在之前的文章中,我们介绍了使用JOL这一神器来解析java类或者java实例在内存中占用的空间地址。
今天,我们会更进一步,剖析一下在之前文章中没有讲解到的更深层次的细节。一起来看看吧。
java.lang.Object大家应该都很熟悉了,Object是java中一切对象的鼻祖。
接下来我们来对这个java对象的鼻祖进行一个详细的解剖分析,从而理解JVM的深层次的秘密。
工具当然是使用JOL:
@Slf4jpublic class JolUsage {
@Test public void useJol(){ log.info("{}", VM.current().details()); log.info("{}", ClassLayout.parseClass(Object.class).toPrintable()); log.info("{}", ClassLayout.parseInstance(new Object()).toPrintable()); }}
代码很简单,我们打印JVM的信息,Object class和一个新的Object实例的信息。
看下输出:
从上面的结果我们知道,在64位的JVM中,一个Object实例是占用16个字节。
因为Object对象中并没有其他对象的引用,所以我们看到Object对象只有一个12字节的对象头。剩下的4个字节是填充位。
那么这12字节的对象头是做什么用的呢?
如果想要深入了解这12字节的对象头,当然是要去研读一下JVM的源码:src/share/vm/oops/markOop.hpp。
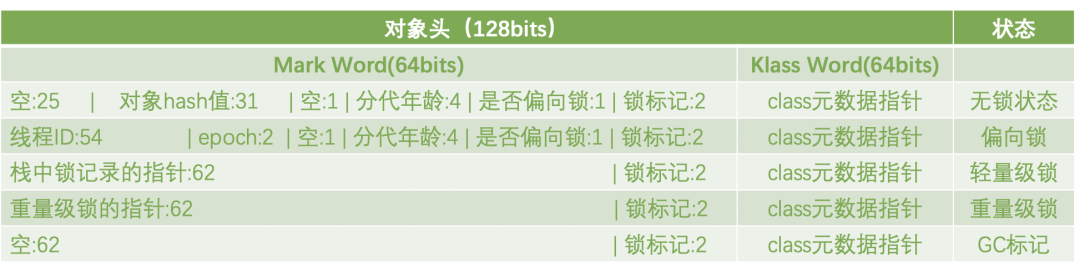
有兴趣的小伙伴可以去看看。如果没有兴趣,没关系,这里给大家一个张总结的图:
javaObject对象的对象头大小根据你使用的是32位还是64位的虚拟机的不同,稍有变化。这里我们使用的是64位的虚拟机为例。
Object的对象头,分为两部分,第一部分是Mark Word,用来存储对象的运行时数据比如:hashcode,GC分代年龄,锁状态,持有锁信息,偏向锁的thread ID等等。
在64位的虚拟机中,Mark Word是64bits,如果是在32位的虚拟机中Mark Word是32bits。
第二部分就是Klass Word,Klass Word是一个类型指针,指向class的元数据,JVM通过Klass Word来判断该对象是哪个class的实例。
且慢!
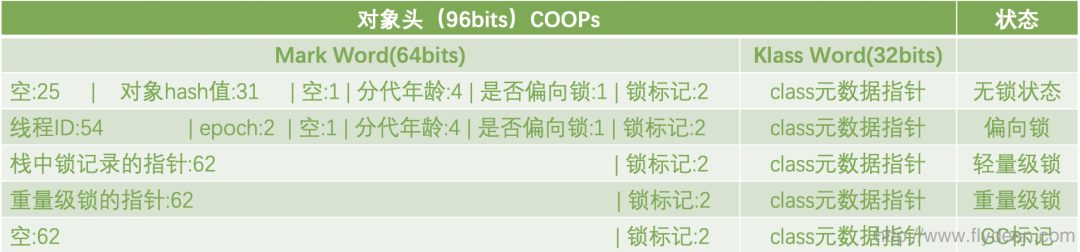
有的小伙伴可能发现了问题,之前我们用JOL解析Object对象的时候,Object head大小是12字节,也就是96bits,这里怎么写的是128bits?
