![]()
基于1.1.5-alpha版本,具体源码笔记可以参考我的github:https://github.com/saigu/JavaKnowledgeGraph/tree/master/code_reading/canal
关于instance的定义,可以参考前面的几篇源码解析,介绍的非常清楚。
instance模块比较简单,我们重点了解以下几个问题
-
instance配置模式有哪几种,如何根据配置创建instance?
-
-
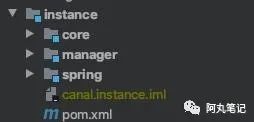
1.基本结构
![]()
instance模块下面也分为三个子模块,core、manager、spring。
其中,core是instance的核心逻辑 。
而manager和spring只是两种不同的instance配置读取方式,manager通过http请求读取admin的配置,spring通过配置文件的方式读取。
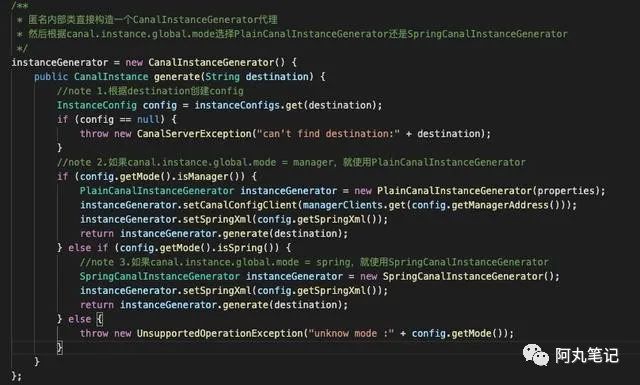
主要控制逻辑我们在deployer模块源码分析中提到过,就是在CanalController类 的instanceGenerator,配置参数是canal.instance.global.mode
-
-
如果canal.instance.global.mode = manager,就使用PlainCanalInstanceGenerator
-
如果canal.instance.global.mode = spring,就使用SpringCanalInstanceGenerator
源码如下
![]()
2.core子模块
![]()
代码不多,就两个接口,两个类。
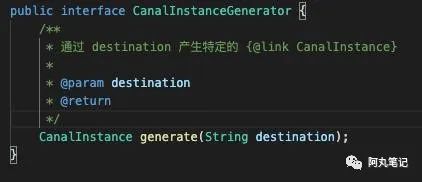
2.1 CanalInstanceGenerator接口
这个接口只有一个方法
![]()
具体实现就是开头提到的两种,PlainCanalInstanceGenerator和SpringCanalInstanceGenerator,分别在manager子模块和spring子模块中实现。
具体选择就是开头的那个canalController里面根据canal.instance.global.mode来选择。
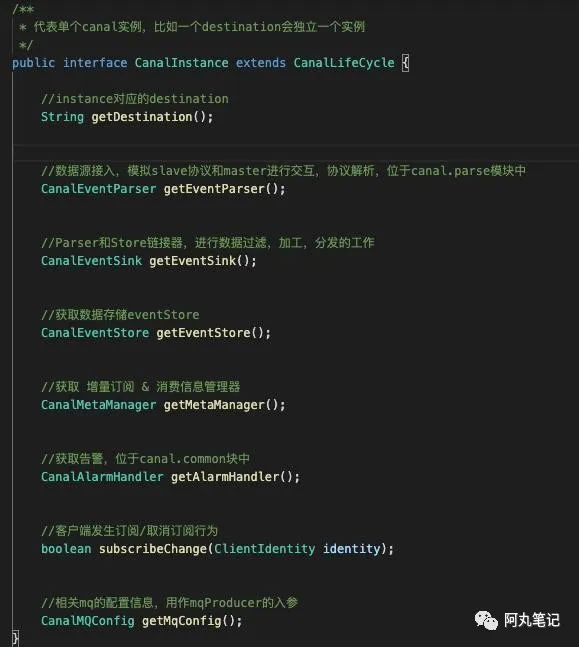
2.2 CanalInstance接口
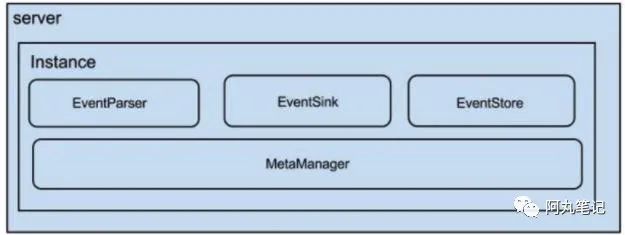
先看一张官方文档的图,这个前面的文章已经分析过了。
![]()
server代表一个canal-server运行实例,对应于一个jvm。server内部可以有多个instance。
Instance内部有4个主要组件:
-
eventParser :数据源接入,模拟slave协议和master进行交互,协议解析
