在拥有大量并发用户的系统中,热key一直以来都是一个不可避免的问题。或许是突然某些商品成了爆款,或许是海量用户突然涌入某个店铺,或许是秒杀时瞬间大量开启的爬虫用户, 这些突发的无法预先感知的热key都是系统潜在的巨大风险。
风险是什么呢?主要是数据层,其次是服务层。
热key对数据层的冲击显而易见,譬如数据存放在redis或者MySQL中,以redis为例,那个未知的热数据会按照hash规则被存在于某个redis分片上,平时使用时都从该分片获取它的数据。由于redis性能还不错,再加上集群模式,每秒我们假设它能支撑20万次读取,这足以支持大部分的日常使用了。但是,以京东为例的这些头部互联网公司,动辄某个爆品,会瞬间引入每秒上百万甚至数百万的请求,当然流量多数会在几秒内就消失。但就是这短短的几秒的热key,就会瞬间造成其所在redis分片集群瘫痪。原因也很简单,redis作为一个单线程的结构,所有的请求到来后都会去排队,当请求量远大于自身处理能力时,后面的请求会陷入等待、超时。由于该redis分片完全被这个key的请求给打满,导致该分片上所有其他数据操作都无法继续提供服务,也就是热key不仅仅影响自己,还会影响和它合租的数据。很显然,在这个极短的时间窗口内,我们是无法快速扩容10倍以上redis来支撑这个热点的。虽然redis已经很优秀,但面对这种场景时,往往也是redis成为最大的瓶颈。
热key对服务层的影响也不可小视,譬如你原本有1000台Tomcat,每台每秒能支撑1000QPS,假设数据层稳定、这样服务层每秒能承接100万个请求。但是由于某个爆品的出现、或者由于大促优惠活动,突发大批机器人以远超正常用户的速度发起极其密集的请求,这些机器人只需要很小的代价就能发出百倍于普通用户的请求量,从而大幅挤占正常用户的资源。原本能承接100万,现在来了150万,其中50万个是机器人请求,那么就导致了至少1/3的正常用户无法访问,带来较差的用户体验。
根据以上的场景,我们可以总结出来什么是有危害的热key。
什么是热key
1 、MySQL等数据库会被频繁访问的热数据
如爆款商品的skuId。
2 、redis的被密集访问的key
如爆款商品的各维度信息,skuId、shopId等。
3 、机器人、爬虫、刷子用户
如用户的userId、uuid、ip等。
4 、某个接口地址
如/sku/query或者更精细维度的。
5、 用户id+接口信息
如userId + /sku/query,这代表某个用户访问某个接口的频率。