没错,如果没有开启COOPs就是128bits,如果开启了COOPs,那么Klass Word的大小就从64bits降到了32bits。
还记得我们之前讲的COOPs吗?
COOPs就是压缩对象指针技术。
对象指针用来指向一个对象,表示对该对象的引用。通常来说在64位机子上面,一个指针占用64位,也就是8个字节。而在32位机子上面,一个指针占用32位,也就是4个字节。
实时上,在应用程序中,这种对象的指针是非常非常多的,从而导致如果同样一个程序,在32位机子上面运行和在64位机子上面运行占用的内存是完全不同的。64位机子内存使用可能是32位机子的1.5倍。
而压缩对象指针,就是指把64位的指针压缩到32位。
怎么压缩呢?64位机子的对象地址仍然是64位的。压缩过的32位存的只是相对于heap base address的位移。
我们使用64位的heap base地址+ 32位的地址位移量,就得到了实际的64位heap地址。
对象指针压缩在Java SE 6u23 默认开启。在此之前,可以使用-XX:+UseCompressedOops来开启。
java中有一个非常特别的对象叫做数组,数组的对象头和Object有什么区别吗?
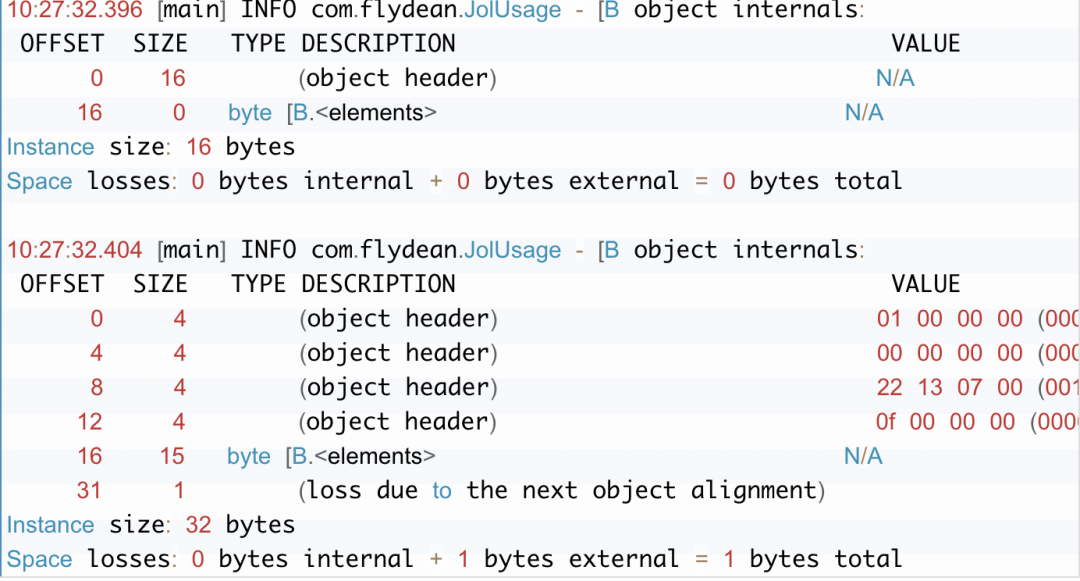
我们用JOL再看一次:
log.info("{}",ClassLayout.parseClass(byte[].class).toPrintable());log.info("{}",ClassLayout.parseInstance("www.flydean.com".getBytes()).toPrintable());
上面的例子中我们分别解析了byte数组的class和byte数组的实例:
看到区别了吗?我们发现数组的对象头是16字节,比普通对象的对象头多出了4个字节。这4个字节就是数组的长度。
好了,写到这里我们来总结一下,java对象的结构可以分为普通java对象和数组对象两种:
数组对象在对象头中多了一个4字节的长度字段。
大家看到最后的字节是padding填充字节,为什么要填充呢?
因为JVM是以8字节为单位进行对其的,如果不是8字节的整数倍,则需要补全。