-
eventSink :Parser和Store连接器,进行数据过滤,加工,分发的工作
-
-
-
在这个接口中,就定义了获取4个组件的方法,以及新版本增加的mqProducer的配置信息(mqProducer在server模块解析中介绍过了,可以回头去看看)
![]()
我们简单看下4个组件接口的各个实现类。
CanalEventParser接口实现类(paser模块):
-
MysqlEventParser:伪装成单个mysql实例的slave解析binglog日志
-
GroupEventParser:伪装成多个mysql实例的slave解析binglog日志。内部维护了多个CanalEventParser,组合多个EventParser进行合并处理,group只是作为一个delegate处理。主要应用场景是分库分表:比如一个大表拆分了4个库,位于不同的mysql实例上,正常情况下,我们需要配置四个CanalInstance。对应的,业务上要消费数据时,需要启动4个客户端,分别链接4个instance实例。为了方便业务使用,此时我们可以让CanalInstance引用一个GroupEventParser,由GroupEventParser内部维护4个MysqlEventParser去4个不同的mysql实例去拉取binlog,最终合并到一起。此时业务只需要启动1个客户端,链接这个CanalInstance即可
-
LocalBinlogEventParser:解析本地的mysql binlog。例如将mysql的binlog文件拷贝到canal的机器上进行解析。
-
RdsLocalBinlogEventParser:基于阿里云rds的binlog备份文件复制,下载到本地后进行本地的binlog解析。
CanalEventSink接口实现类(sink模块):
CanalEventStore接口实现类(store模块):
CanalMetaManager(meta模块):
ZooKeeperMetaManager:将元数据存存储到zk中
MemoryMetaManager:将元数据存储到内存中
MixedMetaManager:组合memory + zookeeper的使用模式
PeriodMixedMetaManager:基于定时刷新的策略的mixed实现
FileMixedMetaManager:先写内存,然后定时刷新数据到File
关于这些实现的具体细节,我们在相应模块的源码分析时,进行讲解。目前只需要知道,一些组件有多种实现,因此组合工作方式有多种。
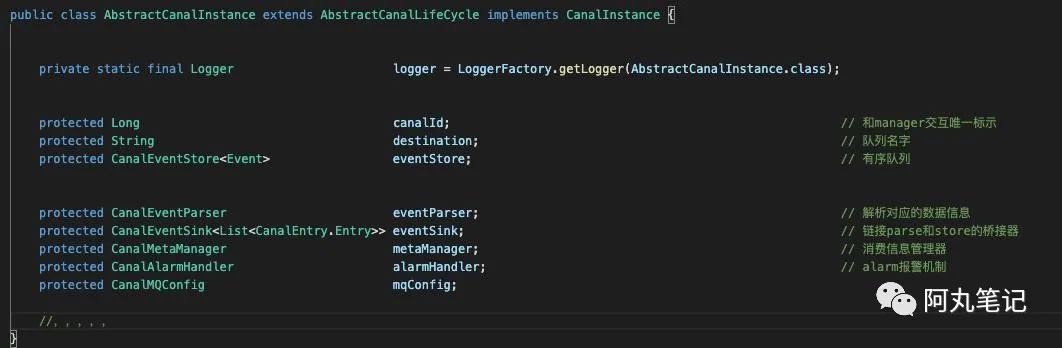
2.3 AbstractCanalInstance类
AbstractCanalInstance是canalInstance的抽象类,维护了相关组件的引用。
