![]()
好奇害死羊
很多小伙伴们做Java开发,天天写Java代码,肯定离不开Java基础环境:JDK,毕竟我们写好的Java代码也是跑在JVM虚拟机上。
一般来说,我们学Java之前,第一步就是安装JDK环境。这个简单啊,我们一般直接把JDK从官网下载下来,安装完成,配个环境变量就可以愉快地使用了。
不过话说回来,对于这个天天使用的东西,我们难道不好奇这玩意儿它到底是怎么由源码编译出来的吗?
带着这个原始的疑问,今天准备大干一场,自己动动呆萌的小手,来编译一个属于自己的JDK吧!
对了,本文在开源项目:https://github.com/hansonwang99/JavaCollection 中已收录,包含自学编程路线、面试题集合/面经、及系列技术文章等,资源持续更新中...
还有个待填的坑
记得之前不是出过一期关于《JDK源码阅读环境搭建》相关的视频以及文章嘛,细心的小伙伴,可能会发现一个很实际的问题:
我们将src.zip包里的JDK源码解压出来,关联到这份源码之后,调试时是可以进,但是我们在加注释的时候却只能在行尾添加,并不能改变原代码的行结构。换句话说,如果在源码中加了跨行的多行注释,则debug调试的时候就会出现当前行的运行错位问题,这个有点尴尬了。
当然那个视频的评论区,的确也有几个小伙伴提了这个问题:
![]()
![]()
![]()
原因也很简单,因为实际支撑调试运行的代码,并不是我们解压出来的那份JDK源码,那个仅仅是做关联用,实际运行用到的JDK,还是之前系统安装好的那个JDK环境。
要想解决这个问题,那就只能使用自己修改过的代码来自行编译生成自己的JDK,然后用到项目中去!
所以什么都憋说了,肝就完了!
环境准备
首选说在前面的是,编译前的软件版本关系极其重要,自己在踩坑时,所出现的各种奇奇怪怪的问题几乎都和这个有关,后来版本匹配之后,就非常顺利了。
我们来盘点和梳理一下编译一个JDK需要哪些环境和工具:
1、boot JDK
我们要想编译JDK,首先自己本机必须提前已经安装有一个JDK,官方称之为bootstrap JDK(或者称为boot JDK)。
比如想编译JDK 8,那本机必须最起码得有一个JDK 7或者更新一点的版本;你想编译JDK 11,那就要求本机必须装有JDK 10或者11。
所以鸡生蛋、蛋生鸡又来了...
2、Unix环境
编译JDK需要Unix环境的支持!
这一点在Linux操作系统和macOS操作系统上已经天然的保证了,而对于Windows兄弟来说稍微麻烦一点,需要通过使用Cygwin或者MinGW/MSYS这种软件来模拟。
就像官方所说:在Linux平台编译JDK一般问题最少,容易成功;macOS次之;Windows上则需要稍微多花点精力,问题可能也多一些。
究其本质原因,还是因为Windows毕竟不是一个Unix-Like内核的系统,毕竟很多软件的原始编译都离不开Unix Toolkit,所以相对肯定要麻烦一些。
3、编译器/编译工具链
JDK底层源码(尤其JVM虚拟机部分)很多都是C++/C写的,所以相关编译器也跑不掉。
一图胜千言,各平台上的编译器支持如下表所示,按平台选择即可:
![]()
4、其他工具
典型的比如:
好,环境盘点就到这里,接下来具体列一下我在编译JDK 8和JDK 11时分别用到的软件详细版本信息:
编译JDK 8时:
编译JDK 11时:
大家在编译时如果过程中有很多问题,大概率少软件没装,或者软件版本不匹配,不要轻易放弃,需要耐心自查一下。
下载JDK源码
下载JDK源码其实有两种方式。
方式一:通过Mercurial工具下载
Mercurial可以理解为和Git一样,是另外一种代码管理工具,安装好之后就有一个hg命令可用。
![]()
而OpenJDK的源码已经提前托管到http://hg.openjdk.java.net/。
因此,比如下载JDK 8,可直接hg clone一下就行,和git clone一样:
hg clone http://hg.openjdk.java.net/jdk8/jdk8
同理,下载JDK 11:
hg clone http://hg.openjdk.java.net/jdk/jdk11
但是这种方式下载速度不是很快。
方式二:直接下载打包好的源码包
下载地址:https://jdk.java.net/
![]()
选择你想要的版本下载即可。
编译前的自动配置
源码包下载好,放到本地某个目录(建议路径纯英文,避免不必要的麻烦),解压之,然后进入源码根目录,执行:
sh configure
当然这里运行的是默认配置项。
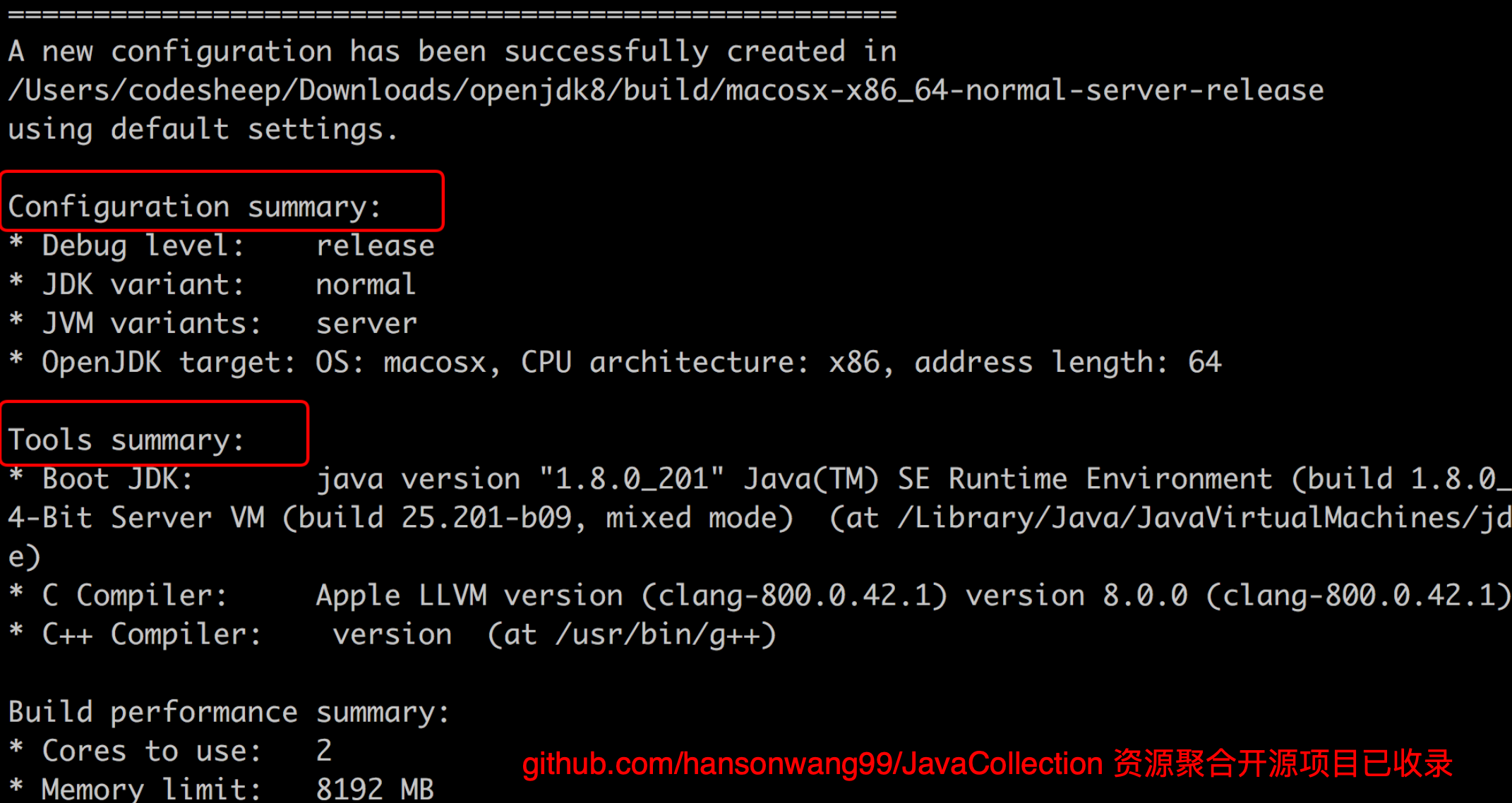
这一步会进行一系列的自动配置工作,时间一般很快,最终如果能出现一下提示,那么很幸运,编译前的配置工作就完成了!
