个对象。
Q:两个大文件,如何判断是否内容相同?
A:类似的,我们可以预先计算H(file1)和H(file2),比较哈希值,此时时间复杂度是O(1),如果相等,我们才考虑进一步比较稳健。(稳健的哈希函数比哈希表使用的哈希函数会更加复杂,对于文件,通常使用加密哈希函数,也称为checksums)。
哈希函数 H(x) 必须是确定的
就是说,如果H(x) = y,那么H(x)必须始终能够得到y,而不产生另一个值。这对哈希函数的功能至关重要。
我们需要严谨的使用统一的哈希函数,最小化哈希冲突的次数
所谓哈希冲突,就是指两个不同的对象,哈希之后具有相同的值。
Q:上面我们提到HashTable的key必须是可哈希的,意味着什么呢?
A:也就是说,我们需要是哈希函数具有确定性。为此我们要求哈希表中的key是不可变的数据类型,并且我们为key的不可以变类型定义了哈希函数,那么我们可以成为该key是可哈希的。
11.2.2、优秀哈希函数特点 一个优秀的Hash函数具有如下几个特点:
正向快速: 给定明文和Hash算法,在有限的时间和优先的资源内能计算到Hash值;
碰撞阻力: 无法找到两个不相同的值,经过Hash之后得到相同的输出;
隐蔽性: 只要输入的集合足够大,那么输入信息经过Hash函数后具有不可逆的特性。
谜题友好: 也就是说对于输出值y,很难找到输入x,是的H(x)=y,那么我们就可以认为该Hash函数是谜题友好的。
Hash函数在区块链中占据着很重要的地位,其隐秘性使得区块链具有了匿名性。
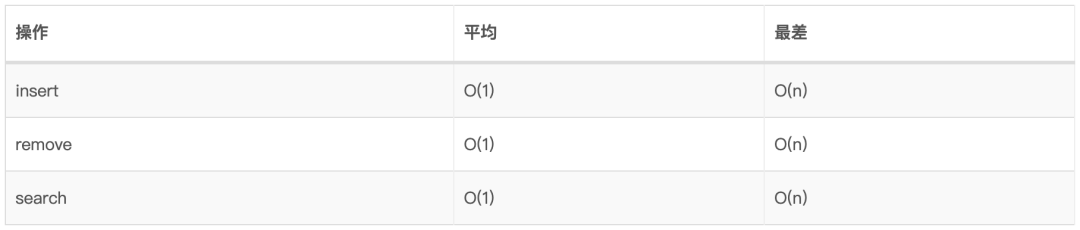
11.3、HashTable如何工作 理想情况下,我们通过使用哈希函数索引到HashTable的方式,在O(1)时间内很快的进行元素的插入、查找和删除动作。
只有具有良好的统一哈希函数的时候,才能真正的实现花费恒定时间操作哈希表。
11.3.1、哈希冲突的解决办法 哈希冲突 :由于哈希算法被计算的数据是无线的,而计算后的结果范围是有限的,因此总会存在不同的数据结果计算后得到相同值,这就是哈希冲突。
常用的两种方式是:链地址法和开放定址法。
11.3.1.1、链地址法 链地址法是通过维护一个数据结构(通常是链表)来保存散列为特定key的所有不同值来处理散列冲突的策略之一。
链地址通常使用链表来实现,针对散列冲突的数据,构成一个单向链表,将链表的头指针存放在哈希表中。
除了使用链表结构,也可以使用数组、二叉树、自平衡树等。
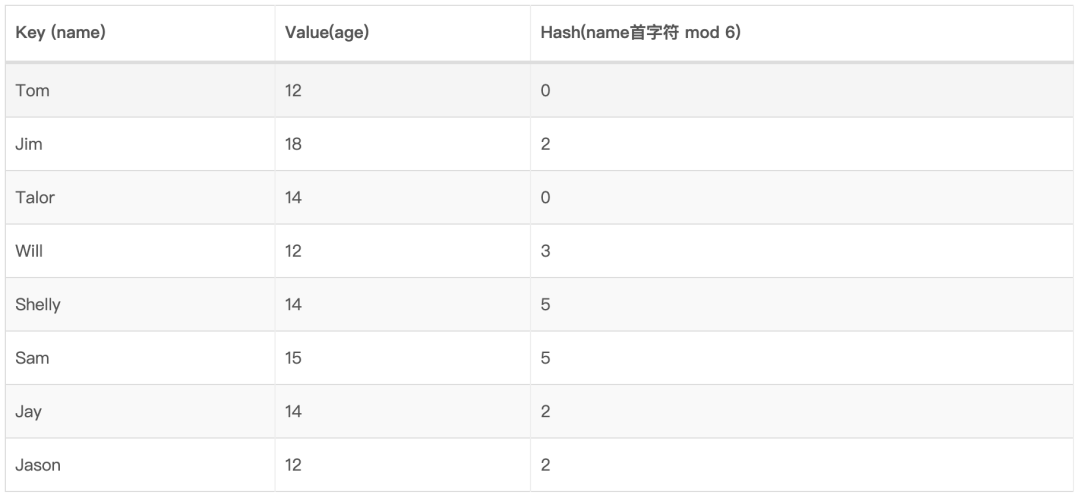
如下,假设我们哈希函数实现如下:名字首字符的ASCII码 mod 6,有如下数据需要存储到哈希表中:
构造哈希表如下:
Q:一旦HashTable被填满了,并且链表很长,怎么保证O(1)的插入和查找呢?
A:应该创建一个更大容量的HashTable,并将旧的HashTable的所欲项目重新哈希分散存入新的HashTable中。
Q:如何查找元素?
A:把需要查找的元素hash成具体的key,在HashTable中查找桶位置,然后判断是否桶位置为一个链表,如果是则遍历链表一一比较元素,判断是否为要查找的元素:
如查找Jason,定位到桶2,然后遍历链表对比元素:
Q:如何删除HashTable中的元素
A:从HashTable中查找到具体的元素,删除链表数据结构中的节点。
11.3.1.2、开放式寻址法 在哈希表中查找到另一个位置,把冲突的对象移动过去,来解决哈希冲突。