同时,也实现了canalInstance接口的subscribeChange方法。
![]()
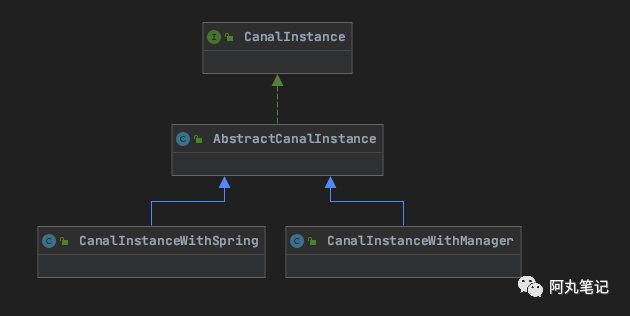
这个抽象类有两个实现,CanalInstanceWithManager 和 CanalInstanceWithSpring。
![]()
AbstractCanalInstance的初始化过程都是在实现类中完成的。
如果选择admin控制模式,那就是在CanalInstanceWithManager中完成;如果是spring模式,就在CanalInstanceWithSpring中完成。
这里有个小发现:
仔细看下实际代码调用我们发现,CanalInstanceWithManager是给ManagerCanalInstanceGenerator使用的,而这个generator实际上没有被使用到。如果使用admin模式,本文开头我们就看到了,使用了PlainCanalInstanceGenerator。PlainCanalInstanceGenerator里面的generate方法实现,其实跟SpringCanalInstanceGenerator差不多。就是从远端admin拉到配置,然后替换系统变量,然后再从spring的beanfactory中构建具体的实例。
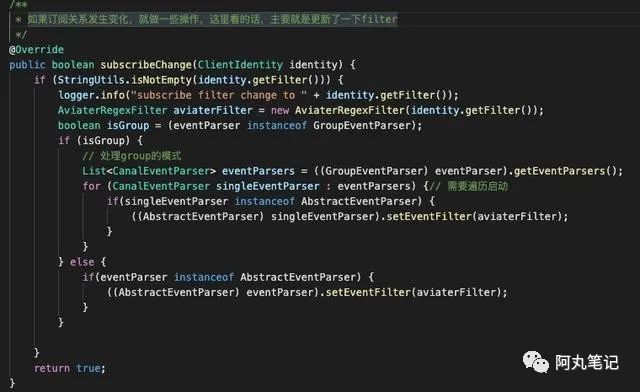
2.3.1 subscribeChange() 方法
AbstractCanalInstance类实现了CanalInstance接口的subscribeChange方法。
我们看到,如果订阅关系发生变化,就做一些操作,这里看的话,主要就是更新了一下filter。
filter规定了需要订阅哪些库,哪些表。
![]()
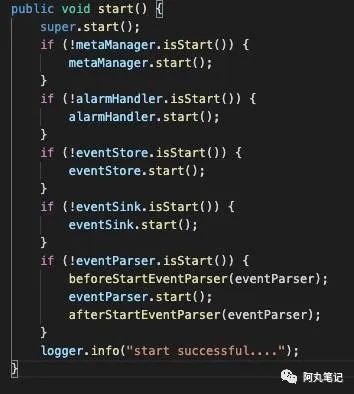
2.3.2 start() 方法
启动没什么特别的逻辑,就是按照顺序依次启动各个组件。
顺序为 metaManager -> alarmHandler -> eventStore -> eventSink -> eventParser。
启动顺序主要跟依赖关系有关,元信息相关的管理跟所有都有关,所以metaManager最先启动,其他的按照彼此之间的关系一一启动。
![]()
这里我们发现,在启动eventParser的时候做了特殊处理,分别是beforeStartEventParser 和 afterStartEventParser。我们在2.3.4专门讲一下。
2.3.3 stop()方法
stop也没什么特殊的,就是依次关闭各个组件。
关闭的顺序就是start的逆过程。
这里就不贴代码了。
2.3.4 eventParserr的特殊处理
在start和stop方法中的eventParser前后都有特殊的处理,start的beforeStartEventParser 和 afterStartEventParser,Stop的beforeStopEventParser 和 afterStopEventParser。