这里我给出我自己分别在配置JDK 11和JDK 8时候完成时的样子:
配置JDK 8完成:
![]()
配置JDK 11完成:
![]()
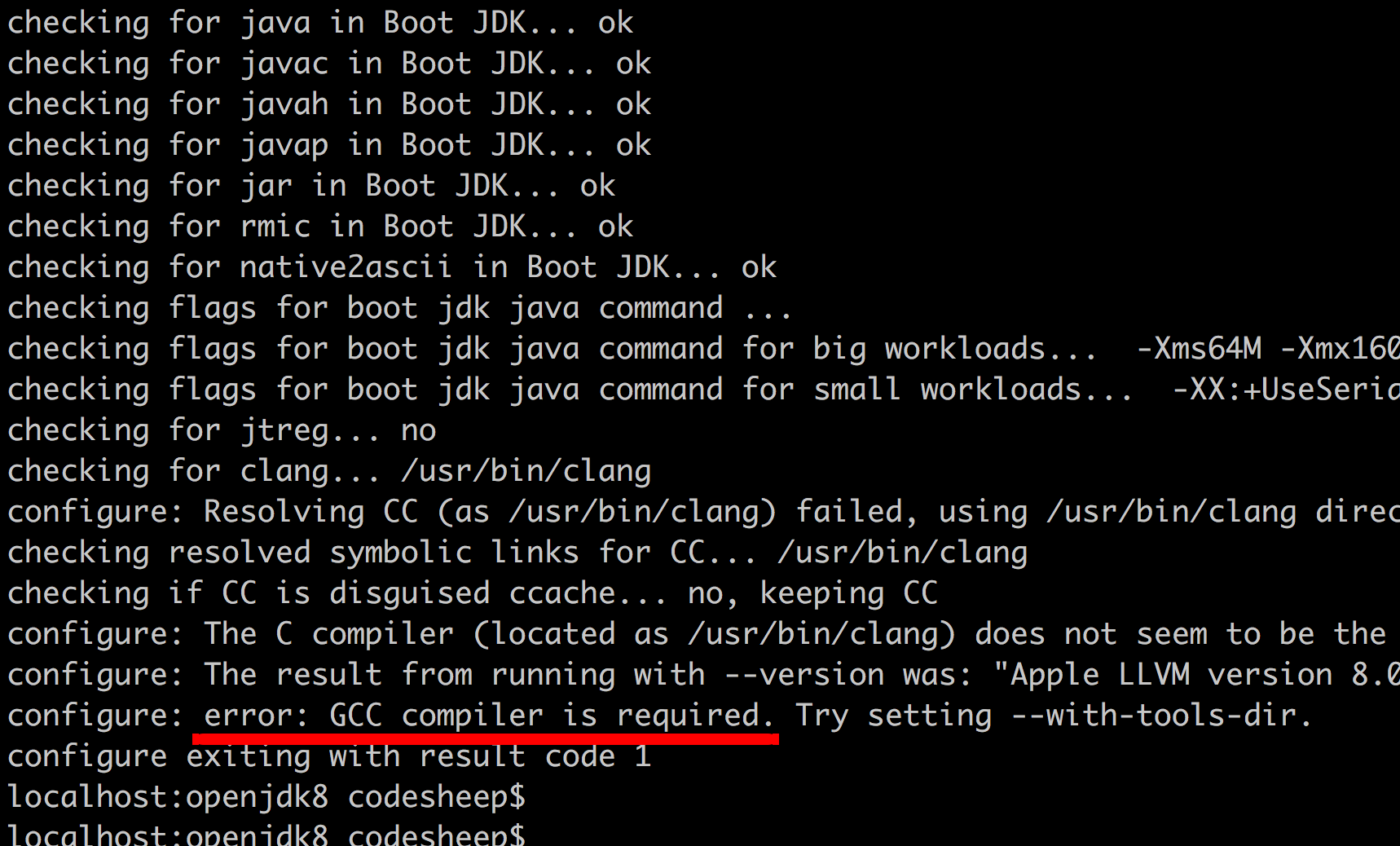
注: 如果这一步出错,大概率是某个软件环境未装,或者即使装了,但版本不匹配,控制台打印日志里一般是会提醒的。
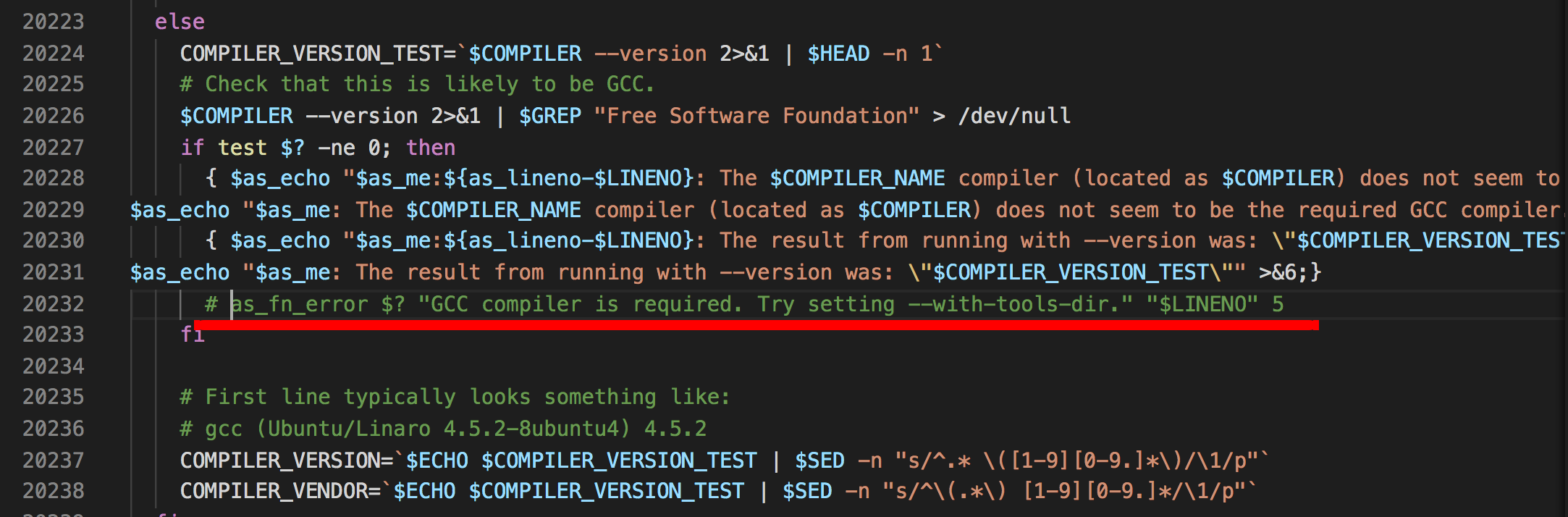
比如我在配置JDK 8的时候,就遇到了一个errof:GCC compiler is required的问题:
![]()
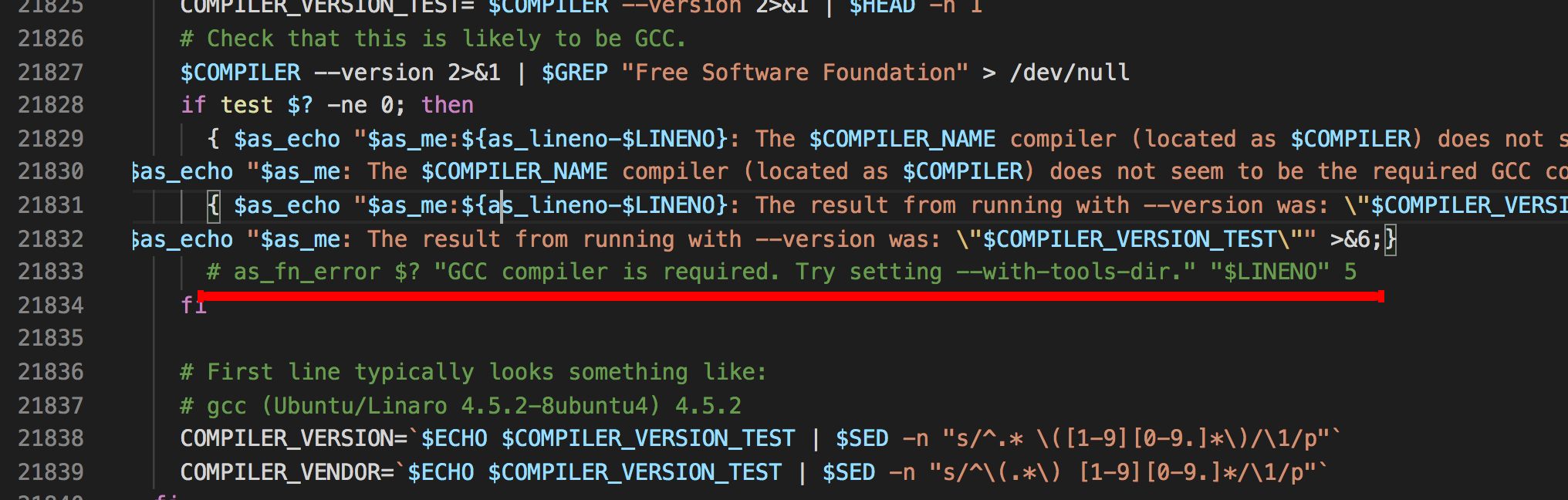
明明系统里已经有编译器,但还是报这个错误。通过后来修改 jdk源码根目录/common/autoconf/generated-configure.sh文件,将相关的两行代码注释后就配置通过了
![]()
![]()
配置完成,接下来开始执行真正的编译动作了!
真正的编译动作
我们这里进行的是全量编译,直接在我们下载的JDK源码根目录下执行如下命令即可:
make all
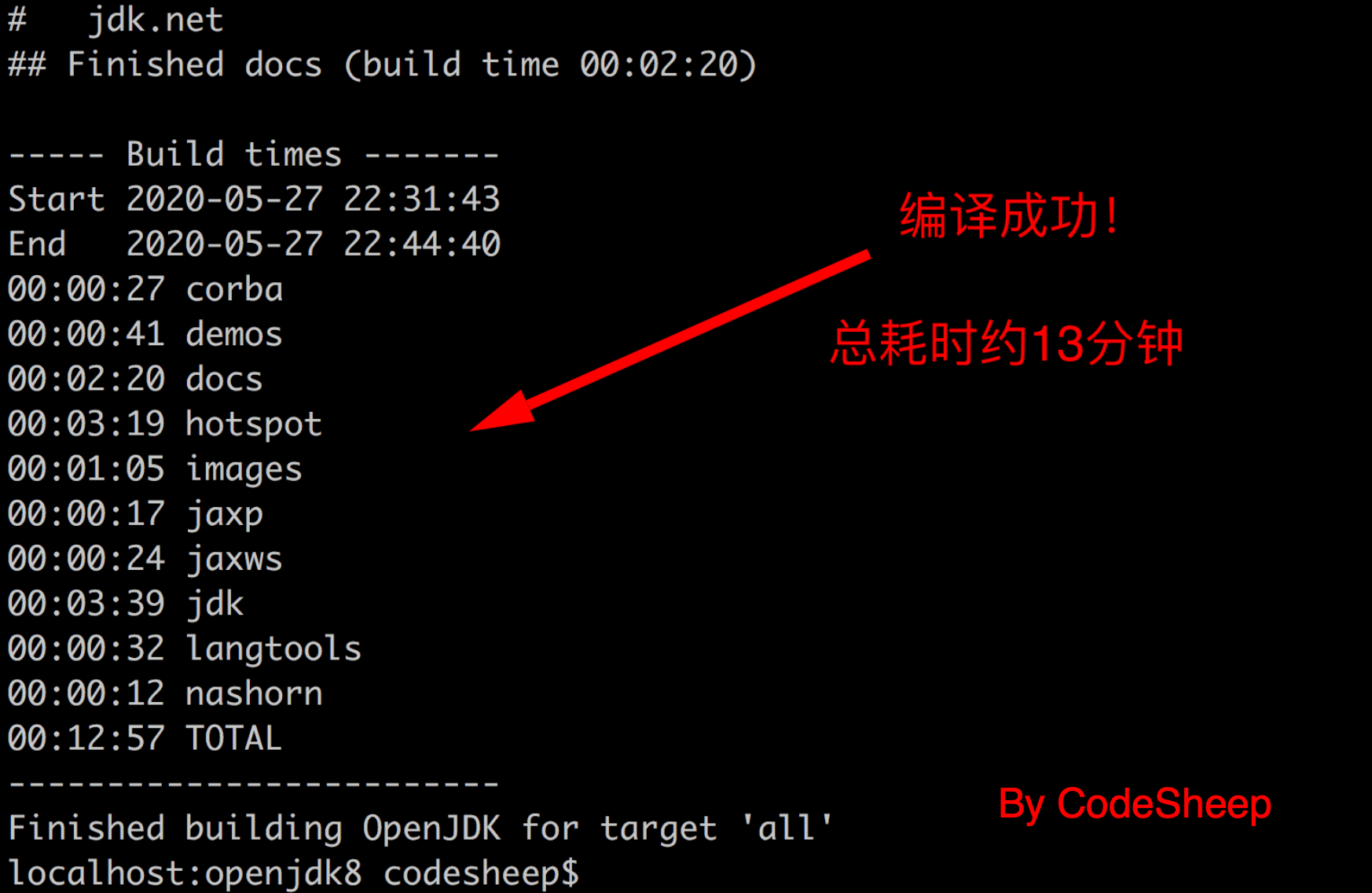