使用这种方式,意味着键值对存储在HashTable本身中,并不是存放在单独的链表中。这需要我们非常注意HashTable的大小。
假设需要保持O(1)时间复杂度,负载因子需要保持在某一个固定值下 ,一旦负载因子超过这个阈值时间复杂度将成指数增长,为了避免这种情况,我们需要增加HashTable的大小,也就是进行扩容操作 。以下是来自wikipedia的负载因子跟查找效率的关系图:
当我们对键进行哈希处理H(k)获取到键的原始位置,发现该位置已被占用,那么就需要通过探测序列P(x)来找到哈希表中另一个空闲的位置来存放这个原始。
开放式寻址探测序列技术
开放式寻址常见的探测序列方法有:
线性探查法:P(x) = ax + b,其中a、b为常数
平方探查法:P(x) = ax^2 + bx + c,其中a, b, c为常数
双重哈希探查法:P(k, x) = x * H2(k),其中H2(k),是另一个哈希函数;
伪随机数发生器法:P(k, x) = x*RNG(H(k), x),其中RNG是一个使用H(k)作为seed的随机数字生成函数;
11.3.1.2.1、开放式寻址法的解决思路 在大小为N的哈希表上进行开放式寻址的一般插入方法的伪代码如下:
1 x = 1;2 keyHash = H(k) % N;3 index = keyHash;4 while ht[index] != null {5 index = (keyHash + P(k, x)) %N;6 x++;7 }8 insert (k, v) at ht[index]其中H(k)是key的哈希函数,P(k, x)是寻址函数。
11.3.1.2.2、混乱的循环 大多数选择的以N为模的探测序列都会执行比HashTable大小少的循环。当插入一个键值对并且循环寻址找到的所有桶都被占用了,那么将会陷入死循环。
诸如线性探测、二次探测、双重哈希等都很容易引起死循环问题。每种探测技术都有对应的解决死循环的方法,这里不深入展开探讨了。
11.4、使用场景 11.5、时间复杂度
11.6、编程实践 12、并查集 关于并查集,有一个很牛逼的比喻博文,还不了解并查集的同学可以看看这里:超有爱的并查集~:https://blog.csdn.net/niushuai666/article/details/6662911 ,包你一看就懂。主要提供三个功能:
12.1、使用场景
Kruskal最小生成树算法
网格渗透
网络连接状态
图像处理
12.2、最小生成树[3] 最小生成树:一个有 n 个结点的连通图的生成树是原图的极小连通子图,且包含原图中的所有 n 个结点,并且有保持图连通的最少的边。[1] 最小生成树可以用kruskal(克鲁斯卡尔)算法或prim(普里姆)算法求出。
如果对图相关概念不太了解,可以查阅这篇文章:图论(一)基本概念。
生成基本流程:
把图的边按照权重进行排序;
12.3、实现思路 12.3.1、构建并查集 假设我们想通过这些字母构建并查集:E A B F C D,我们可以把这些字母映射到数组的索引中,数组的元素值代表当前字母的上级字母索引值,由于刚开始还没有做合并操作,所以所有元素存的都是自己的索引值:
同时我们新增一个数组,用于记录当前字母手下收了多少个字母小弟,当两个字母要合并的时候,首先找到两个字母的大佬,然后字母大佬收的小弟少的要拜字母大佬小弟多的人为大佬:
为了合并两个元素,可以找到每个组件的根节点,如果根节点不同,则使一个根节点成为另一个根节点的父节点。
接下来我们要执行以下合并操作:
union(E, A), union(A, B)
接着执行
union(F, C), union(C, B)
执行到这里,这里会剩下两个组件:EABFC,D
12.3.2、并查集搜索 看到这里,相信你对并查集的搜索原理也了解了。要查找某个特定元素属于哪个组件,可以通过跟随父节点直到达到自环(该节点父节点指向本身)来找到该组件的根 。比如要搜索C,我们会沿着记录的parent索引id一直往上层搜索,最终搜到E。
12.2.3、并查集路径压缩 我们可以发现,在极端情况下,需要找很多层的parent节点,才能找到最终的根节点。
为此我们可以在find查找节点的时候,找到该节点到跟节点中间的所有节点,重新指向最终找到的根节点来减小路径长度,这样下次在find这些节点的时候,就非常快了。如下图,我们查找A的根节点,查找到之后进行路径压缩:
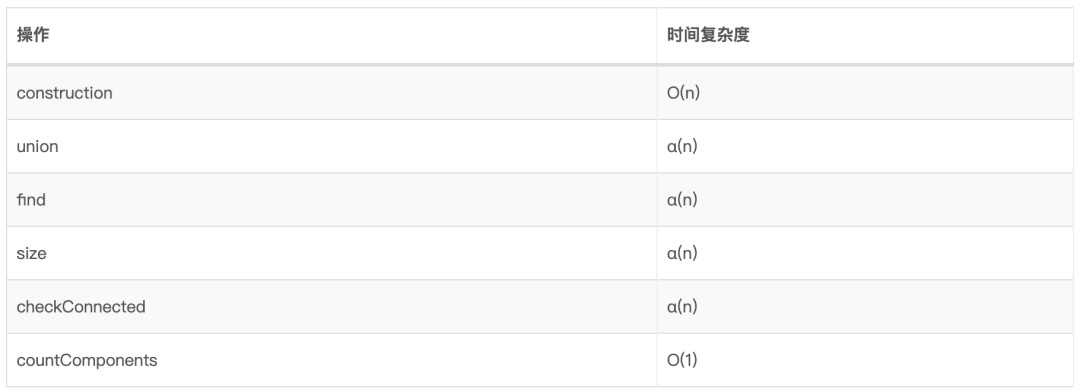
12.4、时间复杂度
α(n):均摊时间[4]
12.5、编程实践 13、树状数组 Fenwick Tree 13.1、为什么需要Fenwick Tree 假设我们有一个数组A,需要计算数组中[i, j) 区间的数据之和,为了方便获取,我们提前把算好的前面n个元素之和存到另一个数组B的n+1中,如下:
这样我们就很方便的计算区间和了,如:
[2, 5) = B[5] - B[2] = 18 - 6 = 12
但是假设我们想修改A中第i个元素的值,那么B中第i+1之后的元素值都得更新:
也就是说更新的复杂度为O(n),有没有更好的办法加快更新速度呢?这个时候我们的Fenwick Tree就要出场了,Fenwick Tree也叫Binary Indexed Tree(二元索引树)。
13.2、什么是Fenwick Tree Fenwick Tree是一种支持给静态数组范围求和,以及在静态数组中更新元素的值后也能够进行进行范围求和的数据结构。
最低有效位 (LSB least significant bit):静态数组的小标可以转换为二进制,如8:01000,最低有效位指的是从右往左数,不为0的位,这里为 1000,计算数组小标最低有效为的函数我们一般命名为lowbit,实现参考后续代码。
数组下标的最低有效位的值n,表示该下标存储了从该下标往前数n位元素的数值之和。如下图:
我们可以发现:
1:只保存当前下标元素的值,对应上面红色区块;
10:保存下标往前数总共2个元素的值,对应上面蓝色区块;
100:保存下标往前数总共4个元素的值,对应上面紫色区块;
1000:保存下标往前数总共8个元素的值,对应上面绿色区块;
10000:保存下标往前数总共16个元素的值,对应上面浅蓝色区块;
13.2.1、范围求和 有了上面的数据结构,我们就可以进行范围求和了。
假设我们要求和[1, 7],我们只要把以下红色区块值相加就可以了,也就是 sum = B[7] + B[6] + B[4]
如果我们要求和[10, 14],那么我们可以这样处理:sum = sum[1, 14] - sum[1, 9] = (B[14] + B[12] + B[8]) - (B[9] + B[8])。
也就是说,针对范围查询,我们会根据LSB一直回溯上一个元素,然后把回溯到的元素都加起来。
最差的情况下,求和的复杂度为:O(log2(n))