这个其实跟eventParser的设计有关。
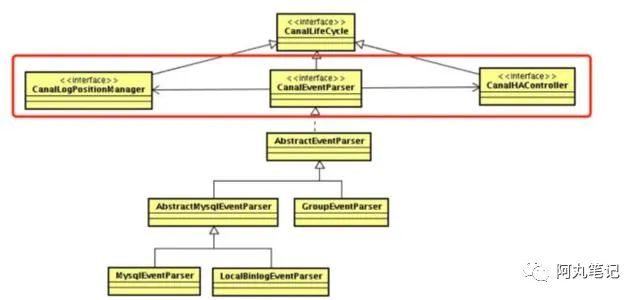
EventParser 设计
![]()
所以这两个beforexxx、afterxxxx方法做的主要是CanalLogPositionManager和CanalHAController的启停工作。
2.3.5 AbstractCanalInstance类 总结
可以看到AbstractCanalInstance除了负责启动和停止其内部组件,就没有其他工作了。
eventParser在AbstractCanalInstance中启动后,就会自行开启多线程任务dump数据,通过eventSink投递给eventStore。
而对eventStore的操作逻辑,实际上都是在CanalServerWithEmbedded中完成的,我们可以回顾一下CanalServerWithEmbedded中 getWithoutAck( ) 的相关逻辑。
包括:
根据clientIdentity的destination获取对应的instance
获取到流式数据中的最后一批获取的位置positionRanges(跟batchId有关联,就是上面那个map里面的)
从cananlEventStore里面获取binlog,转化为event。一般是从最后的一个batchId位置开始,如果之前没有batchId,那么就从cursor记录的消费位点开始;如果cursor为空,那只能从eventStore的第一条消息开始。(这里几个位置关系再想一想,跟ack有关,画个图)
event转化为entry,并生成新的batchId,组合成message返回给客户端
所以,其实这里只是简单的启动和停止,组件的交互逻辑是在CanalServerWithEmbedded中get出instance的各个组件来进行实现的。
3.spring模块
前面提到了,PlainCanalInstanceGenerator里面的generate方法实现,其实跟SpringCanalInstanceGenerator差不多。就是从远端admin拉到配置,然后替换系统变量,然后再从spring的beanfactory中构建具体的实例。
所以我们重点关注spring子模块的配置方式即可。
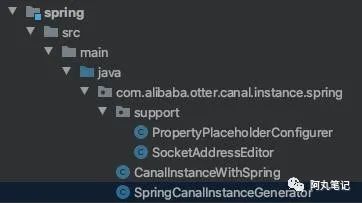
就下面四个类
![]()
3.1 CanalInstanceWithSpring类
基于spring容器启动canal实例,方便独立于manager启动。
继承了AbstractCanalInstance,其实就是一系列组件的setter方法,就不贴源码了。
具体配置是基于spring的xml来做的.