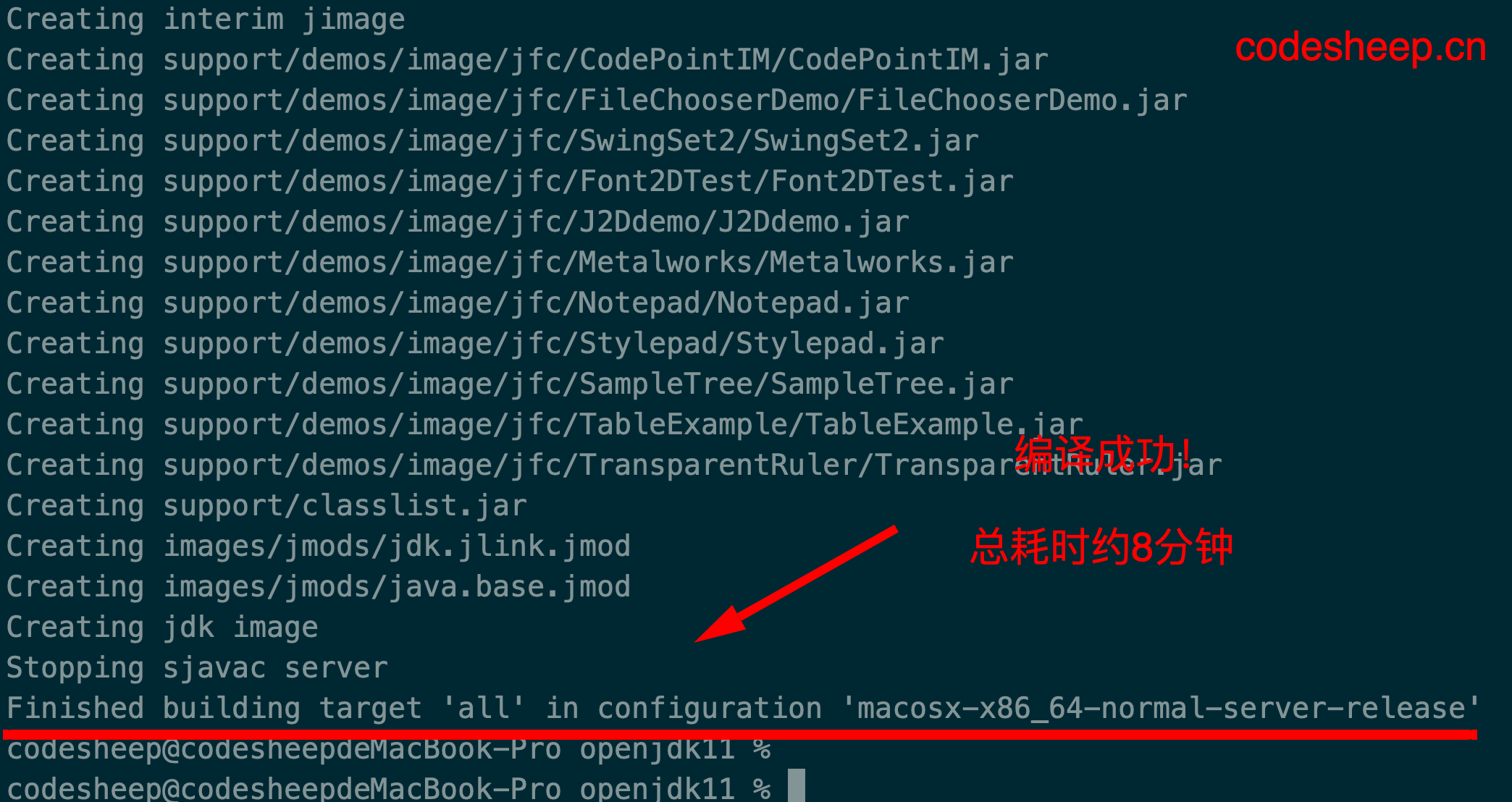
这一步编译需要一点时间,耐心等待一下即可。编译过程如果有错误,会终止编译,如果能看到如下两个画面,那么则恭喜你,自己编译JDK源码就已经通过了,可以搞一杯咖啡庆祝一下了。
JDK 8编译完成:
![]()
JDK 11编译完成:
![]()
从两张图的对比可以看出,编译JDK 8和JDK 11完成时在输出上还是有区别的。时间上的区别很大程度上来源于JDK 11的编译机配置要高不少。
验证成果
JDK源码编译完成之后肯定会产生和输出很多产物,这也是我们所迫不及待想看到的。
由于JDK 8和JDK 11的源码包组织结构并不一样,所以输出东西的内容和位置也有区别。我们一一来盘点一下。
1、JDK 8的编译输出
编译完成,build目录下会生成一个macosx-x86_64-normal-server-release目录,所有的编译成果均位于其中。
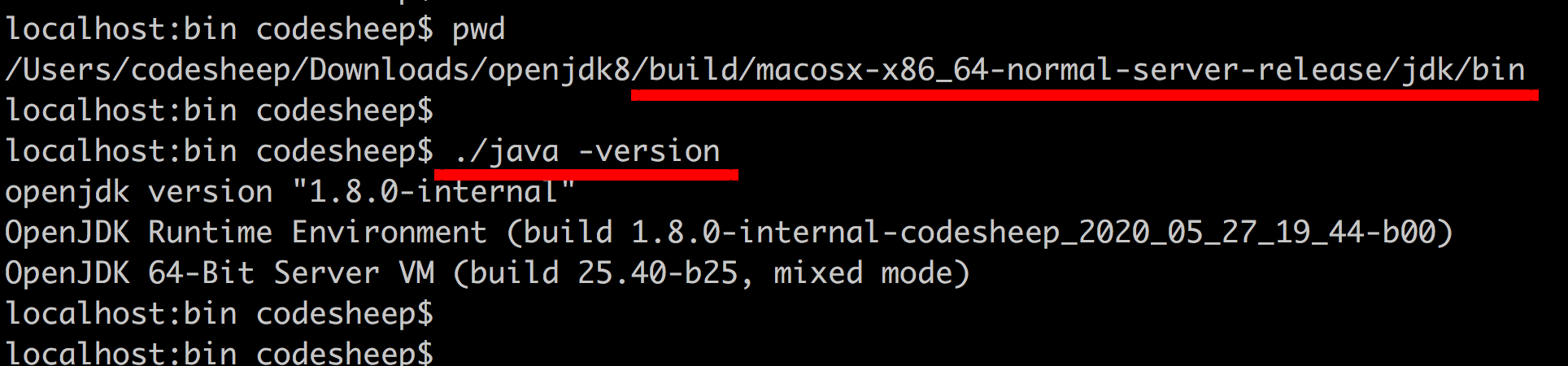
首先,编译出来的Java可执行程序可以在如下目录里找到:
jdk源码根目录/build/macosx-x86_64-normal-server-release/jdk/bin
