简介
比特币的底层就是区块链技术,区块链也是因为比特币而广为人知的。和其他的区块链技术相比,比特币的区块链有什么特征呢?作为去区块链的鼻祖,又有什么与众不同的特性呢?快来跟我们一起看看吧。
比特币的网络
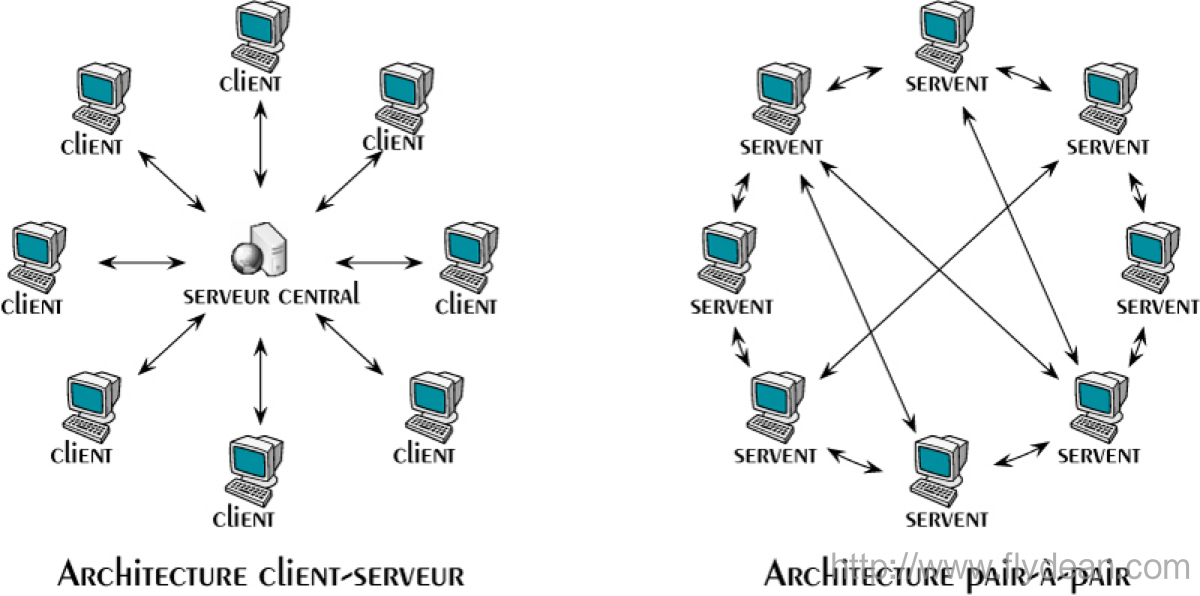
比特币使用的是P2P(peer-to-peer)网络,此P2P非彼P2P,这里是点对点的网络架构,而不是人对人的借钱模式。
P2P是指位于同一网络中的每台计算机都彼此对等,各个节点共同提供网络服务,不存在任何“特殊”节点。每个网络节点以“扁平(flat)”的拓扑结构相互连通。在P2P网络中不存在任何服务端(server)、中央化的服务、以及层级结构。
![]()
传统的网络结构是client-server的模式,所有的client都是和server交互获取信息, 只要server挂掉了,client也就没有用了。
而在P2P网络中,没有server的概念,每个节点可以作为一个server。对比起来P2P网络在稳定性方面要比C-S架构的系统要稳定得多。
网络发现与同步
既然是P2P网络,那么问题来了,这个P2P网络是怎么建立起来的呢?节点之间是怎么发现的呢?