当我们配置加载方式为spring时,创建的CanalInstance实例类型都是CanalInstanceWithSpring。canal将会寻找本地的spring配置文件来创建instance实例。canal默认提供了以下几种spring配置文件:
-
spring/memory-instance.xml
-
-
spring/default-instance.xml
-
spring/group-instance.xml
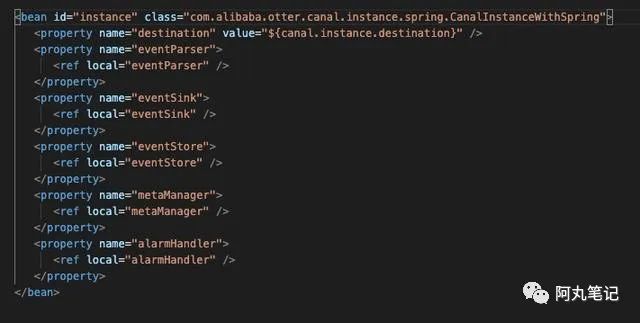
四个配置文件中,对CanalInstanceWithSpring都采用了同样的配置方式:
![]()
当然,具体每个组件的ref在不同配置文件中有所不同。
最主要的就是metaManager 和eventParser 这两个配置有所不同,可能在内存、文件或zk进行存储。
eventStore 、和eventSink 定义都是相同的,eventStore目前的开源版本中eventStore只有一种基于内存的实现,eventSink其作用是eventParser和eventStore的连接器,进行数据过滤,加工,分发的工作。不涉及存储,也就没有必要针对内存、file、或者zk进行区分。
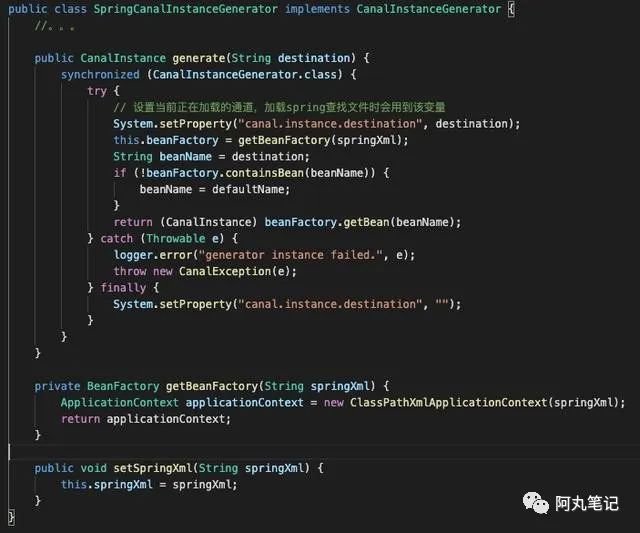
3.2 SpringCanalInstanceGenerator类
这个是具体创建instance的逻辑。
![]()
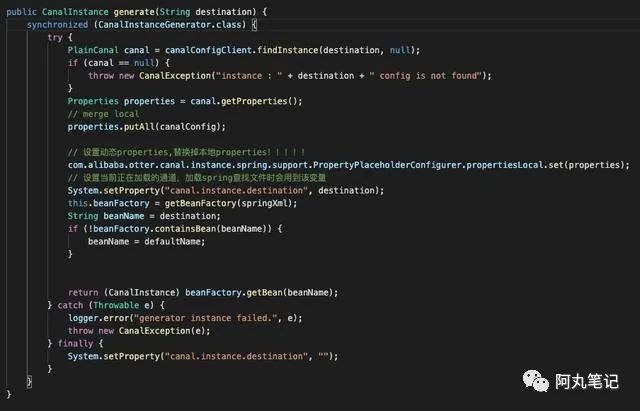
顺便看下PlainCanalInstanceGenerator里面的实现,就是多了从远端拉取配置,然后用PropertyPlaceholderConfigurer进行了变量替换,然后还是用beanFactory来获取实例。
com.alibaba.otter.canal.instance.spring.support.PropertyPlaceholderConfigurer继承了org.springframework.beans.factory.config.PropertyPlaceholderConfigurer,设置动态properties,替换掉本地properties。
![]()
4.总结
其实这个模块的东西比较少,没有什么特别复杂的逻辑。
我们来回顾下开头的几个问题
-
instance配置模式有哪几种,如何根据配置创建instance?
主要有基于spring和基于远端配置两种方式,前者的实现在,后者的实现在PlainCanalInstanceGenerator
PlainCanalInstanceGenerator中使用了spring的PropertyPlaceholderConfigurer来覆盖配置
包括了parser、sink、store、metamanager等组件,但是只负责了启动和停止逻辑,具体交互逻辑还是在CanalServerWithEmbedded中实现的。
原创:阿丸笔记(微信公众号:aone_note),欢迎 分享,转载请保留出处。
扫描下方二维码可以关注我哦~
![]()
觉得不错,就点个 再看 吧👇