进入该目录后,可以输入./java -version命令验证:
![]()
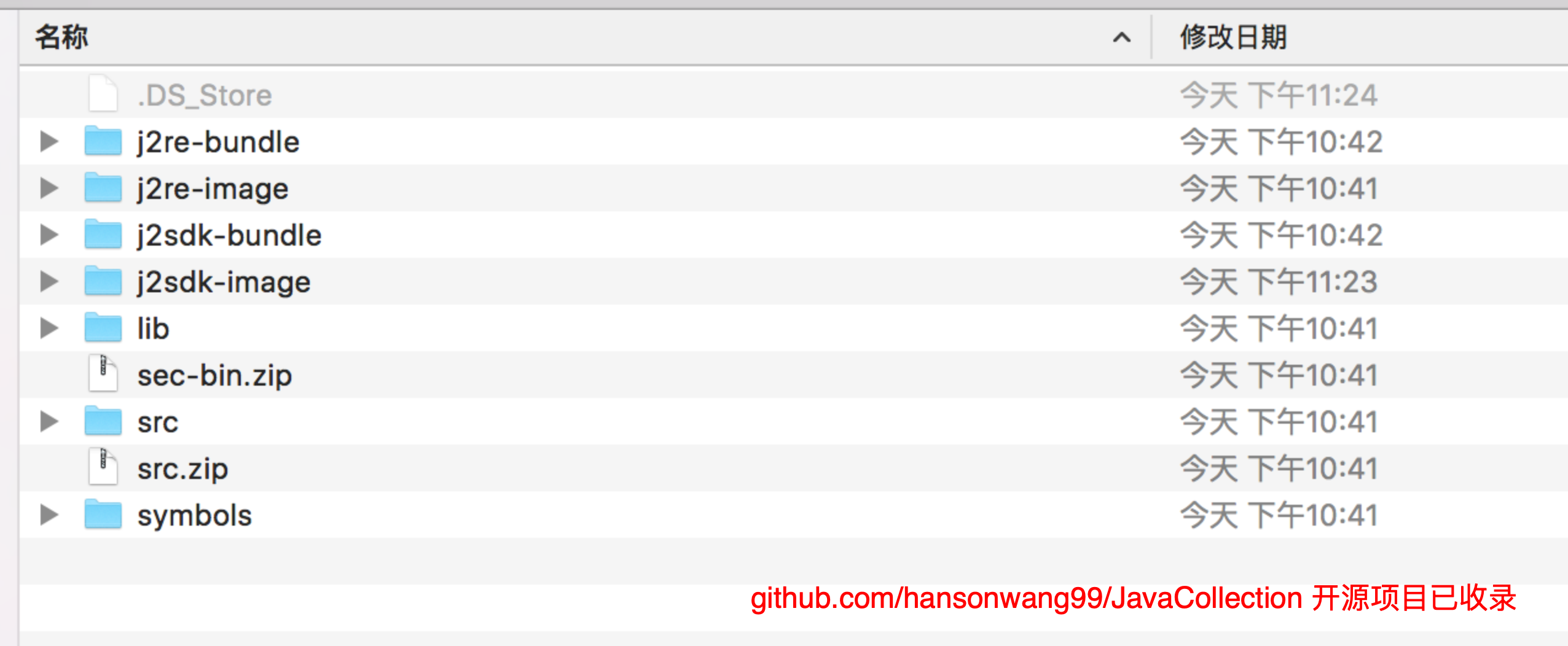
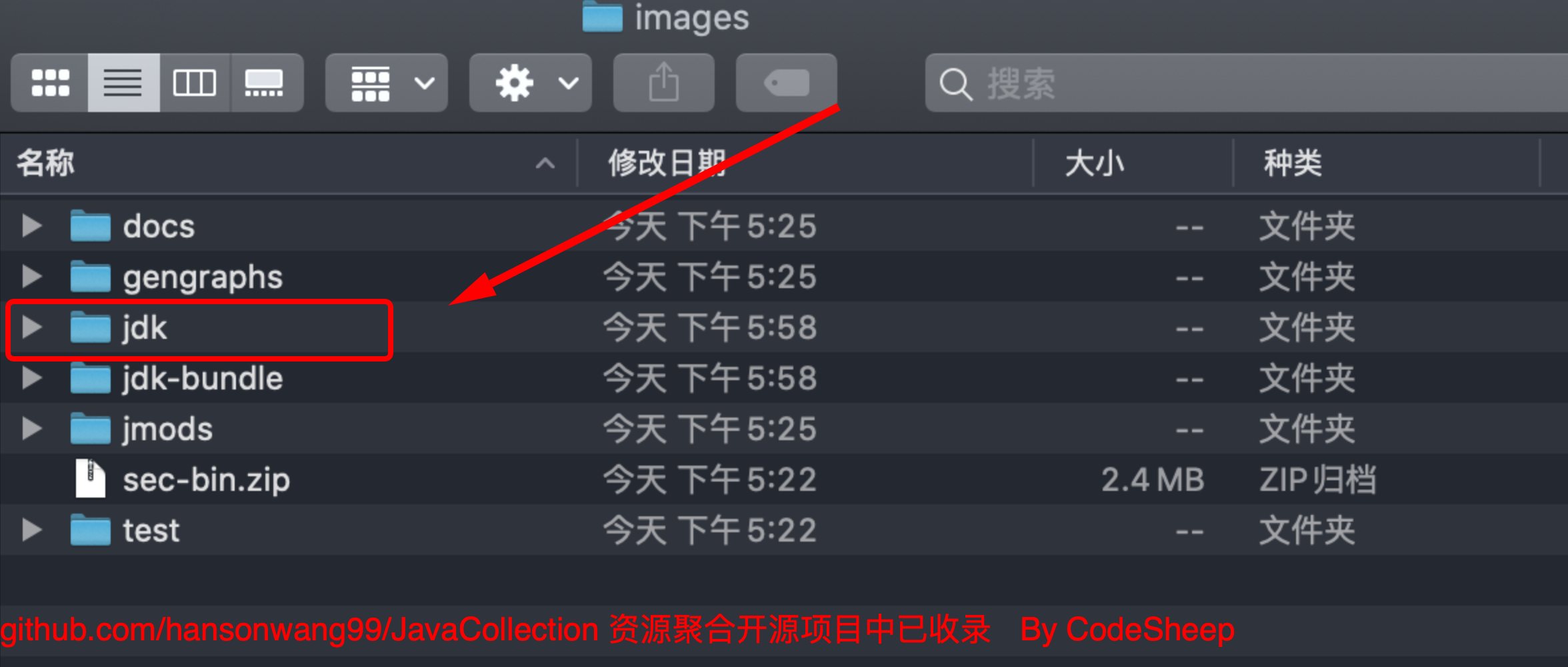
其次,编译生成的成品JDK套装,可以在目录
jdk源码根目录/build/macosx-x86_64-normal-server-release/images
下找到,如图所示:
![]()
其中:
-
j2sdk-image:编译生成的JDK
-
j2re-image:编译生成的JRE
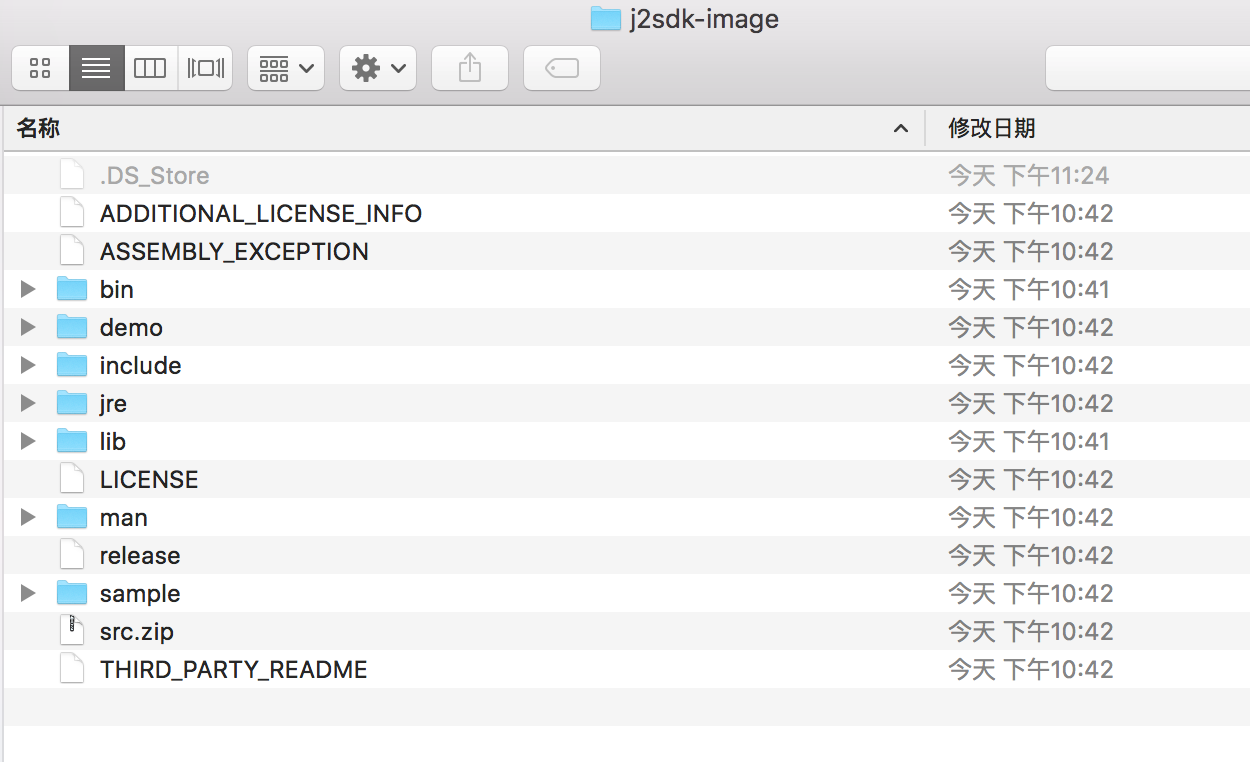
进入j2sdk-image目录会发现,里面的内容和我们平时从网络上下载的成品JDK内容一致。
![]()
2、JDK 11的编译输出
JDK 11的源码目录组织方式和JDK 8本身就有区别,编译生成的产物和上面编译JDK 8的输出有一定区别,但也不大。
JDK 11编译完成,同样在build目录下会生成一个macosx-x86_64-normal-server-release目录,所有的编译成果均位于其中。