6 、服务器id+接口信息
如ip + /sku/query,这代表某台服务器某个接口被访问的频率。
7 、用户id+接口信息+具体商品
如userId + /sku/query + skuId,这代表某个用户访问某个商品的频率。
以上我们都称之为有风险的key,注意,我们的热key探测框架只关心key,其实就是一个字符串,随意怎么组合成这个字符串由使用者自己决定,所以该框架具备非常强的灵活性,可以完成热数据探测、限流熔断、统计等多种功能。
以往热key问题怎么解决
我们分别以redis的热key、刷子用户、限流等典型的场景来看。
redis热key:
这种以往的解决方式比较百花齐放,比较常见的有:
1)上二级缓存,读取到redis的key-value信息后,就直接写入到jvm缓存一份,设置个过期时间,设置个淘汰策略譬如队列满时淘汰最先加入的。或者使用guava cache或caffeine cache进行单机本地缓存,整体命中率偏低。
2)改写redis源码加入热点探测功能,有热key时推送到jvm。问题主要是不通用,且有一定难度。
3)改写jedis、letture等redis客户端的jar,通过本地计算来探测热点key,是热key的就本地缓存起来并通知集群内其他机器。
4)其他
刷子爬虫用户:
常见的有:
1)日常累积后,将这批黑名单通过配置中心推送到jvm内存。存在滞后无法实时感知的问题。
2)通过本地累加,进行实时计算,单位时间内超过阈值的算刷子。如果服务器比较多,存在用户请求被分散,本地计算达不到甄别刷子的问题。
3)引入其他组件如redis,进行集中式累加计算,超过阈值的拉取到本地内存。问题就是需要频繁读写redis,依旧存在redis的性能瓶颈问题。
限流:
1)单机维度的接口限流多采用本地累加计数
2)集群维度的多采用第三方中间件,如sentinel
3)网关层的,如Nginx+lua
综上,我们会发现虽然它们都可以归结到热key这个领域内,但是并没有一个统一的解决方案,我们更期望于有一个统一的框架,它能解决所有的对热key有实时感知的场景,最好是无论是什么key、是什么维度,只要我拼接好这个字符串,把它交给框架去探测,设定好判定为热的阈值(如2秒该字符串出现20次),则毫秒时间内,该热key就能进入到应用的jvm内存中,并且在整个服务集群内保持一致性,要有都有,要删全删。
热key进内存后的优势
