简介
JVM的参数有很多很多,根据我的统计JDK8中JVM的参数总共有1853个,正式的参数也有680个。
这么多参数带给我们的是对JVM的细粒度的控制,但是并不是所有的参数都需要我们自己去调节的,我们需要关注的是一些最常用的,对性能影响比较大的GC参数即可。
为了更好的让大家理解JDK8中 GC的调优的秘籍,这里特意准备了八张图。在本文的最后,还附带了一个总结的PDF all in one文档,大家把PDF下载回去,遇到问题就看两眼,不美吗?
分代垃圾回收器的内存结构
为了更好的提升GC的效率,现代的JVM都是采用的分代垃圾回收的策略(ZGC不是)。
![]()
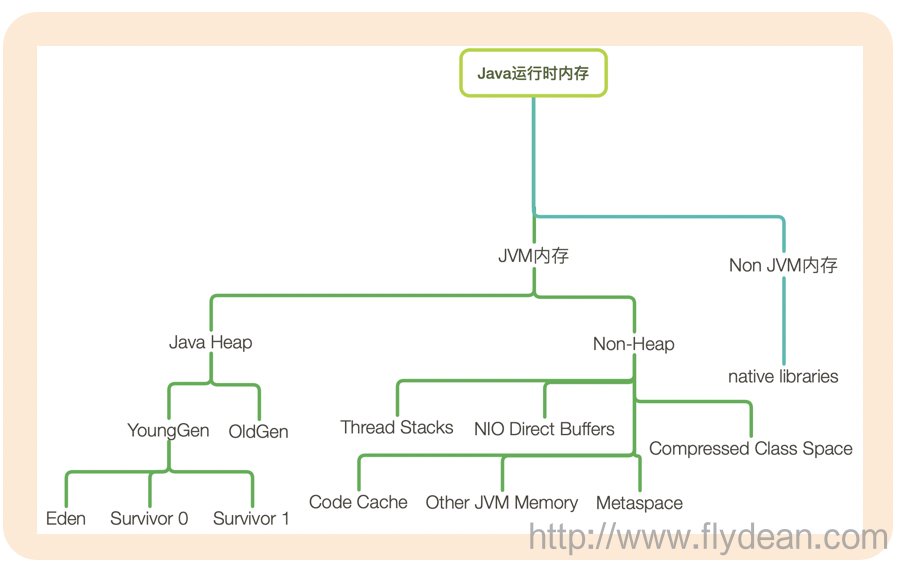
java运行时内存可以分为JVM内存和非JVM内存。
JVM内存又可以分为堆内存和非堆内存。
堆内存大家都很熟悉了,YoungGen中的Eden,Survivor和OldGen。
非堆内存中存储的有thread Stack,Code Cache, NIO Direct Buffers,Metaspace等。
注意这里的Metaspace元空间是方法区在JDK8的实现,它是在本地内存中分配的。
JDK8中可用的GC
JDK8中到底有哪些可以使用的GC呢?
这里我们以HotSpot JVM为例,总共可以使用4大GC方式:
![]()
其中对于ParallelGC和CMS GC又可以对年轻代和老年代分别设置GC方式。
大家看到上图可能有一个疑问,Parallel scavenge和Parallel有什么区别呢?
其实这两个GC的算法是类似的,Parallel Scavenge收集器也经常称为“吞吐量优先”收集器,Parallel Scavenge收集器提供了两个参数用于精确控制吞吐量; -XX:MaxGCPauseMillis:控制最大垃圾收集停顿时间; -XX:GCTimeRatio:设置吞吐量大小。
同时Parallel Scavenge收集器能够配合自适应调节策略,把内存管理的调优任务交给虚拟机去完成。
JDK8中默认开启的是ParallelGC。
打印GC信息
如果想研究和理解GC的内部信息,GC信息打印是少不了的:
![]()
上图提供了一些非常有用的GC日志的控制参数。
内存调整参数
JVM分为Heap区和非Heap区,各个区又有更细的划分,下面就是调整各个区域大小的参数:
![]()
Thread配置
TLAB大家还记得吗?
如果一个对象的分配是在方法内部,并且没有多线程访问的情况下,那么这个对象其实可以看做是一个本地对象,这样的对象不管创建在哪里都只对本线程中的本方法可见,因此可以直接分配在栈空间中。
栈上分配的对象因为不用考虑同步,所以执行速度肯定会更加快速,这也是为什么JVM会引入栈上分配的原因。
![]()
上图就是TLAB的参数。
通用GC参数
虽然JDK8的GC这么多,但是他们有一些通用的GC参数:
![]()
这里讲解一下Young space tenuring,怎么翻译我不是很清楚,这个主要就是指Young space中的对象经过多少次GC之后会被提升到Old space中。
CMS GC
CMS全称是Concurrent mark sweep。是一个非常非常复杂的GC。
复杂到什么程度呢?光光是CMS调优的参数都有一百多个!
下图是常用的CMS的参数。
![]()
CMS这里就不多讲了,因为在JDK9之后,CMS就已经被废弃了。
主要原因是CMS太过复杂,如果要向下兼容需要巨大的工作量,然后就直接被废弃了。
在JDK9之后,默认的GC是G1。
G1参数
G1收集器是分代的和region化的,也就是整个堆内存被分为一系列大小相等的region。在启动时,JVM设置region的大小,根据堆大小的不同,region的大小可以在1MB到32MB之间变动,region的数量最多不超过2048个。Eden区、Survivor区、老年代是这些region的逻辑集合,它们并不是连续的。
G1中的垃圾收集过程:年轻代收集和混合收集交替进行,背后有全局的并发标记周期在进行。当老年代分区占用的空间达到或超过初始阈值,就会触发并发标记周期。
下图是G1的调优参数:
![]()
总结
上面总共8副图,我把他们做成了一个PDF,预览界面大概是这样子的: ![]()
大家可以通过下面的链接直接下载PDF版本:
JDK8GC-cheatsheet.pdf
如果遇到问题可以直接拿过来参考。这种东西英文名字应该叫JDK8 GC cheatsheet,翻译成中文应该就是JDK8 GC调优秘籍!
本文作者:flydean程序那些事
本文链接:http://www.flydean.com/jdk8-gc-cheatsheet/
本文来源:flydean的博客
欢迎关注我的公众号:程序那些事,更多精彩等着您!