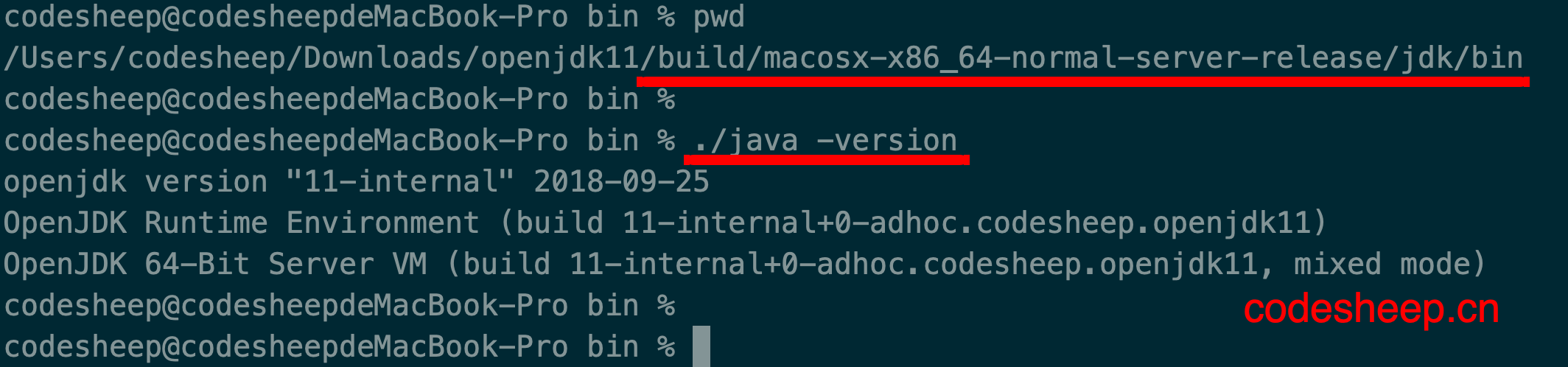
同样编译出来的Java可执行程序可以在目录
JDK源码根目录/build/macosx-x86_64-normal-server-release/jdk/bin
下看到,进入该目录后,也可以输入./java -version命令验证:
![]()
其次,编译生成的成品JDK 11套装,可以在目录
JDK源码根目录/build/macosx-x86_64-normal-server-release/images
下找到,如图所示:
![]()
其中jdk目录就是编译生成的成品JDK 11套装。
使用自己编译的JDK
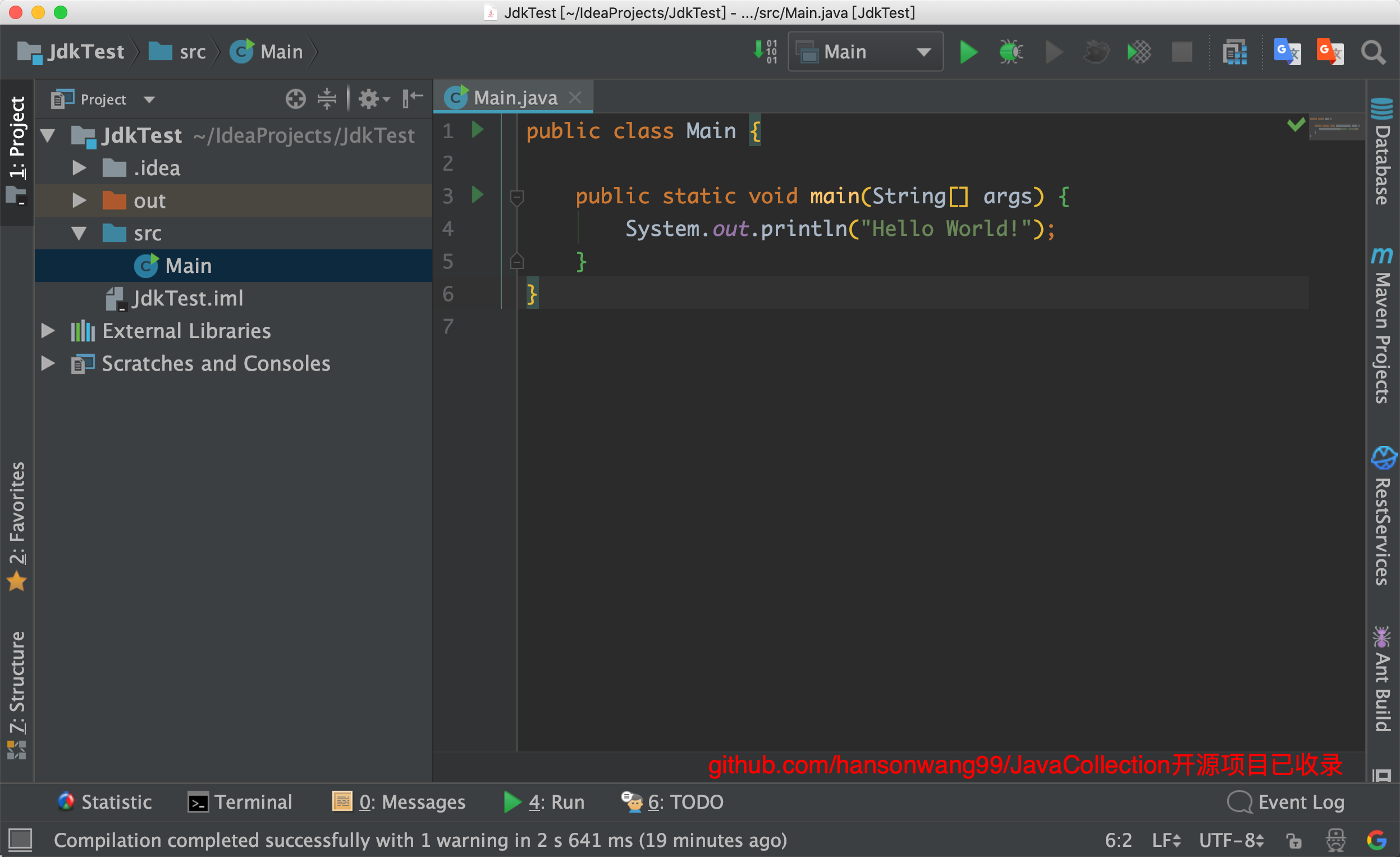
既然我们已经动手编译出了JDK成品,接下来我们得用上哇。
新建一个最最基本的Java工程,比如命名为JdkTest,目的是把我们自己编译出的JDK给用上。
![]()
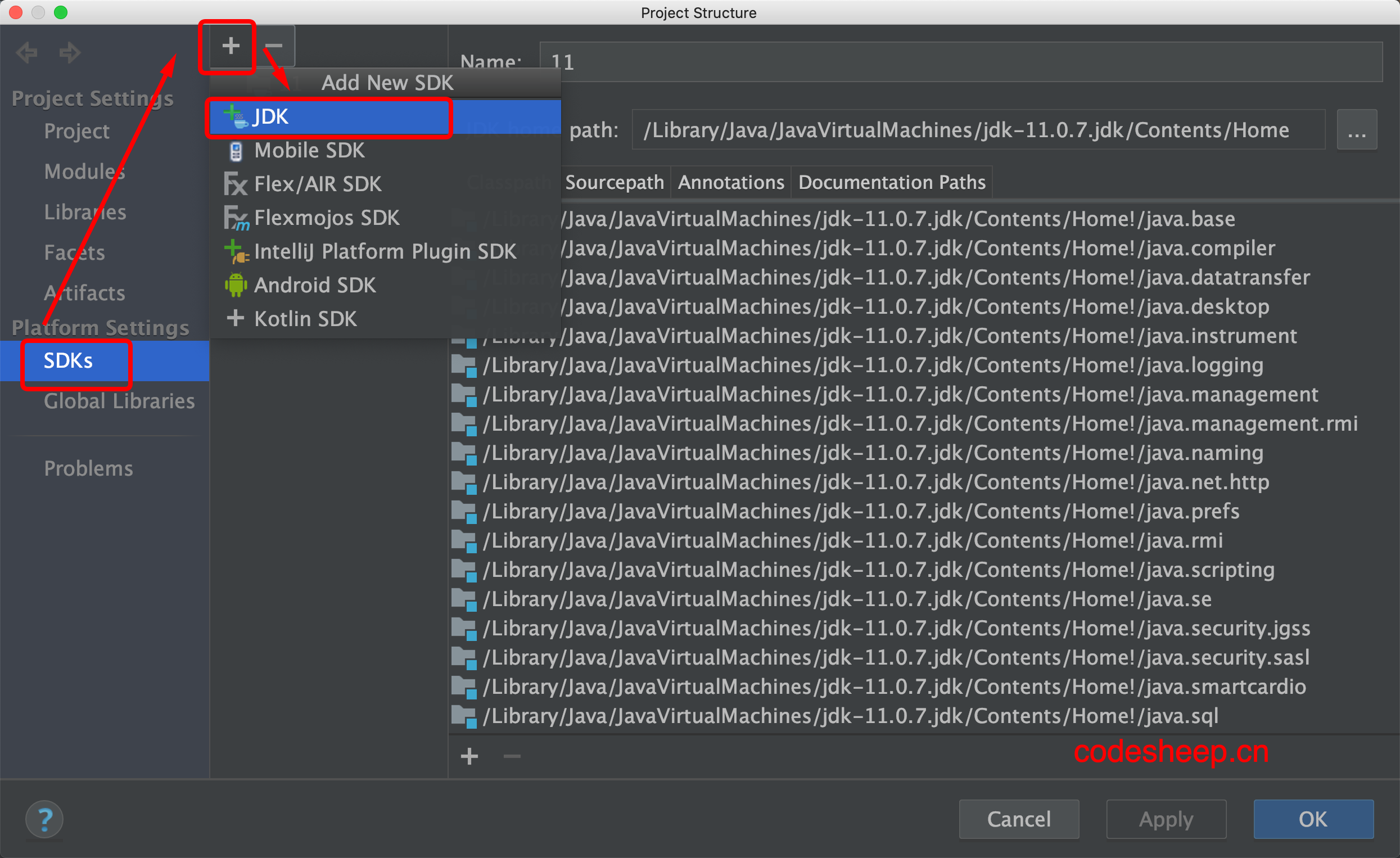
我们点开Project Structure,选到SDKs选项,新添加上自己刚刚编译生成的JDK,并选为项目的JDK,看看是否能正常工作