热key问题归根到底就是如何找到热key,并将热key放到jvm内存的问题。只要该key在内存里,我们就能极快地来对它做逻辑,内存访问和redis访问的速度不在一个量级。
譬如刷子用户,我们可以对其屏蔽、降级、限制访问速度。热接口,我们可以进行限流,返回默认值。redis的热key,我们可以极大地提高访问速度。
以redis访问key为例,我们可以很容易的计算出性能指标,譬如有1000台服务器,某key所在的redis集群能支撑20万/s的访问,那么平均每台机器每秒大概能访问该key200次,超过的部分就会进入等待。由于redis的瓶颈,将极大地限制server的性能。
而如果该key是在本地内存中,读取一个内存中的值,每秒多少个万次都是很正常的,不存在任何数据层的瓶颈。当然,如果通过增加redis集群规模的形式,也能提升数据的访问上限,但问题是事先不知道热key在哪里,而全量增加redis的规模,带来的成本提升又不可接受。
热key探测关键指标
1、实时性
这个很容易理解,key往往是突发性瞬间就热了,根本不给你再慢悠悠手工去配置中心添加热key再推送到jvm的机会。它大部分时间不可预知,来得也非常迅速,可能某个商家上个活动,瞬间热key就出现了。如果短时间内没能进到内存,就有redis集群被打爆的风险。
所以热key探测框架最重要的就是实时性,最好是某个key刚有热的苗头,在1秒内它就已经进到整个服务集群的内存里了,1秒后就不会再去密集访问redis了。同理,对于刷子用户也一样,刚开始刷,1秒内我就把它给禁掉了。
2、准确性
这个很重要,也容易实现,累加数量,做到不误探,精准探测,保证探测出的热key是完全符合用户自己设定的阈值。
3、集群一致性
这个比较重要,尤其是某些带删除key的场景,要能做到删key时整个集群内的该key都会删掉,以避免数据的错误。
4、高性能
这个是核心之一,高性能带来的就是低成本,做热key探测目的就是为了降低数据层的负载,提升应用层的性能,节省服务器资源。不然,大家直接去整体扩充redis集群规模就好了。
理论上,在不影响实时性的情况下,要完成实时热key探测,所消耗的机器资源越少,那么经济价值就越大。
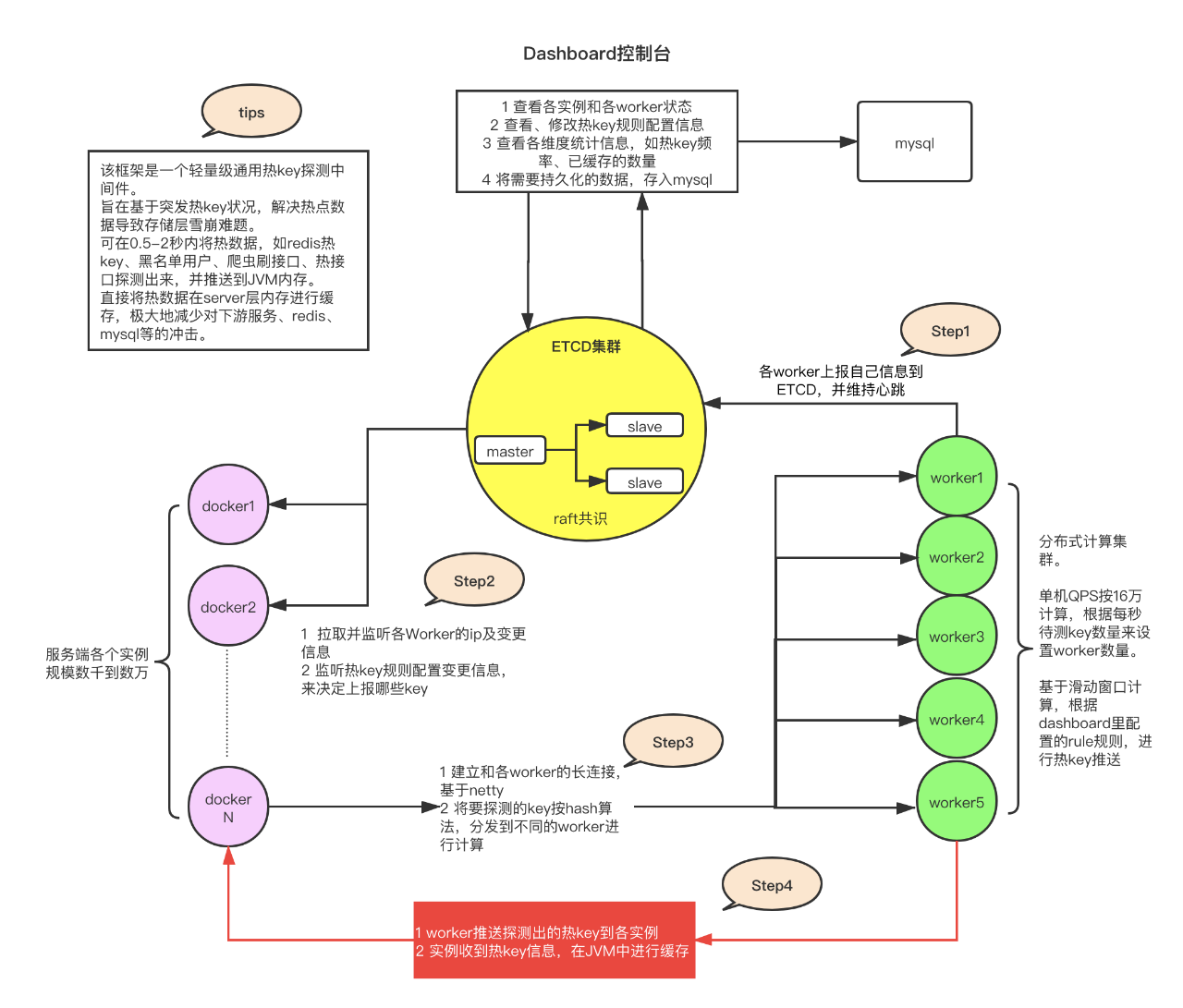
京东热key探测框架架构设计
在经历了多次被突发海量请求压垮数据层服务的场景,并时刻面临大量的爬虫刷子机器人用户的请求,我们根据既有经验设计开发了一套通用轻量级热key探测框架——JdHotkey。