有做过P2P下载的同学应该都听说过种子的概念,这个种子里面保存了其他活跃的节点的地址。通过下载种子就可以连接对应的节点。
而每个节点又保存了最近连接或者活跃的节点,这样就形成了庞大的P2P网络。
同样的,比特币的P2P网络也是这样的。
新节点是如何发现网络中的对等节点的呢?虽然比特币网络中没有特殊节点,但是客户端会维持一个列表,那里列出了那些长期稳定运行的节点。这样的节点被称为“种子节点(seed nodes)”
节点必须持续进行两项工作:在失去已有连接时发现新节点,并在其他节点启动时为其提供帮助。
SPV节点
我们之前介绍了,在比特币的世界里既没有账户,也没有余额,只有分散到区块链里的UTXO(Unspent Transaction Outputs)。
那么如果想要验证交易的话,需要从历史的交易中查找所有的和该交易有关的交易,从而进行完整,全面的验证。
这样做的问题就是,如果下载所有的历史记录,那么需要上百G的硬盘空间,这对于手机或者其他轻量级的客户端是无法想象的。
于是SPV出现了。SPV的全称是Simplified payment verification,叫做简单认证支付。
SPV保存的不是整个区块链,而是区块链的头部,因为每个区块链头只有80字节,所以即使把所有的区块头都下载保存起来也不会很大。
区块链头
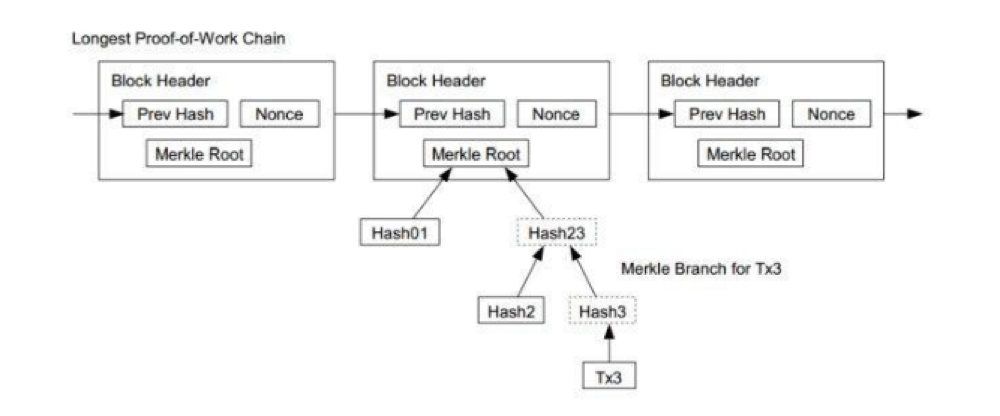
区块头由三组区块元数据组成。首先是一组引用父区块哈希值的数据,这组元数据用于将该区块与区块链中前一区块相连接。
第二组元数据,即难度、时间戳和nonce,与挖矿竞争相关。
第三组元数据是merkle树根(一种用来有效地总结区块中所有交易的数据结构)。
Nonce、难度目标和时间戳会用于挖矿过程,Merkle根用来索引和组织该区块所有的交易信息。