![]()
![]()
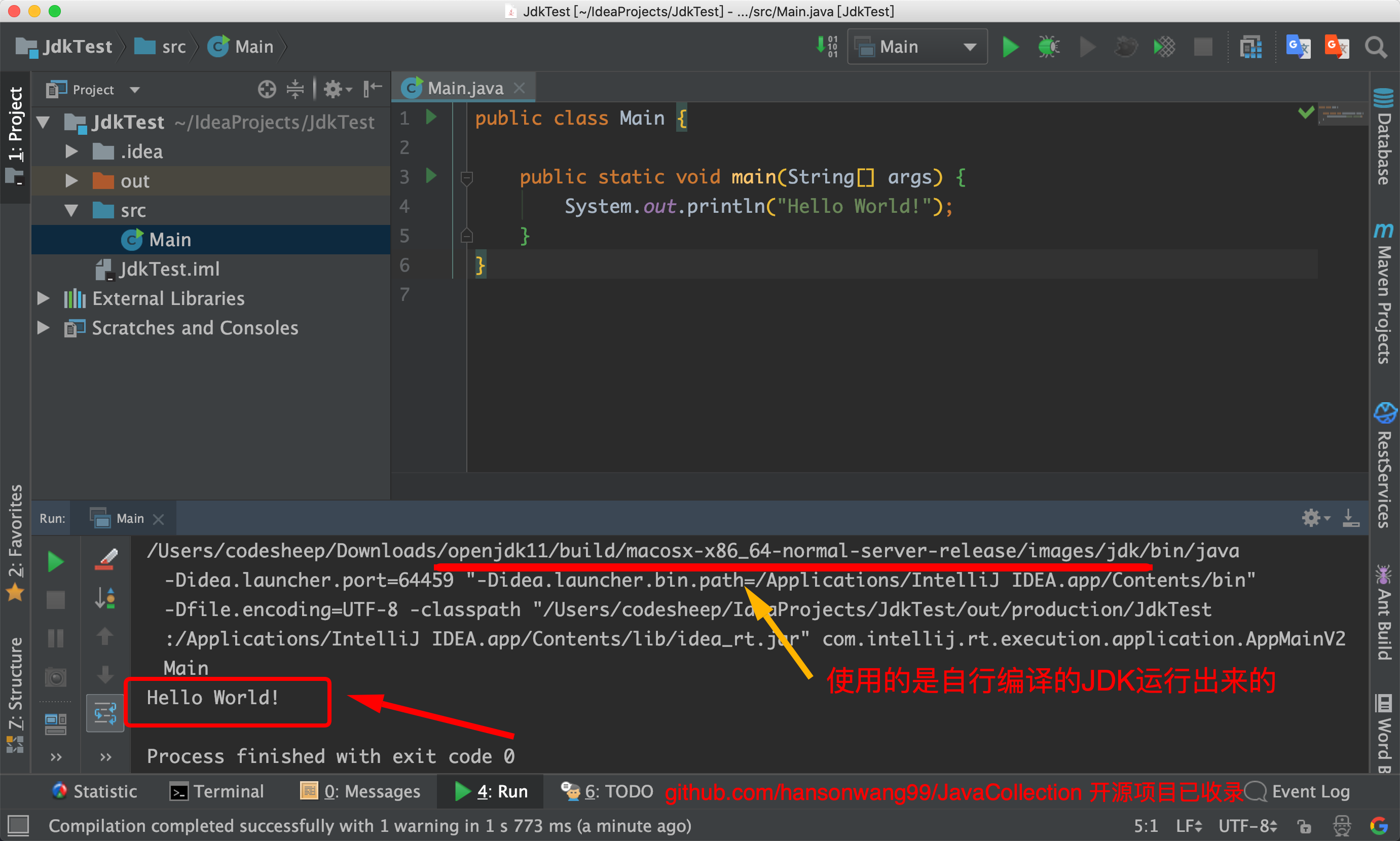
点击确定之后,我们运行之:
![]()
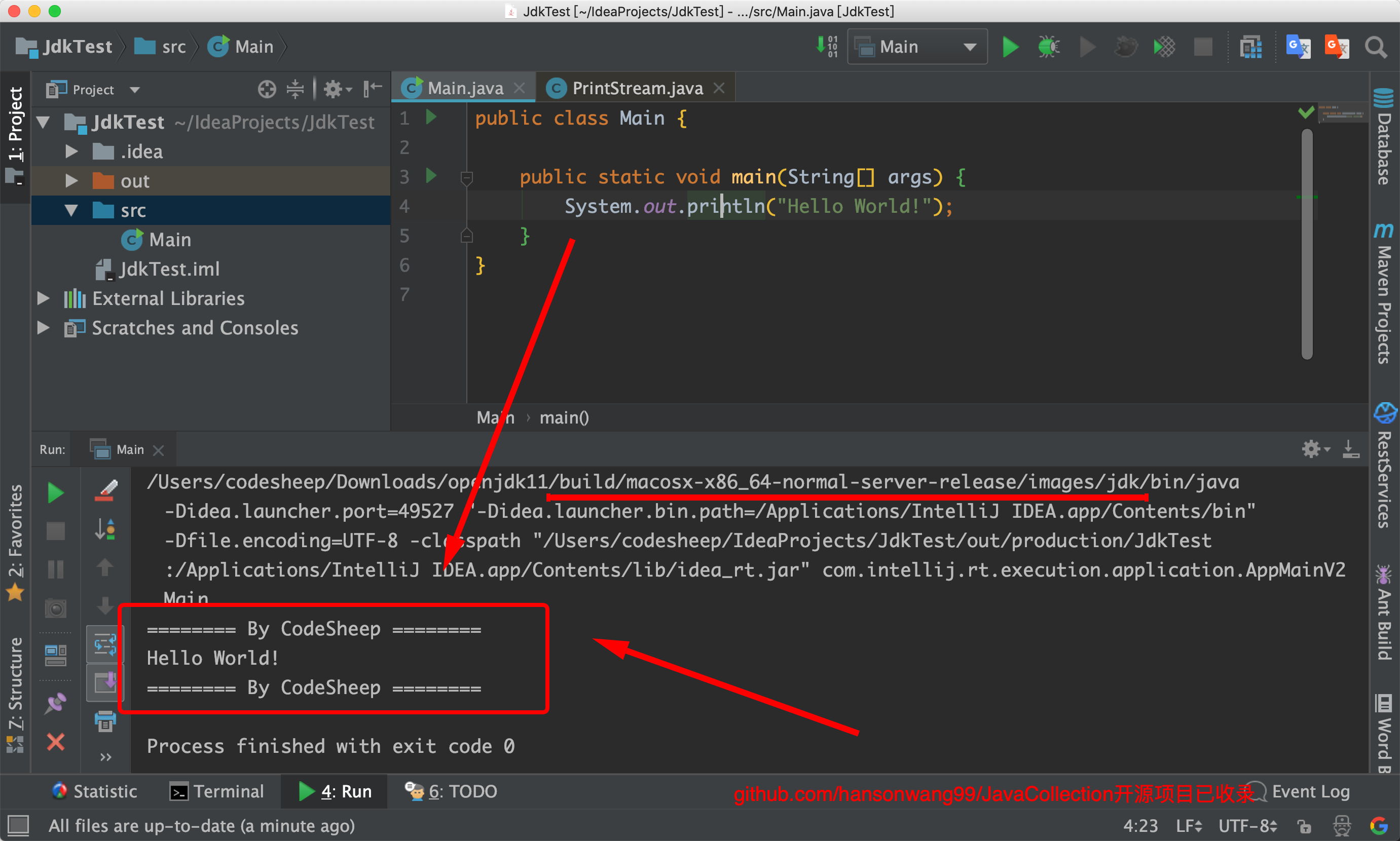
可以看到我们自己编译出的JDK已经用上了。
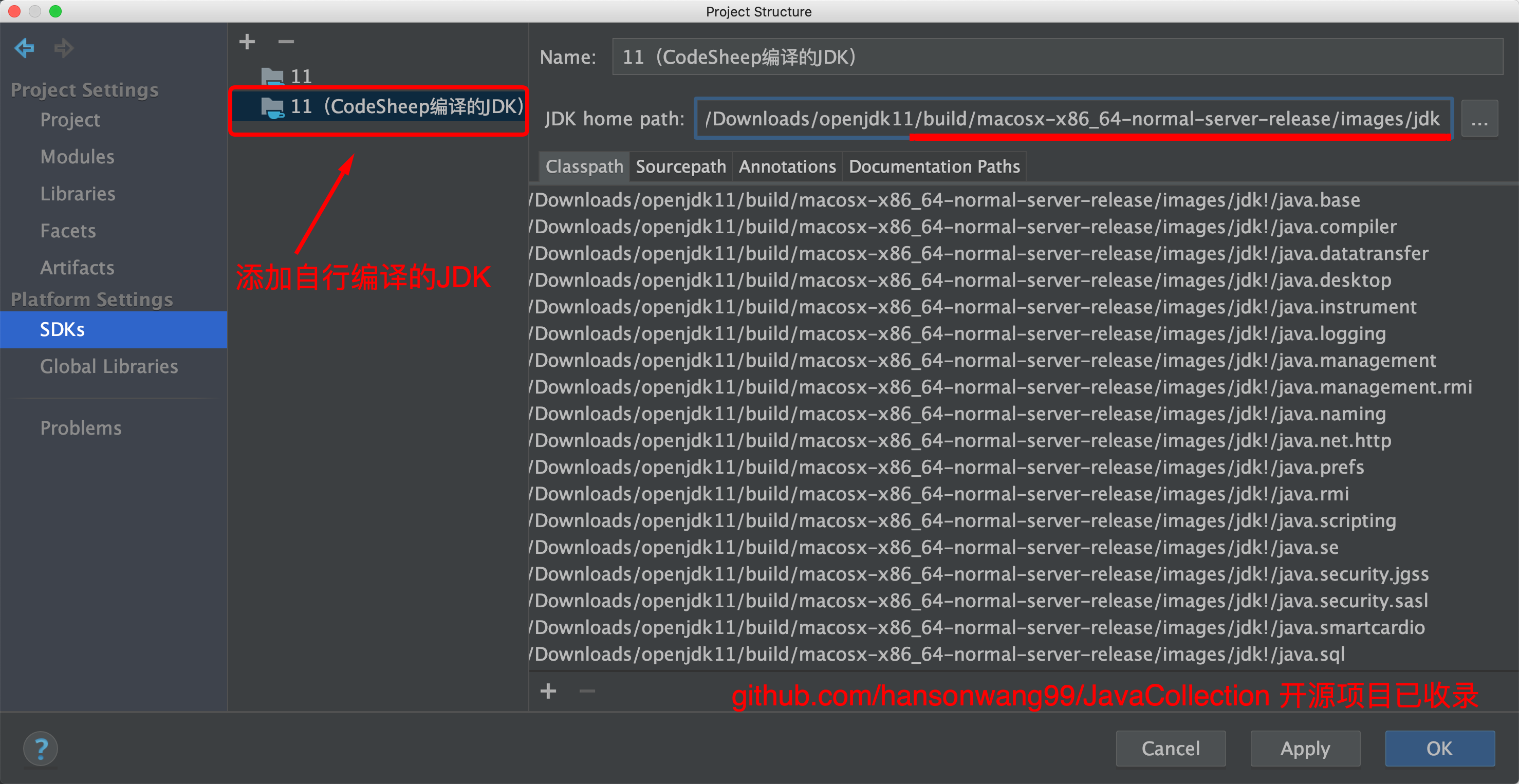
关联JDK源码并修改
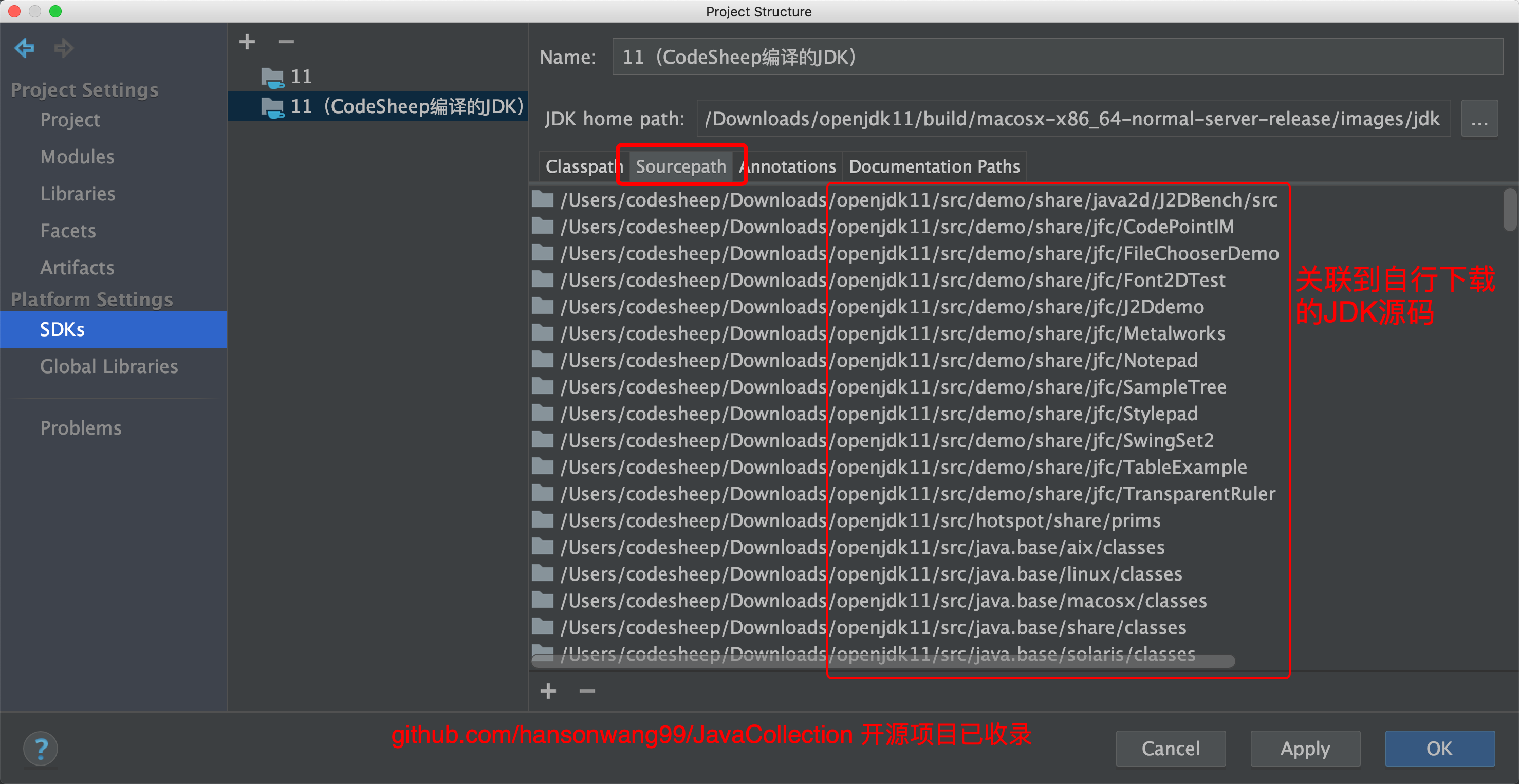
我们继续在上一步JdkTest项目的Project Structure → SDKs里将JDK源码关联到自行下载的JDK源码路径上:
![]()
这样方便我们对自己下载的JDK源码进行阅读、调试、修改、以及在源码里随意做笔记和加注释。
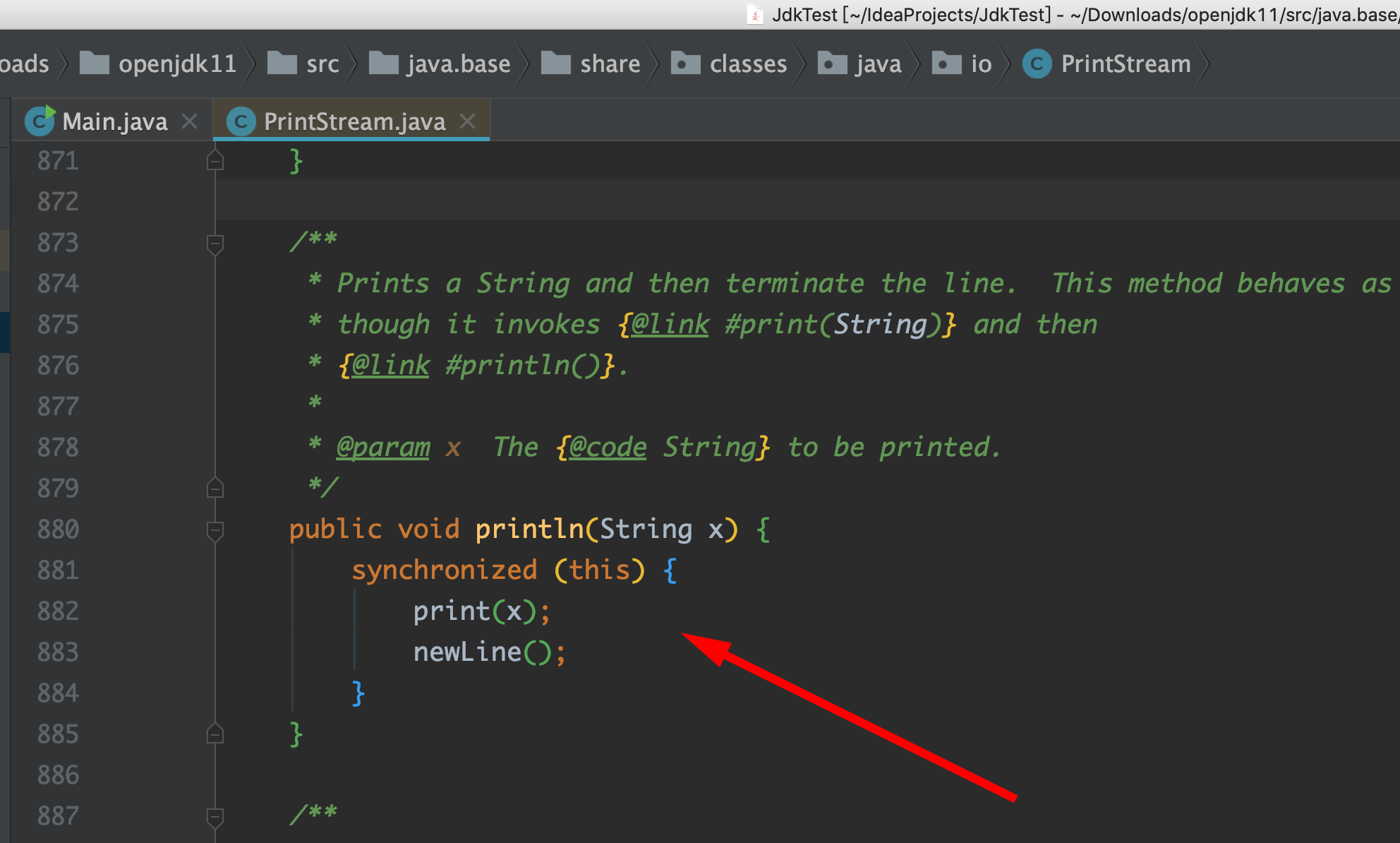
举个最简单的例子,比如我们打开System.out.println()这个函数的底层源码:
![]()
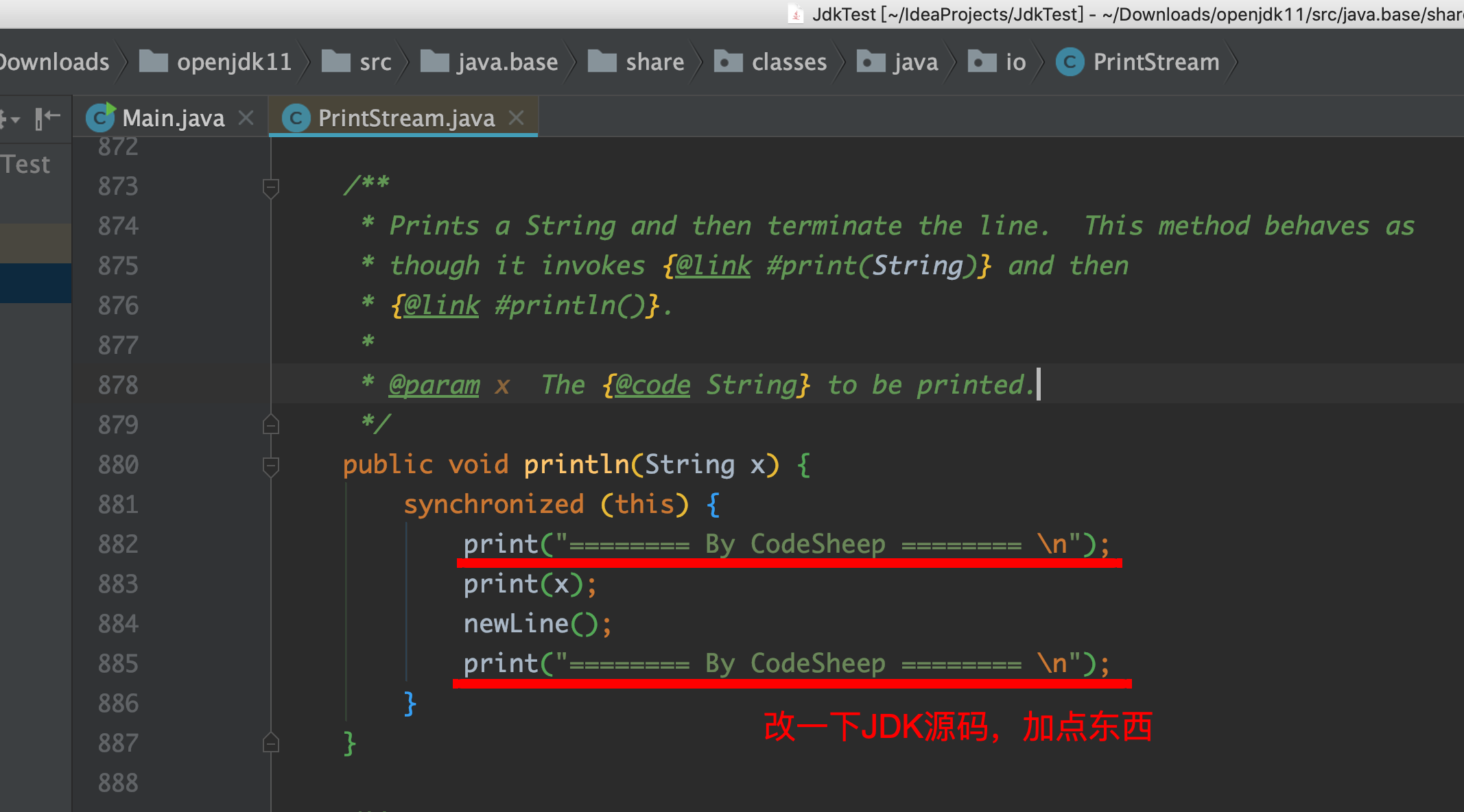
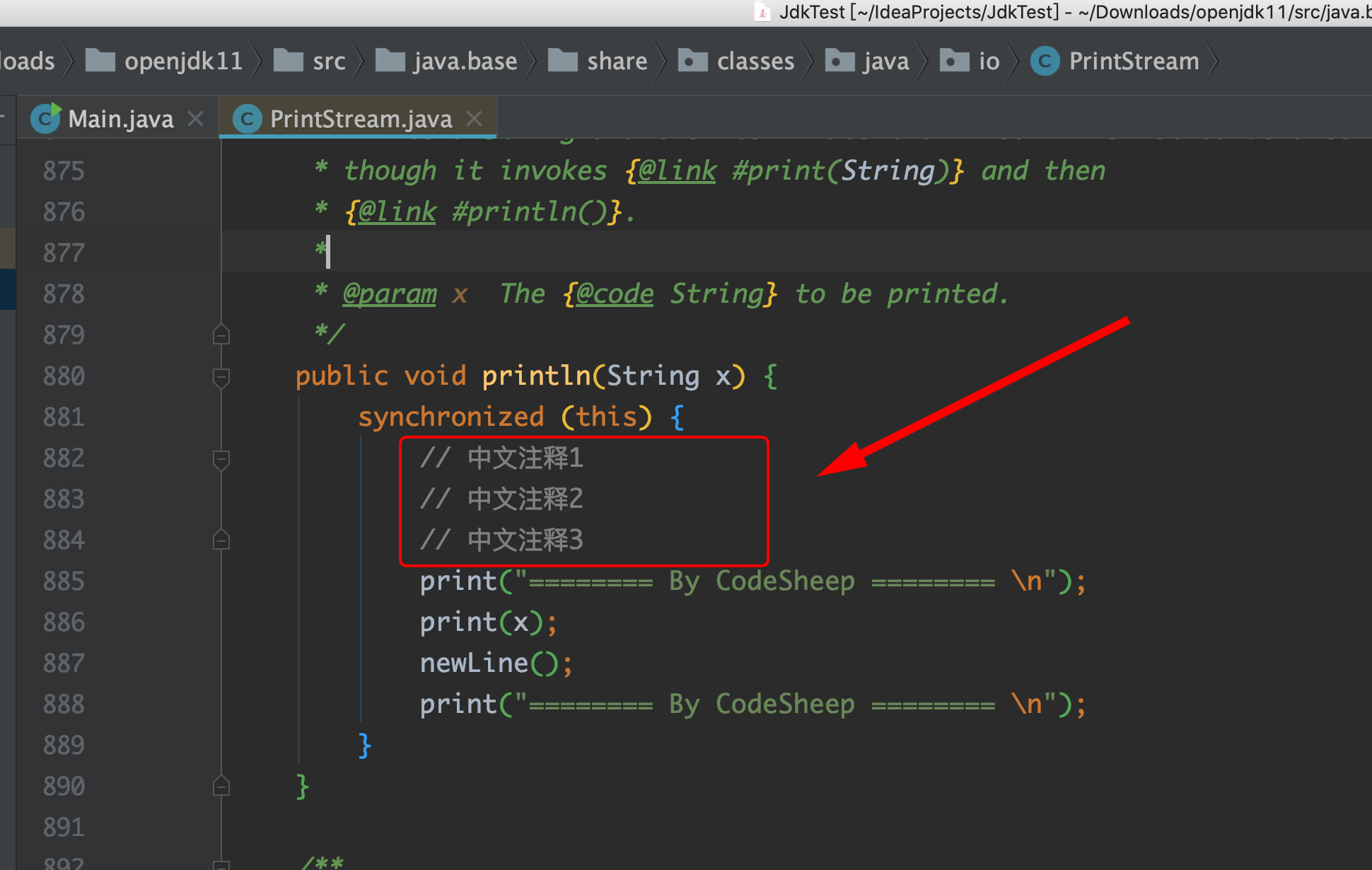