它很轻量级,既不改redis源码也不改redis的客户端jar包,当然,它与redis没一点关系,完全不依赖redis。它是一个独立的系统,部署后,在server代码里引入jar,之后就像使用一个本地的HashMap一样来使用它即可。
框架自身会完成一切,包括对待测key的上报,对热key的推送,本地热key的缓存,过期、淘汰策略等等。框架会告诉你,它是不是个热key,其他的逻辑交给你自己去实现即可。
它有很强的实时性,默认情况下,500ms即可探测出待测key是否热key,是热key它就会进到jvm内存中。当然,我们也提供了更快频率的设置方式,通常如果非极端场景,建议保持默认值就好,更高的频率带来了更大的资源消耗。
它有着强悍的性能表现,一台8核8G的机器,在承担该框架热key探测计算任务时(即下面架构图里的worker服务),每秒可以处理来自于数千台服务器发来的高达16万个的待测key,8核单机吞吐量在16万,16核机器每秒可达30万以上探测量,当然前提是cpu很稳定。高性能代表了低成本,所以我们就可以仅仅采用10台机器,即可完成每秒近300万次的key探测任务,一旦找到了热key,那该数据的访问耗时就和redis不在一个数量级了。如果是加redis集群呢?把QPS从20万提升到200万,我们又需要扩充多少台服务器呢? ![]()
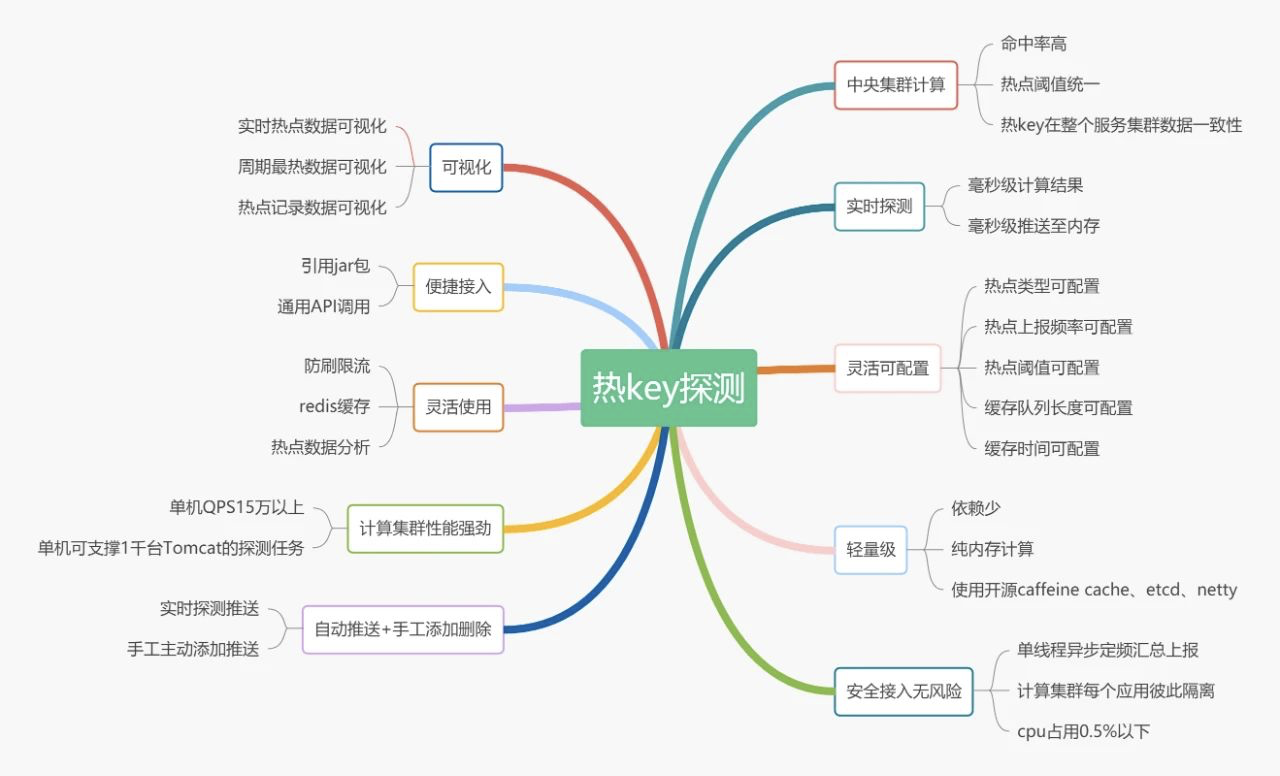
该框架主要由4个部分组成
1、etcd集群
etcd作为一个高性能的配置中心,可以以极小的资源占用,提供高效的监听订阅服务。主要用于存放规则配置,各worker的ip地址,以及探测出的热key、手工添加的热key等。
2、client端jar包
就是在服务中添加的引用jar,引入后,就可以以便捷的方式去判断某key是否热key。同时,该jar完成了key上报、监听etcd里的rule变化、worker信息变化、热key变化,对热key进行本地caffeine缓存等。
3、worker端集群
worker端是一个独立部署的Java程序,启动后会连接etcd,并定期上报自己的ip信息,供client端获取地址并进行长连接。之后,主要就是对各个client发来的待测key进行累加计算,当达到etcd里设定的rule阈值后,将热key推送到各个client。
4、dashboard控制台