以下是实现范围求和的代码:
1 /** 2 * 求和 [1, i] 3 */ 4 public int prefixSum (int i) 5 sum = 0 ; 6 while (i != 0 ) { 7 sum = sum + tree[i] 8 i = i = lowbit(i); 9 }10 return sum;11 }12 13 /**14 * 求和 [i, j]15 */ 16 public int rangeQuery (int i, int j) 17 return prefixSum(j) - prefixSum(i - 1 ); 18 }13.2.2、单点更新 更新数组中的某一个元素的过程中,与范围查询相反,我们不断的根据LSB计算到下一个元素位置,同时给该元素更新数组。如下,更新A[9],会级联查找到以下红色的位置的元素:
以下是实现代码,给第i个元素+x:
1 public void add (int i, int x) 2 while (i < N) {3 tree[i] = tree[i] + x;4 i = i + lowbit(i)5 }6 }13.2.3、构造Fenwick Tree 假设A为静态数组,B数组存放Fenwick Tree,我们首先把A数组clone到B数组,然后遍历A数组,每个元素A[i]依次加到下一个负责累加的B节点B[i + LSB]中(称为父节点),直到到达B数组的上界,代码如下:
1 public FenwickTree (int [] values) 2 N = values.length; 3 values[0 ] = 0L ; 4 5 // 为了避免直接操纵原数组,破坏了其所有原始内容,我们复制一个values数组 6 tree = values.clone(); 7 8 for (int i = 1 ; i < N; i++) { 9 // 获取当前节点的父节点 10 int parent = i + lowbit(i);11 if (parent < N) {12 // 父节点累加当前节点的值 13 tree[parent] += tree[i];14 }15 }16 }
思考:如果我们想要快速更新数组的区间范围,如何实现比较好呢?参考:
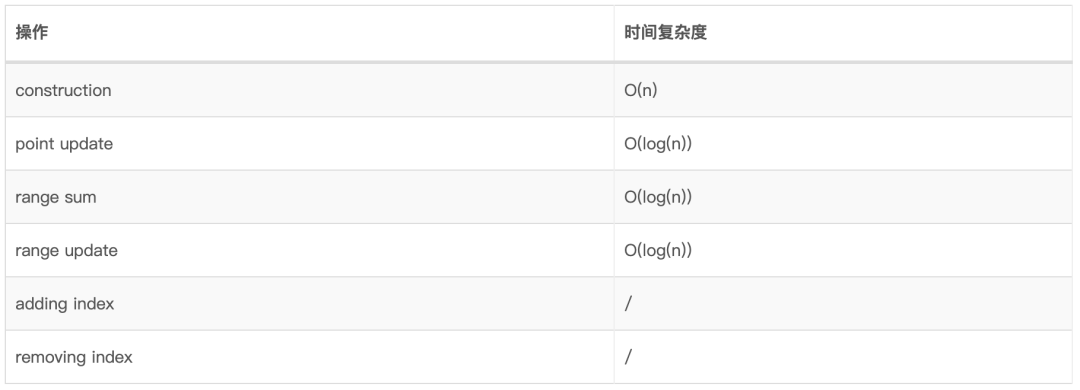
13.3、时间复杂度
13.4、编程实践
单点更新,区间查找:FenwickTreeRangeQueuePointUpdatehttps://github.com/arthinking/java-tech-stack-resource/blob/master/src/main/java/com/itzhai/algorithm/datastructures/fenwicktree/FenwickTreeRangeQueryPointUpdate.java
区间更新,单点查找:FenwickTreeRangeUpdatePointQueryhttps://github.com/arthinking/java-tech-stack-resource/blob/master/src/main/java/com/itzhai/algorithm/datastructures/fenwicktree/FenwickTreeRangeUpdatePointQuery.java
练习:
Range Sum Query - Mutablehttps://leetcode.com/problems/range-sum-query-mutable
14、后缀数组 Suffix Array 后缀数组是后缀树的一种节省空间的替代方法,后缀树本身是trie的压缩版本。
后缀数组可以完成后缀树可以完成的所有工作,并且带有一些其他信息,例如最长公共前缀(LCP)数组
14.1、后缀数组格式 如下图,字符串:arthinking,所有的后缀,从长到短列出来:
给后缀排序,排序后对应的索引构成的数组既是后缀数组:
后缀数组sa :后缀suffix列表排序后,suffix的下标构成的数组sa;
rank :suffix列表每个元素的排位权重(权重越大排越后面);
14.2、后缀数组构造过程 上面的后缀构造过程是怎样的呢?
这里我们介绍最常见的倍增算法来得到后缀数组。
我们获取每一个元素的权重rank,获取到之后,依次继续
第0轮:suffix[i] = suffix[i] + suffix[2^0],重新评估rank;
第1轮:suffix[i] = suffix[i] + suffix[2^1],重新评估rank;
…
第n轮:suffix[i] = suffix[i] + suffix[2^n],重新评估rank;
…
最终得到所有rank都不相等即可。如下图所示:
这样就得到rank了,我们可以根据rank很快推算出sa数组。
为什么可以这样倍增,跳过中间某些元素进行比较呢?
这是一种很巧妙的用法,因为每个后缀都与另一个后缀有一些共同之处,并不是随机字符串,迁移轮比较,为后续比较垫底了基础。
假设要处理substr(i, len)子字符串。我们可以把第k轮substr(i, 2^k)看成是一个由substr(i, 2^k−1)和substr(i + 2^k−1, 2^k−1)拼起来的东西,而substr(i, 2^k−1)的字符串是上一轮比较过的并且得出了rank。
14.3、后缀数组使用场景
在较大的文本中查找子字符串的所有出现;
最长重复子串;
快速搜索确定子字符串是否出现在一段文本中;
多个字符串中最长的公共子字符串
…
LCP数组
最长公共前缀(LCP longest common prefix)数组,是排好序的suffix数组,用来跟踪获取最长公共前缀(LCP longest common prefix)。
14.4、编程实践 这篇文章的内容就差不多介绍到这里了,能够阅读到这里的朋友真的是很有耐心,为你点个赞。
本文为arthinking基于相关技术资料和官方文档撰写而成,确保内容的准确性,如果你发现了有何错漏之处,烦请高抬贵手帮忙指正,万分感激。
大家可以关注我的博客: itzhai.com 获取更多文章,我将持续更新后端相关技术,涉及JVM、Java基础、架构设计、网络编程、数据结构、数据库、算法、并发编程、分布式系统等相关内容。
如果您觉得读完本文有所收获的话,可以关注我的账号,或者点个赞 吧,码字不易,您的支持就是我写作的最大动力, 再次感谢!
References 算法的时间与空间复杂度
[2]: 完全二叉树
[3]: 算法导论--最小生成树(Kruskal和Prim算法)
[4]: Constant Amortized Time ↩
Data Structures Easy to Advanced Course - Full Tutorial from a Google Engineer