我们随便给它修改一下,加两行简单的标记,像这样:
![]()
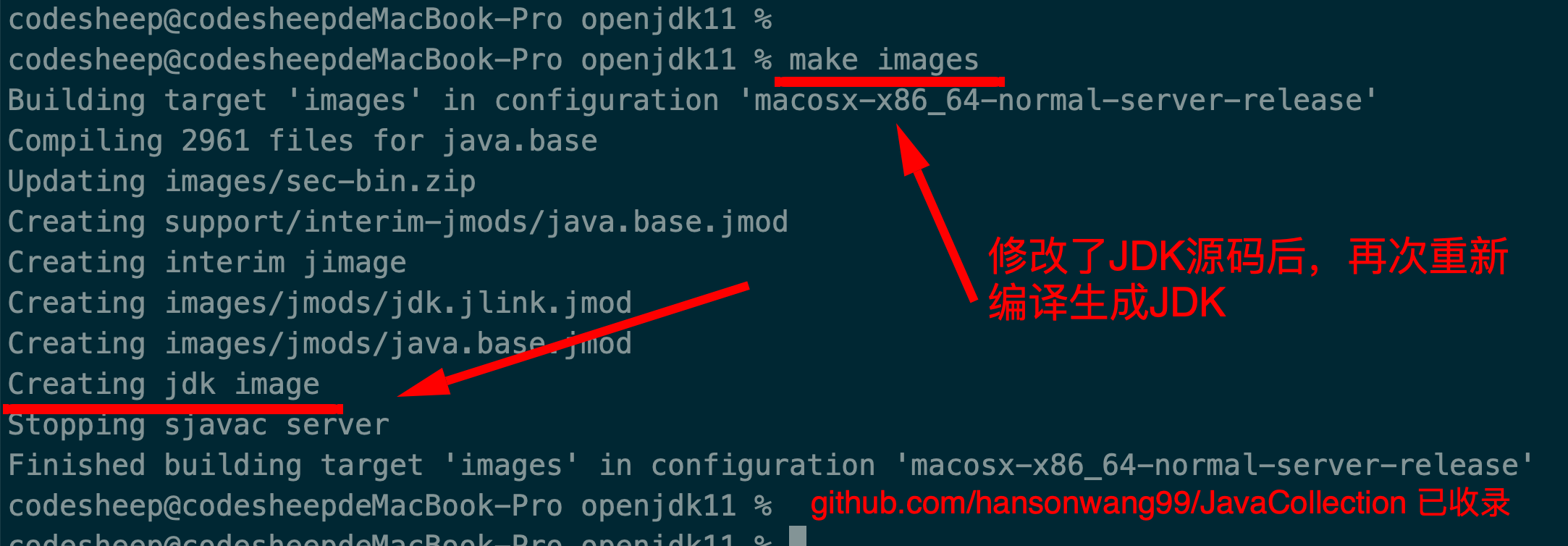
为了使我们新加的代码行生效,我们必须要重新去JDK源码的根目录中再次执行 make images重新编译生成JDK方可生效:
![]()
因为之前已经全量编译过了,所以再次make的时候增量编译一般很快。
重新编译之后,我们再次运行JdkTest项目,就可以看到改动的效果了:
![]()
多行注释的问题
记得之前搭建《JDK源码阅读环境》时,大家可能发现了一个问题:阅读源码嘛,给源代码做点注释或笔记很常见!但那时候有个问题就是做注释时不可改变代码的行结构(只能行尾注释,不能跨行注释),否则debug调试时会出现行号错位的问题。
原因很简单,因为我们虽然做了源代码目录的映射,但是实际支撑运行的JDK还是预先安装好的那个JDK环境,并不是根据我们修改后的源码来重新编译构建的,所以看到这里,解决这个问题就很简单,就像上面一样自行编译一下JDK即可。
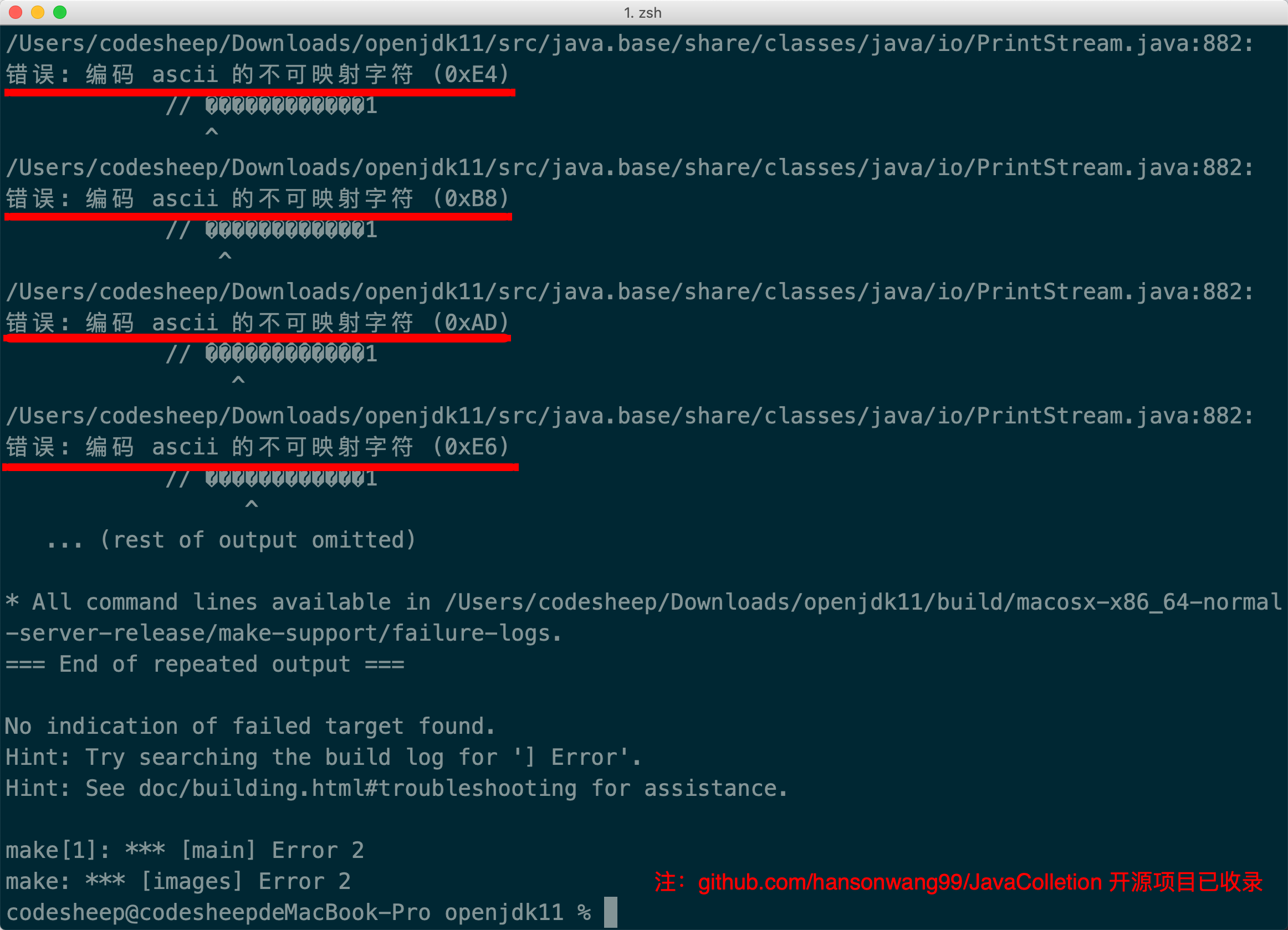
实际在实验时,还有一个很典型的问题是,当添加了多行的中文注释后,再编译居然会报错!