控制台是一个带可视化界面的Java程序,也是连接到etcd,之后在控制台设置各个APP的key规则,譬如2秒出现20次算热key。然后当worker探测出来热key后,会将key发往etcd,dashboard也会监听热key信息,进行入库保存记录。同时,dashboard也可以手工添加、删除热key,供各个client端监听。
![]()
综上,可以看到该框架没有依赖于任何定制化的组件,与redis更是毫无关系,核心就是靠netty连接,client端送出待测key,然后由各个worker完成分布式计算,算出热key后,就直接推送到client端,非常轻量级。
02 该框架工作流程
1、首先搭建etcd集群
etcd作为全局共用的配置中心,将让所有的client能读取到完全一致的worker信息和rule信息。
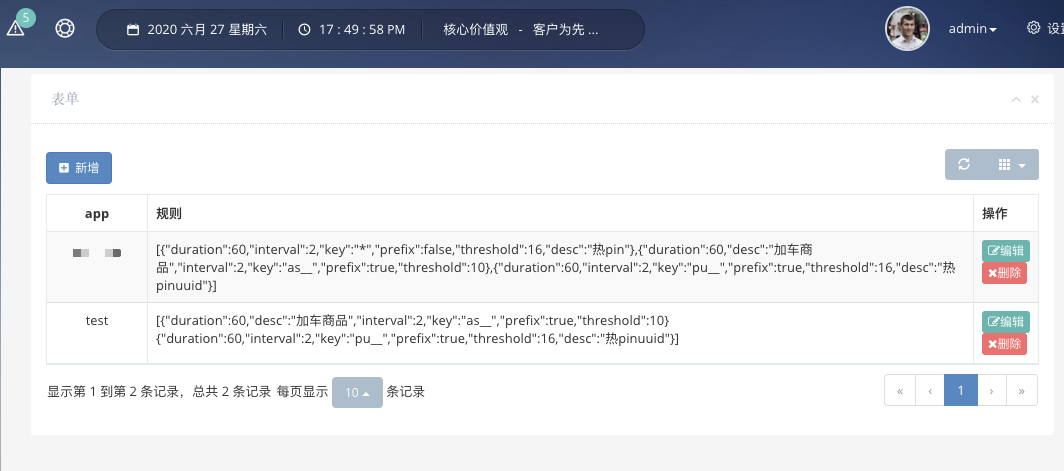
2、启动dashboard可视化界面
在界面上添加各个APP的待测规则,如app1它包含两个规则,一个是userId_开头的key,如userId_abc,每2秒出现20次则算热key,第二个是skuId_开头的每1秒出现超过100次则算热key。只有命中规则的key才会被发送到worker进行计算。
![]()
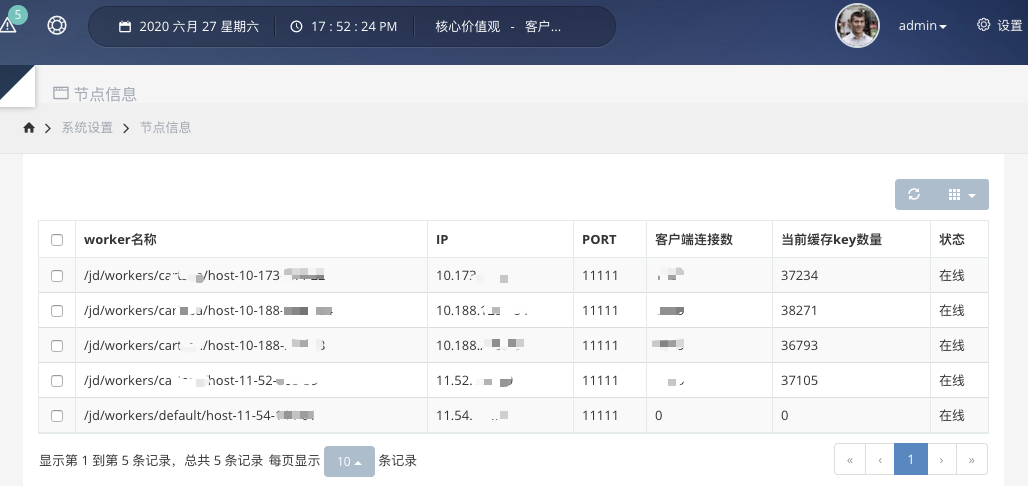
3、启动worker集群
worker集群可以配置APP级别的隔离,也可以不隔离,做了隔离后,这个app就只能使用这几个worker,以避免其他APP在性能资源上产生竞争。worker启动后,会从etcd读取之前配置好的规则,并持续监听规则的变化。
然后,worker会定时上报自己的ip信息到etcd,如果一段时间没有上报,etcd会将该worker信息删掉。worker上报的ip供client进行长连接,各client以etcd里该app能用的worker信息为准进行长连接,并且会根据worker的数量将待测的key进行hash后平均分配到各个worker。
之后,worker就开始接收并计算各个client发来的key,当某key达到规则里设定的阈值后,将其推送到该APP全部客户端jar,之后推送到etcd一份,供dashboard监听记录。
4、client端
client端启动后会连接etcd,获取规则、获取专属的worker ip信息,之后持续监听该信息。获取到ip信息后,会通过netty建立和worker的长连接。
