至2020年3月,我国短视频用户规模为7.73亿,占网民整体的85.6%,每天有大量 UGC 短视频被生产、分发和消费。如果你是一名短视频用户一定会发现,这些 App 总是特别懂你的心思,比如一些美食短视频就总能在合适的时间、推荐合适的菜谱,让小伙伴们不必为晚餐吃什么而发愁。让你不仅暗自感叹,它为什么如此懂自己?
![]()
之所以这些短视频 App 可以如此懂自己,得益于人工智能的视频分类技术。高效的视频分类技术让信息的分发更快地触及目标人群,让 App 变得更有温度。
面对海量的视频数据,如何推荐用户感兴趣的视频?
互联网视频分类任务的目标是理解视频的语义,并给视频打上标签,标签包括不限于美食、旅游、影视、游戏等等。标签越精细、在视频分发和推荐时,准确率越高。
熟悉深度学习的同学们都知道,数据集对于算法的研究起着非常重要的作用。对于视频分类任务而言,网络上虽然有大量用户上传的视频数据,但它们大多缺少类别标签,无法直接用于模型训练。在学术界,Kinetics 系列是最热门的视频分类数据集,但其数据量(以Kinetics-400为例,包含23万个视频)与当前国内主流APP的数据量(千万/亿/十亿量级)相比较,也是云泥之别,且视频内容与互联网短视频也存在较大差异。
此外,视频中包含成百上千帧图像,处理这些帧图像需要大量的计算。基于 TSN、TSM、SlowFast 视频分类模型,使用 Kinetics-400 数据,模型训练大概需要1周才能达到70%~80%的Top-1精度,面对上千万的数据量,显然学术界模型是无法实现产业应用的。
飞桨大规模视频分类模型 VideoTag 基于百度短视频业务千万级数据,在训练速度上进行了全面升级;支持3000个源于产业实践的实用标签;引入 ActivityNet 冠军模型 Attention Cluster 等,在测试集上达到90%的精度;具备良好的泛化能力,非常适用于国内大规模(千万/亿/十亿级别)短视频分类场景的应用。
当前飞桨 VideoTag 模型全面开源开放,欢迎感兴趣的企业和开发者试用,
如果您想使用 PaddleHub 快速实现模型预测(VideoTag 预训练模型已经集成到PaddleHub中),Gitee地址:https://gitee.com/PaddlePaddle/PaddleHub/tree/release/v1.7/hub_module/modules/video/classification/videotag_tsn_lstm
如果您想 Fine-tune 或了解更多的 VideoTag 模型实现细节,可以下载模型完整代码,Gitee地址:https://gitee.com/PaddlePaddle/models/tree/develop/PaddleCV/video/application/video_tag
除此之外,飞桨还为开发者和各类企业提供了更多人工智能的产业实践,填写下方的表单,即可详细了解您企业所在的行业如何使用飞桨让业务更上一层楼:https://jinshuju.net/f/zL637q
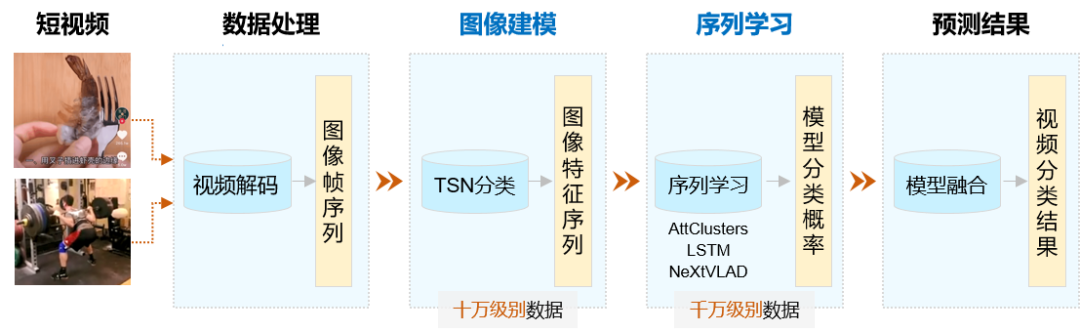
考虑到国内主流APP视频数据量巨大,为了提升模型训练速度,VideoTag采用两阶段建模方式,即图像建模和序列学习。第一阶段,使用少量视频样本(十万级别)训练大规模视频特征提取模型;第二阶段,使用千万级数据进行序列学习,最终实现在超大规模(千万/亿/十亿级别)短视频上产业应用,其原理示意如下图所示。
![]()
之所以这些短视频 App 可以如此懂自己,得益于人工智能的视频分类技术。高效的视频分类技术让信息的分发更快地触及目标人群,让 App 变得更有温度。
面对海量的视频数据,如何推荐用户感兴趣的视频?