比如,还是以上面例子中最简单的System.out.println()源码为例,我们添加几行中文注释:
![]()
这时候我们去JDK源码目录下编译会发现满屏类似这样的报错:
错误: 编码 ascii 的不可映射字符
![]()
顿时有点懵,毕竟仅仅是加了几行注释。对于我们来说,源码里写点多行的中文注释基本是刚需,然而编译竟会报错,这还能不能让人愉快的玩耍了... 当时后背有点发凉。
实不相瞒,就这个问题排查了一段时间,熬到了很晚。最终折腾了一番,通过如下这种方式解决了,顺便分享给小伙伴们,大家如果遇到了这个问题,可以参考着解决一下。
因为从控制台的报错可以很明显的看出,肯定是字符编码相关的问题导致的,而且都指向了ascii这种编码方式。
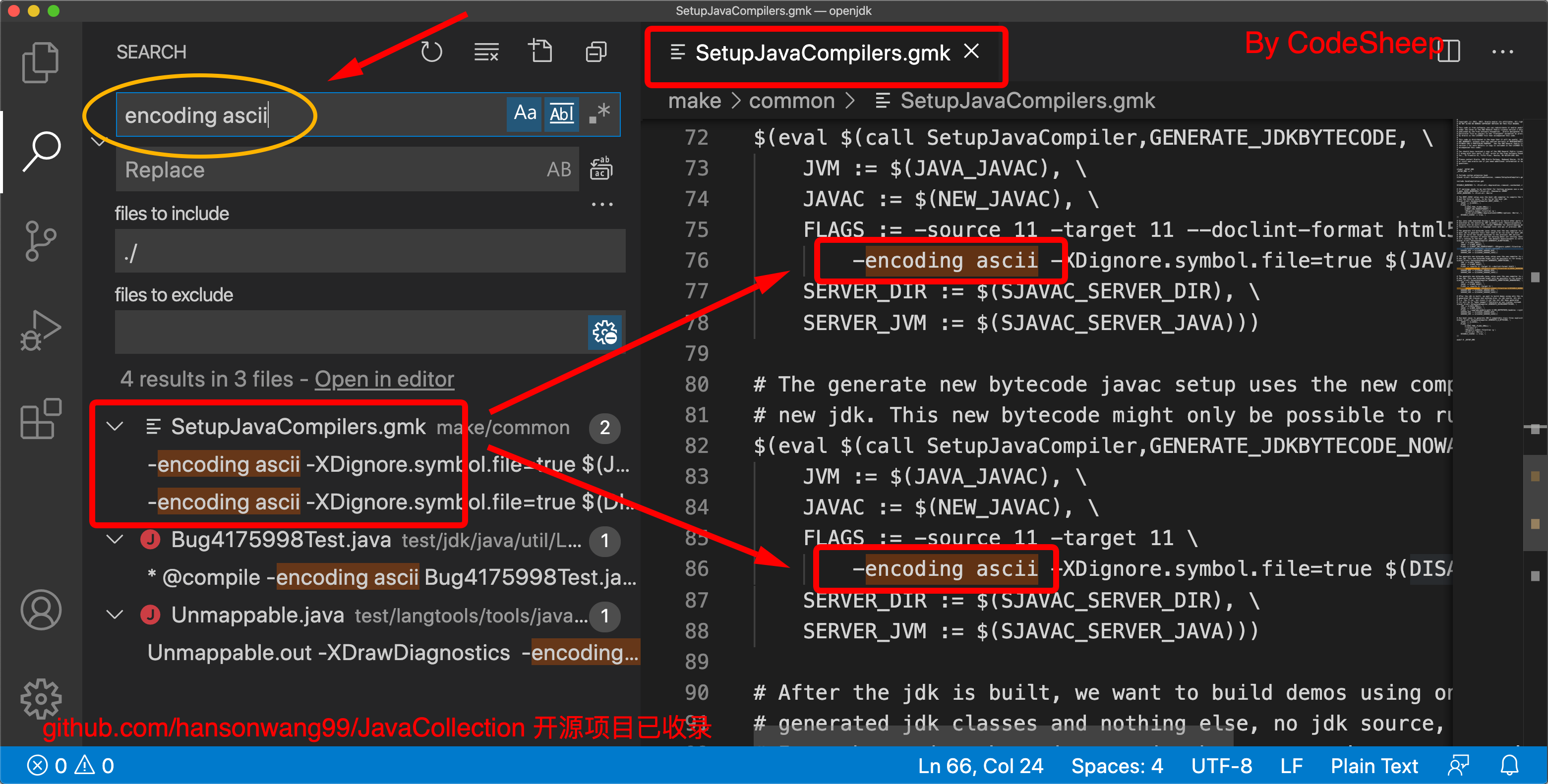
于是将JDK的源码从根目录导入了Vs Code,然后全目录查找encoding ascii相关的内容,看看有没有什么端倪,结果发现
jdk源码根目录/make/common/SetupJavaCompilers.gmk文件中有两处指定了ascii相关的编码方式:
![]()
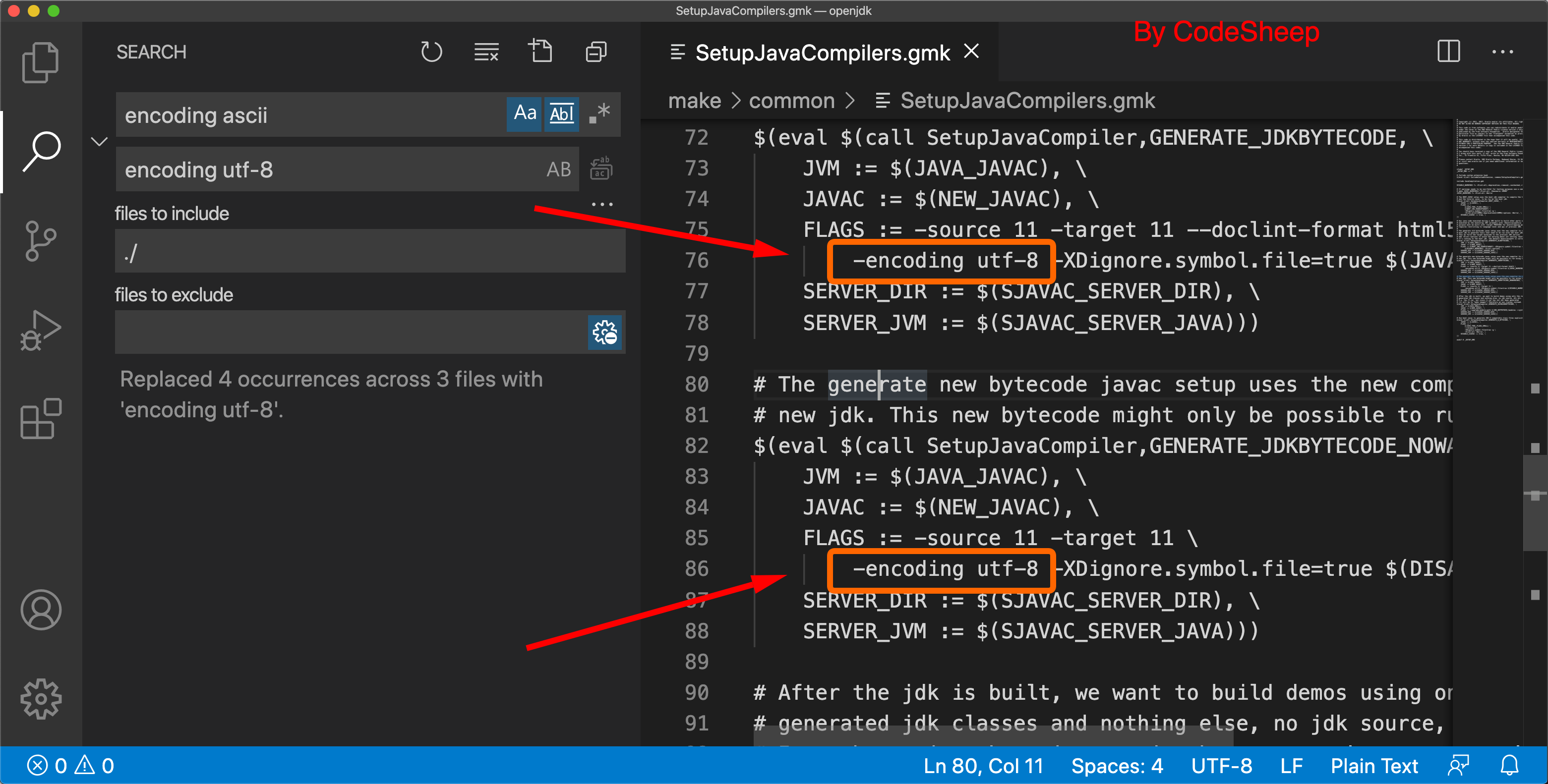
于是尝试将这两处-encoding ascii的均替换成-encoding utf-8:
![]()
然后再次执行make images编译,编译顺利通过!
![]()
至此大功告成!
这样后面不管是阅读、调试还是定制JDK源码都非常方便了。
后记:这篇文章在开源项目:https://github.com/hansonwang99/JavaCollection 中也已经收录了,包含自学编程路线、面试题集合/面经、及系列技术文章等,资源持续更新中...
每天进步一点点
慢一点才能更快