client会启动一个定时任务,每500ms(可设置)就批量发送一次待测key到对应的worker机器,发送规则是key的hashcode 对worker数量取余,所以固定的key肯定会发送到同一个worker。这500ms内,就是本地搜集累加待测key及其数量,到期就批量发出去即可。注意,已经热了的key不会再次发送,除非本地该key缓存已过期。
当worker探测出来热key后,会推送过来,框架采用caffeine进行本地缓存,会根据当初设置的rule里的过期时间进行本地过期设置。当然,如果在控制台手工新增、删除了热key,client也会监听到,并对本地caffeine进行增删。这样,各个热key在整个client集群内是保持一致性的。
jar包对外提供了判断是否是热key的方法,如果是热key,那么你只需要关心自己的逻辑处理就好,是限流它、是降级它访问的部分接口、还是给它返回value,都依赖于自己的逻辑处理,非常的灵活。
注意,我们关注的只有key本身,也就是一个字符串而已,而不关心value,我们只探测key。那么此时必然有一个疑问,如果是redis的热key,框架告诉了我哪个是热key,并没有给我value啊。是的,框架提供了是否是热key的方法,如果是redis热key,就需要用户自己去redis获取value,然后调用框架的set方法,将value也set进去就好。如果不是热key,那么就走原来的逻辑即可。所以可以将框架当成一个具备热key的HashMap但需要自己去维护value的值。
综上,该框架以非常轻量级的做法,实现了毫秒级热key精准探测,和集群规模一致性,适用于大量场景,任何对某些字符串有热度匹配需求的场景都可以使用。
热key探测框架性能表现
该key已经历了多次大促压测、极端场景压测以及618大促线上使用,这期间修复了很多不常见、甚至有些匪夷所思的问题,之前也发表过相关问题总结文章。
这里我们仅对它的性能表现进行简单的阐述。
etcd端:
etcd性能优异,官方宣称秒级读写可达数万,实际我们使用中仅仅是热key的推送,以及其他少量信息的监听读写,负载非常轻。数千级别的客户端连接,平时秒级百来个的热key诞生,cpu占用率不超过5%,大部分时间在1%左右。
worker端:
worker端是该框架最核心的一环,也是承载分布式计算压力最大的部分,需要根据秒级各client发来的key总量来进行资源分配。譬如每秒有100万个key待测,那么我们需要知道单个worker的处理能力,然后决定分配多少个worker机器来均分这些计算任务。
