public class Hello { public static void main(String[] args) { System.out.println("Hello World"); } }
Python:
print("Hello World")
数组打印
Java:
String s = "i wanna print"; String[] strs = s.split(" "); // 方案1 System.out.println(strs); // 方案2 for (String res : strs) System.out.print(res + " ");
Python:
s = "i wanna print" print(s.split())
Map、List等的使用
Java:
// List List<String> list = new ArrayList<>(); list.add("Mike"); list.add("Lily"); // Map Map<String, String> map = new HashMap<>(); map.put("Mike","First"); map.put("Lily","Second");
Python:
// List list = ["Mike", "Lily"] list.append("Jack") // Map map = {"Mike":"First", "Lily":"Second"} map["Jam"] = "third" del map["Jam"]
fruits = ['banana', 'apple', 'mango'] # 第一个实例,对字符串的字符进行遍历 for letter in 'Python': print(letter) # 第二个实例,像Java中的String s: strs一样对数据进行遍历 for fruit in fruits: print(fruit) # 第三个实例,区间遍历,对标Java:for(int i=0; i<fruits.length; i++) for fruit in range(0, len(fruits)): print(fruit) # 第四个实例,加入了一个[e lse] for fruit in range(0, len(fruits)): print(fruit) else: # 运行会发生在for循环非break跳出的情况下 print("final")
def counter(): i = 0 for _ in range(100000000): i += 1 return True
def main(): start_time = time.time() t = Thread(target=counter) t.start() t.join() end_time = time.time() print("total time of single is: {}".format(end_time - start_time))
def multi_main(): thread_all = [] start_time = time.time() for tid in range(2): t = Thread(target=counter) t.start() thread_all.append(t) for i in range(2): thread_all[i].join() end_time = time.time() print("total time of multi is: {}".format(end_time -start_time))
def find_all_files(dir): all_files = [] for root, dirs, files in os.walk(dir): for file in files: all_files.append(root + "/" + file)
return all_files
def main_file_read(files): start_time = time.time() pool = threadpool.ThreadPool(1) requests = threadpool.makeRequests(file_read, files) [pool.putRequest(request) for request in requests] pool.wait() end_time = time.time() print("total time of single is: {}".format(end_time - start_time))
def multi_main_file_read(files): start_time = time.time() pool = threadpool.ThreadPool(20) requests = threadpool.makeRequests(file_read, files) [pool.putRequest(request) for request in requests] pool.wait() end_time = time.time() print("total time of multi is: {}".format(end_time - start_time))
if __name__ == '__main__': files = find_all_files("/Users/admin/Desktop/1")
Rocky Linux(中文名:洛基)是由Gregory Kurtzer于2020年12月发起的企业级Linux发行版,作为CentOS稳定版停止维护后与RHEL(Red Hat Enterprise Linux)完全兼容的开源替代方案,由社区拥有并管理,支持x86_64、aarch64等架构。其通过重新编译RHEL源代码提供长期稳定性,采用模块化包装和SELinux安全架构,默认包含GNOME桌面环境及XFS文件系统,支持十年生命周期更新。
Sublime Text
Sublime Text具有漂亮的用户界面和强大的功能,例如代码缩略图,Python的插件,代码段等。还可自定义键绑定,菜单和工具栏。Sublime Text 的主要功能包括:拼写检查,书签,完整的 Python API , Goto 功能,即时项目切换,多选择,多窗口等等。Sublime Text 是一个跨平台的编辑器,同时支持Windows、Linux、Mac OS X等操作系统。







 ##如何进行库的导入 一般来说库的导入会分为几种形式:
##如何进行库的导入 一般来说库的导入会分为几种形式: 当然我们完全是可以自己实现的,但显然是一个费时不讨好的活儿。这就让
当然我们完全是可以自己实现的,但显然是一个费时不讨好的活儿。这就让 通过类似上述代码的设定,对命令行中的数据获取就有了一定的diy空间了。
通过类似上述代码的设定,对命令行中的数据获取就有了一定的diy空间了。
 函数的调用会以后者为准,可以将两个函数通过调换的方式来进行验证。
函数的调用会以后者为准,可以将两个函数通过调换的方式来进行验证。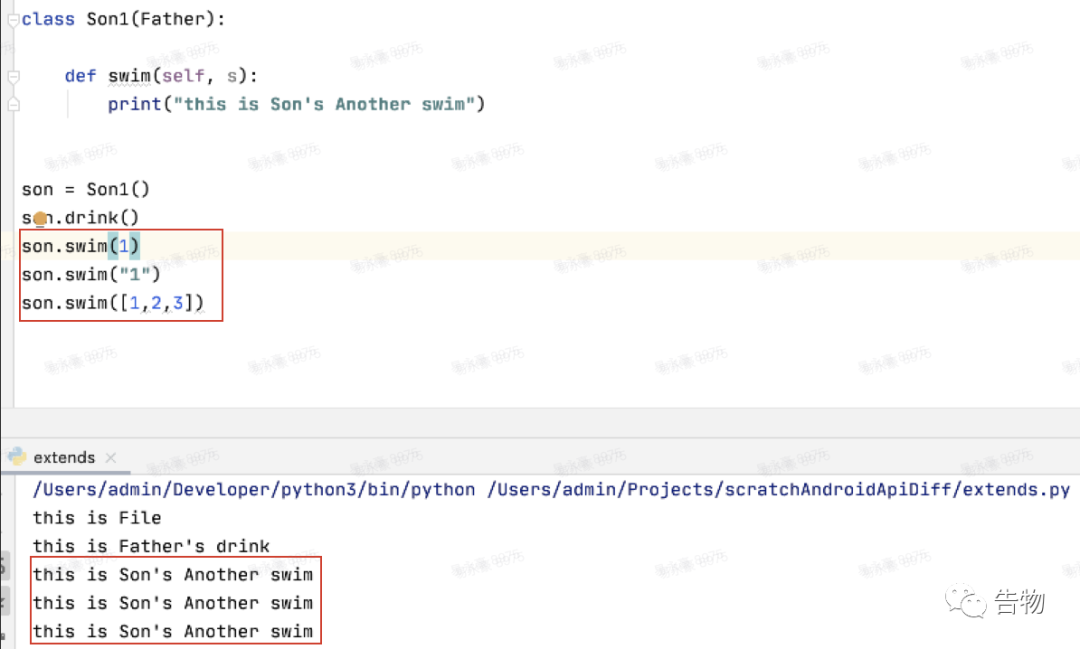