![]()
![]()
上图是一个区块链头组成的链。
Merkle Tree
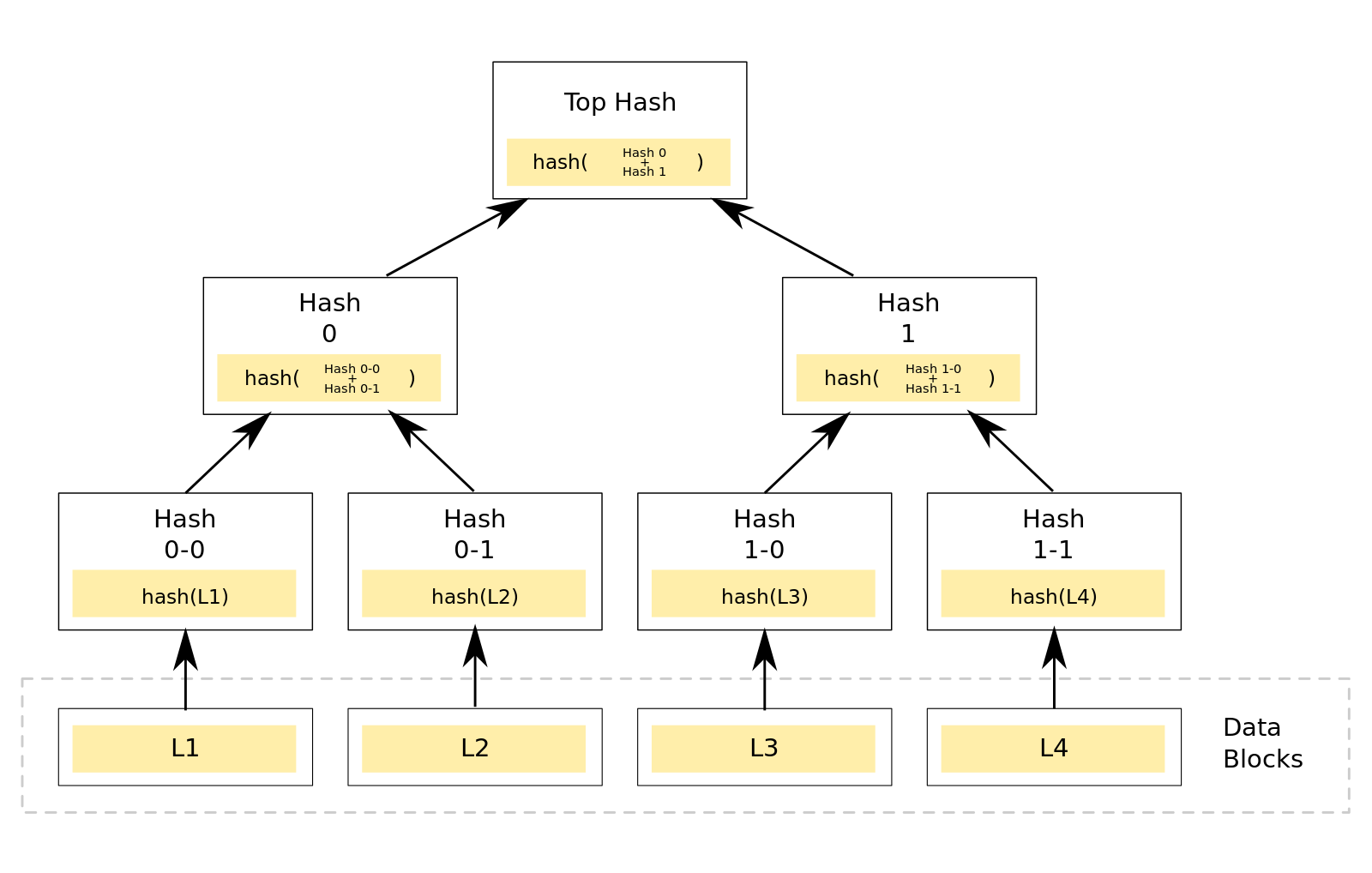
Merkle Tree,是一种树(数据结构中所说的树),网上大都称为Merkle Hash Tree,这是因为 它所构造的Merkle Tree的所有节点都是Hash值。Merkle Tree具有以下特点:
-
它是一种树,可以是二叉树,也可以多叉树,无论是几叉树,它都具有树结构的所有特点;
-
Merkle树的叶子节点上的value,是由你指定的,这主要看你的设计了,如Merkle Hash Tree会将数据的Hash值作为叶子节点的值;
-
非叶子节点的value是根据它下面所有的叶子节点值,然后按照一定的算法计算而得出的。如Merkle Hash Tree的非叶子节点value的计算方法是将该节点的所有子节点进行组合,然后对组合结果进行hash计算所得出的hash value。
![]()
有了Merkle Tree,我们只需要知道和要验证的交易相关的其他Merkle Tree中的信息,就可以计算出整个Merkle Tree的值,这样就可以直接使用头部信息进行验证了。这就是SPV的原理。
比特币中的区块链
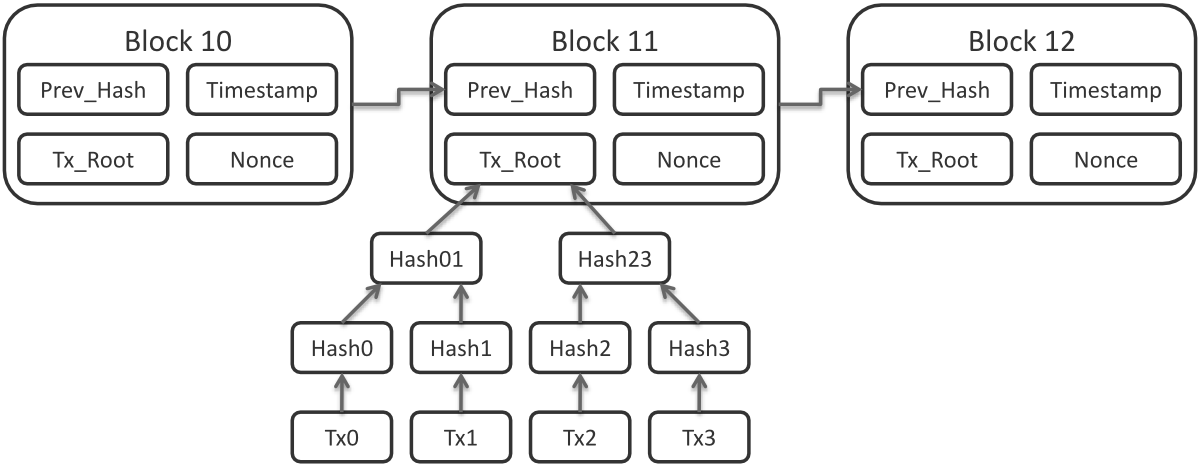
区块链是由包含交易信息的区块从后向前有序链接起来的数据结构。它可以被存储为flat file(一种包含没有相对关系记录的文件),或是存储在一个简单数据库中。
比特币核心客户端使用Google的LevelDB数据库存储区块链元数据。
它由一个包含元数据的区块头和紧跟其后的构成区块主体的一长串交易组成。区块头是80字节,而平均每个交易至少是250字节,而且平均每个区块至少包含超过500个交易。