互联网视频分类任务的目标是理解视频的语义,并给视频打上标签,标签包括不限于美食、旅游、影视、游戏等等。标签越精细、在视频分发和推荐时,准确率越高。
熟悉深度学习的同学们都知道,数据集对于算法的研究起着非常重要的作用。对于视频分类任务而言,网络上虽然有大量用户上传的视频数据,但它们大多缺少类别标签,无法直接用于模型训练。在学术界,Kinetics 系列是最热门的视频分类数据集,但其数据量(以Kinetics-400为例,包含23万个视频)与当前国内主流APP的数据量(千万/亿/十亿量级)相比较,也是云泥之别,且视频内容与互联网短视频也存在较大差异。
此外,视频中包含成百上千帧图像,处理这些帧图像需要大量的计算。基于 TSN、TSM、SlowFast 视频分类模型,使用 Kinetics-400 数据,模型训练大概需要1周才能达到70%~80%的Top-1精度,面对上千万的数据量,显然学术界模型是无法实现产业应用的。
飞桨大规模视频分类模型 VideoTag 基于百度短视频业务千万级数据,在训练速度上进行了全面升级;支持3000个源于产业实践的实用标签;引入 ActivityNet 冠军模型 Attention Cluster 等,在测试集上达到90%的精度;具备良好的泛化能力,非常适用于国内大规模(千万/亿/十亿级别)短视频分类场景的应用。
当前飞桨 VideoTag 模型全面开源开放,欢迎感兴趣的企业和开发者试用,
如果您想使用 PaddleHub 快速实现模型预测(VideoTag 预训练模型已经集成到PaddleHub中),Gitee地址:https://gitee.com/PaddlePaddle/PaddleHub/tree/release/v1.7/hub_module/modules/video/classification/videotag_tsn_lstm
如果您想 Fine-tune 或了解更多的 VideoTag 模型实现细节,可以下载模型完整代码,Gitee地址:https://gitee.com/PaddlePaddle/models/tree/develop/PaddleCV/video/application/video_tag
除此之外,飞桨还为开发者和各类企业提供了更多人工智能的产业实践,填写下方的表单,即可详细了解您企业所在的行业如何使用飞桨让业务更上一层楼:https://jinshuju.net/f/zL637q
考虑到国内主流APP视频数据量巨大,为了提升模型训练速度,VideoTag采用两阶段建模方式,即图像建模和序列学习。第一阶段,使用少量视频样本(十万级别)训练大规模视频特征提取模型;第二阶段,使用千万级数据进行序列学习,最终实现在超大规模(千万/亿/十亿级别)短视频上产业应用,其原理示意如下图所示。
![]()
让我们看看模型预测的结果:
![]()
模型取出了排名较前的几个分类结果,分别是“训练”、“蹲”、“杠铃”、“健身房”。其中分类的置信度均超过了0.8,网络预测出来的标签也和事实相一致。
PaddleHub提供了更加灵活的API预测方式,可以同时处理多个文件。
import paddlehub as hub
videotag = hub.Module(name="videotag_tsn_lstm")
# 一行代码完成模型预测,paths可接收多个自定义文件路径
results = videotag.classify(paths=["1.mp4","2.mp4"], use_gpu=False)
print(results)
示例的2.mp4的内容截图如下所示:
![]()
模型取出了分类结果“舞蹈”,分类的置信度均超过了0.85,网络预测出来的标签也和事实相一致。
![]()
事实上,该模型对场景的预测标签有多达3396种,包括了如超市、实验、机场等地点,或者是医生、教师等人物。可以说,这些标签足够达到我们日常小视频分类的要求,能够很好的处理我们需要的场景。
无论您是从业者、学生或者深度学习爱好者,在大规模短视频分类任务上,有飞桨 VideoTag 预训练模型加持,都会有助于产品用户体验的提升,增加用户粘性。
除此之外,飞桨还为开发者和各类企业提供了更多人工智能的产业实践,填写下方的表单,即可详细了解您企业所在的行业如何使用飞桨让业务更上一层楼:https://jinshuju.net/f/zL637q