这一块也是调优的核心地方,越高的qps,就是越低的成本。我简单列举一些之前的测试数据。
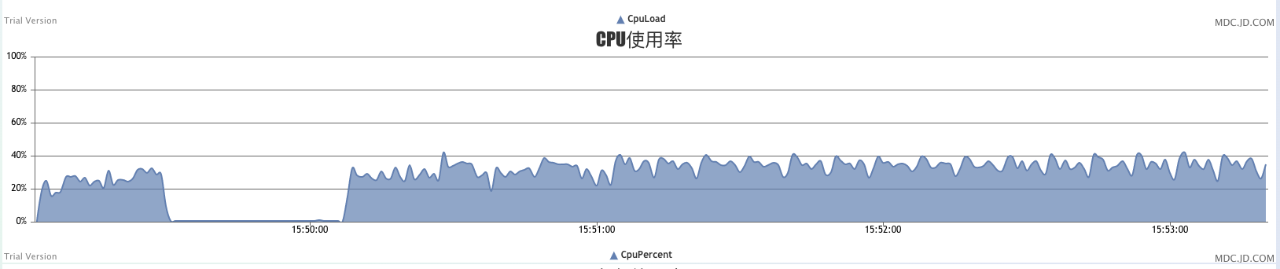
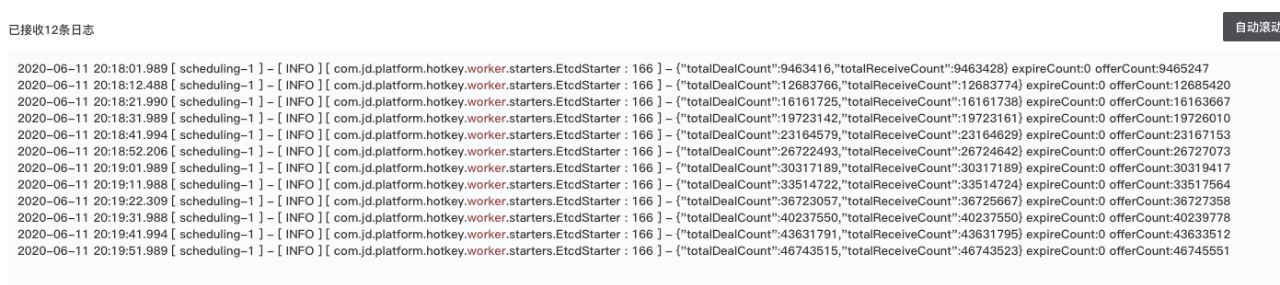
8核8G的worker单机场景负载,totalDealCount为累计计算过的key数量(进行完累加、推送热key到client等完毕后,数量+1),totalReceiveCount为累计收到的key数量(刚收到尚未参与计算).expireCount为收到时从客户端发出到worker收到已经超过5秒,不参与计算的key数量。
![]()
以上每10秒打印一次,可以看到处理量每10秒大概是160万次。
![]()
机器cpu占有率达到70%左右,高峰地方多是gc导致,整体到这个压力级别,我们认为它已经不能再大幅加压了。
换用16核16G机器后,同样的数据量即10秒160万不变,16核机器要轻松的多。
![]()
cpu占有率在30%多,整体负载比较轻,加大数据源后。
![]()
![]()
10秒达到200万时,cpu上升至40%多,说明还有继续增加压力的空间。后续经过极限压力写入,我们验证了单机在30万以上QPS情况下可稳定工作半小时以上,但CPU负载已很高,存在不确定性风险,这样的性能表现足以应对大部分“突发”场景。
![]()
![]()
综上,我们可以给出性能的简单结论,使用8核的worker机器,单机每秒可处理每秒10万级别的key探测计算和推送任务。使用16核的机器,可较为轻松应对20万每秒的处理任务。
用户可以根据该性能标准,来分配相应的worker数量。譬如你的应用每秒有100万个请求,你要探测的维度有userId、skuId两个,那么就需要自己去估算大概有多少个skuId和userId,假如100万个请求分别来自于100万个不同的用户、每个用户都访问了不同的sku,那么就是200万的待测key。所以你需要10台worker会比较稳妥。
该框架已在京东APP后台上线使用,并经历了多次大促压测演练以及618大促,表现相当稳定,社区版也已在码云发布(https://gitee.com/jd-platform-opensource/hotkey)。希望该框架能成为所有热key场景问题的通用解决方案,能为各个有相关问题困扰的个人、公司提供一份助力。
![]()
相关问题可咨询wuweifeng10@jd.com,liwangyang@jd.com。