![]()
区块标识符
那怎么表示一个区块呢?我们使用区块标志符。
区块主标识符是它的加密哈希值,一个通过SHA256算法对区块头进行二次哈希计算而得到的数字指纹。产生的32字节哈希值被称为区块哈希值,但是更准确的名称是:区块头哈希值,因为只有区块头被用于计算。
第二种识别区块的方式是通过该区块在区块链中的位置,即“区块高度(block height)”。第一个区块,其区块高度为0 和区块哈希值不同的是,区块高度并不是唯一的标识符。虽然一个单一的区块总是会有一个明确的、固定的区块高度,但反过来却并不成立,一个区块高度并不总是识别一个单一的区块。两个或两个以上的区块可能有相同的区块高度,在区块链里争夺同一位置。
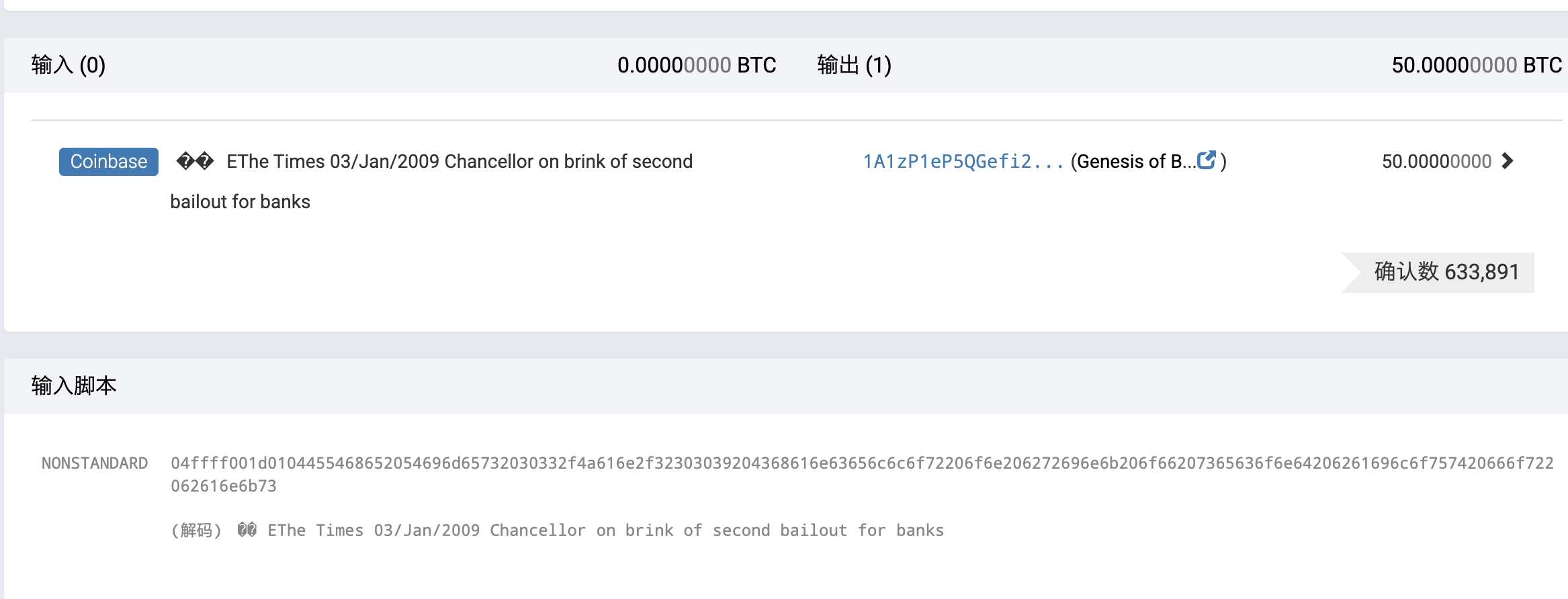
创世区块
区块链里的第一个区块创建于2009年,被称为创世区块。它是区块链里面所有区块的共同祖先,这意味着你从任一区块,循链向后回溯,最终都将到达创世区块。
因为创世区块被编入到比特币客户端软件里,所以每一个节点都始于至少包含一个区块的区块链,这能确保创世区块不会被改变。每一个节点都“知道”创世区块的哈希值、结构、被创建的时间和里面的一个交易。因此,每个节点都把该区块作为区块链的首区块,从而构建了一个安全的、可信的区块链的根。
创世区块的哈希值为: 0000000000 19d6689c085ae165831e934ff763ae46a2a6c172b3f1b60a8ce26f