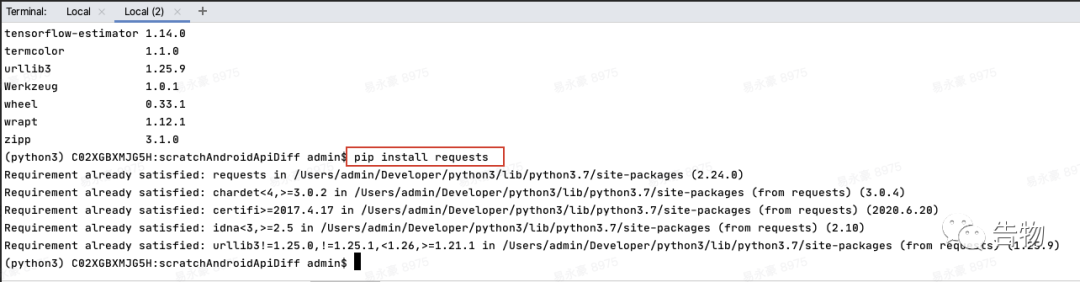


 而将Numpy的版本修改为
而将Numpy的版本修改为 对于
对于 能够发现使用
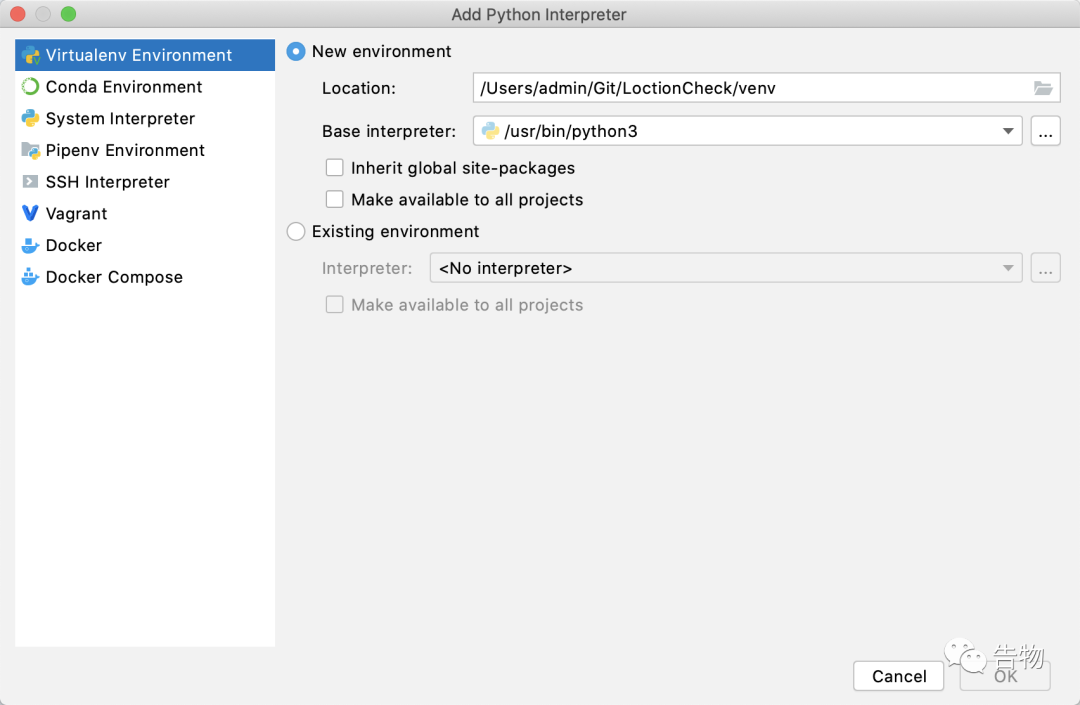
能够发现使用 2.
2. 
 能够发现速度反而是没有单线程执行来的快的,这就是
能够发现速度反而是没有单线程执行来的快的,这就是 主要原因就是文件内容太小了,导致从线程切换上耗时占比较大,而比单线程跑慢一点,但是IO密集型时整体下来,正常情况和单线程拉不开差距。
主要原因就是文件内容太小了,导致从线程切换上耗时占比较大,而比单线程跑慢一点,但是IO密集型时整体下来,正常情况和单线程拉不开差距。

 绿色: 唤醒状态;红色: 阻塞状态,等待CPU调度;白色: 等待IO状态
绿色: 唤醒状态;红色: 阻塞状态,等待CPU调度;白色: 等待IO状态