创世区块包含一个隐藏的信息。在其Coinbase交易的输入中包含这样一句话“The Times 03/Jan/2009 Chancellor on brink of second bailout forbanks.”这句话是泰晤士报当天的头版文章标题,引用这句话,既是对该区块产生时间的说明,也可视为半开玩笑地提醒人们一个独立的货币制度的重要性,同时告诉人们随着比特币的发展,一场前所未有的世界性货币革命将要发生。该消息是由比特币的创立者中本聪嵌入创世区块中。
![]()
coinbase的值是:04ffff001d0104455468652054696d65732030332f4a616e2f32303039204368616e63656c6c6f72206f6e206272696e6b206f66207365636f6e64206261696c6f757420666f722062616e6b73
解码方法如下:
在python shell下:
"04ffff001d0104455468652054696d65732030332f4a616e2f32303039204368616e63656c6c6f72206f6e206272696e6b206f66207365636f6e64206261696c6f757420666f722062616e6b73".decode('hex')
输出:
'\x04\xff\xff\x00\x1d\x01\x04EThe Times 03/Jan/2009 Chancellor on brink of second bailout for banks'
总结
本文介绍了比特币的网络和比特币中的区块链的相关概念,希望大家能够喜欢。
本文作者:flydean程序那些事
本文链接:http://www.flydean.com/bitcoin-blockchain-network/
本文来源:flydean的博客
欢迎关注我的公众号:程序那些事,更多精彩等着您!