关于多租户管理(Spring Cloud 技术栈)的架构设计
目前公司的框架是有多租户的(SpringClodu技术栈),有一个子站是专门用来配置多租户的,数据隔离采用的是 共享同一个Database、同一个Schema 和 不同的租户也可以配置不同的数据源。 现在的问题是租户只能查看自己租户的数据。 但是领导给的需求是要有一个顶级管理员,可以查看所有租户的数据。 租户也可以分类。 领导说要在现有框架的基础上做出修改,出个概要设计, 可是想破脑袋也不知道怎么搞 ,求各位大神支个招。
高可用真是一丝细节都不得马虎。平时跑的好好的系统,在相应硬件出现故障时就会引发出潜在的Bug。偏偏这些故障在应用层的表现稀奇古怪,很难让人联想到是硬件出了问题,特别是偶发性出现的问题更难排查。今天,笔者就给大家带来一个存储偶发性故障的排查过程。
我们的积分应用由于量非常大,所以需要进行分库分表,所以接入了我们的中间件。一直稳定运行,但应用最近确经常偶发连接建立不上的报错。报错如下:
GetConnectionTimeOutException
而笔者中间件这边收到的确是:
NIOReactor - register err java.nio.channels.CloasedChannelException
这样的告警。整个Bug现场如下图所示: 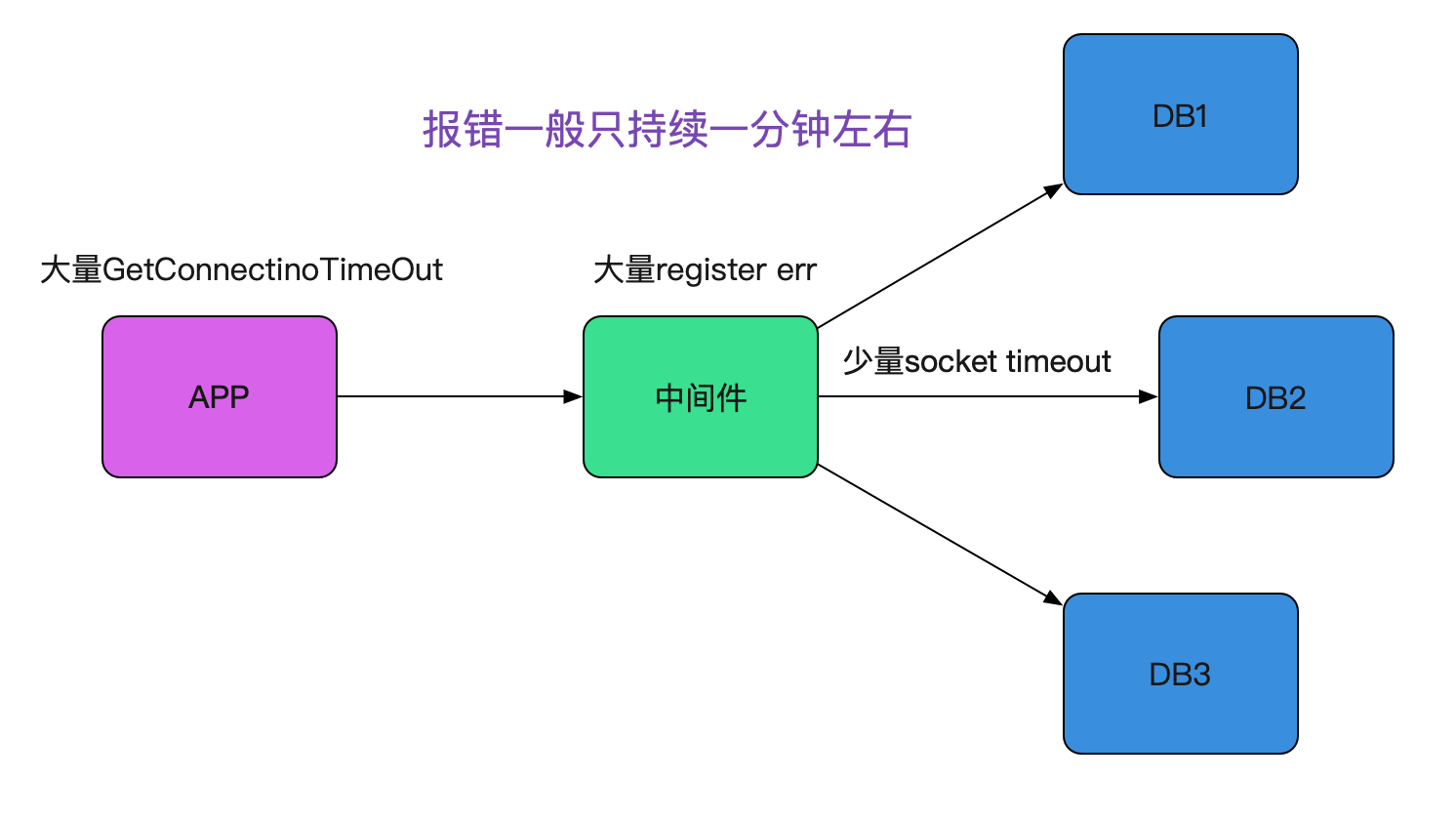
之前出过类似register err这样的零星报警,最后原因是安全扫描,并没有对业务造成任何影响。而这一次,类似的报错造成了业务的大量连接超时。由于封网,线上中间件和应用已经稳定在线上跑了一个多月,代码层面没有任何改动!突然出现的这个错误感觉是环境出现了某些问题。而且由于线上的应用和中间件都是集群,出问题时候都不是孤立的机器报错,没道理所有机器都正好有问题。如下图所示: 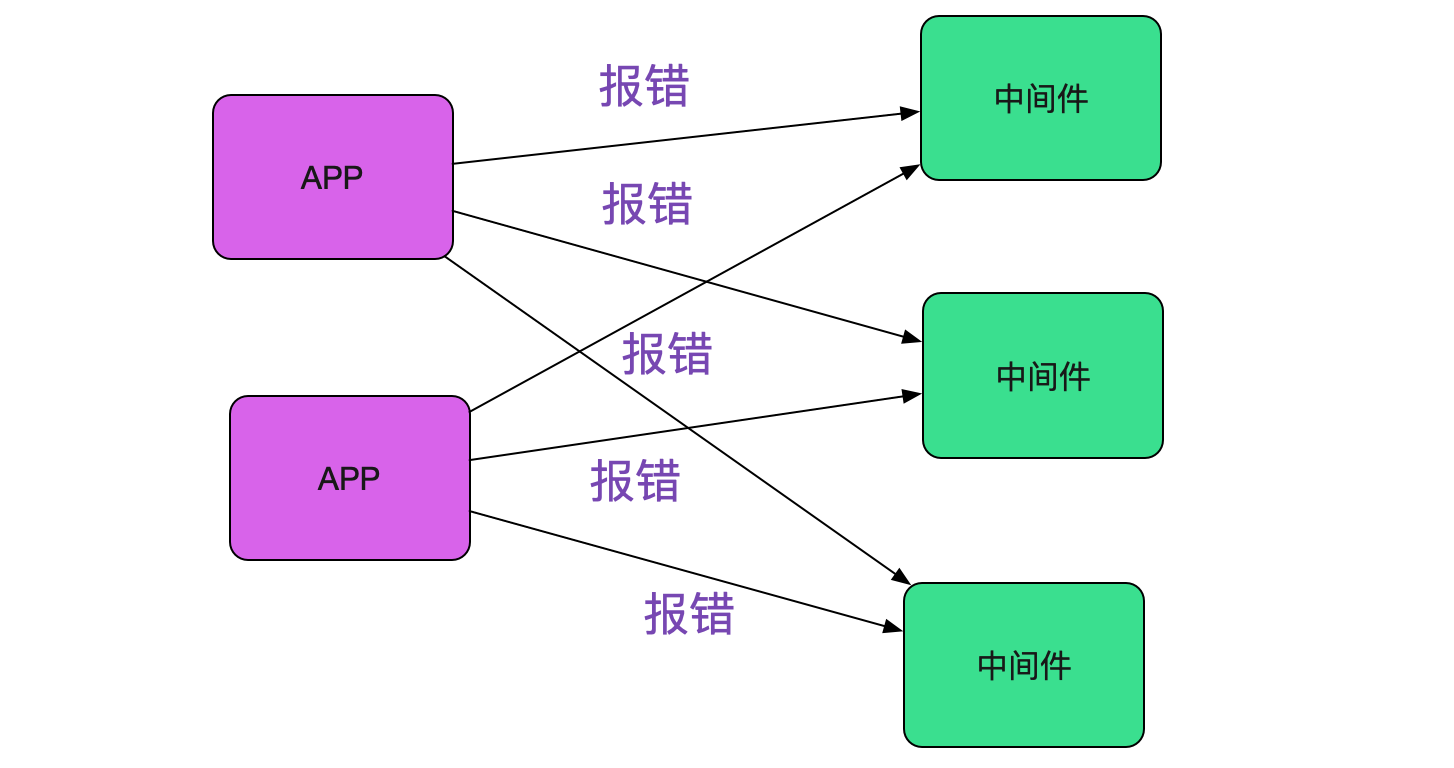
遇到这种连接超时,笔者最自然的想法当然是网络出了问题。于是找网工进行排查, 在监控里面发现网络一直很稳定。而且如果是网络出现问题,同一网段的应用应该也都会报错 才对。事实上只有对应的应用和中间件才报错,其它的应用依旧稳稳当当。
就在笔者觉得这个偶发性问题可能不会再出现的时候,又开始抖了。而且是一个下午连抖了两次。脸被打的啪啪的,算了算了,先重启吧。重启中间件后,以为能消停一会,没想到半个小时之内又报了。看来今天不干掉这个Bug是下不了班了! 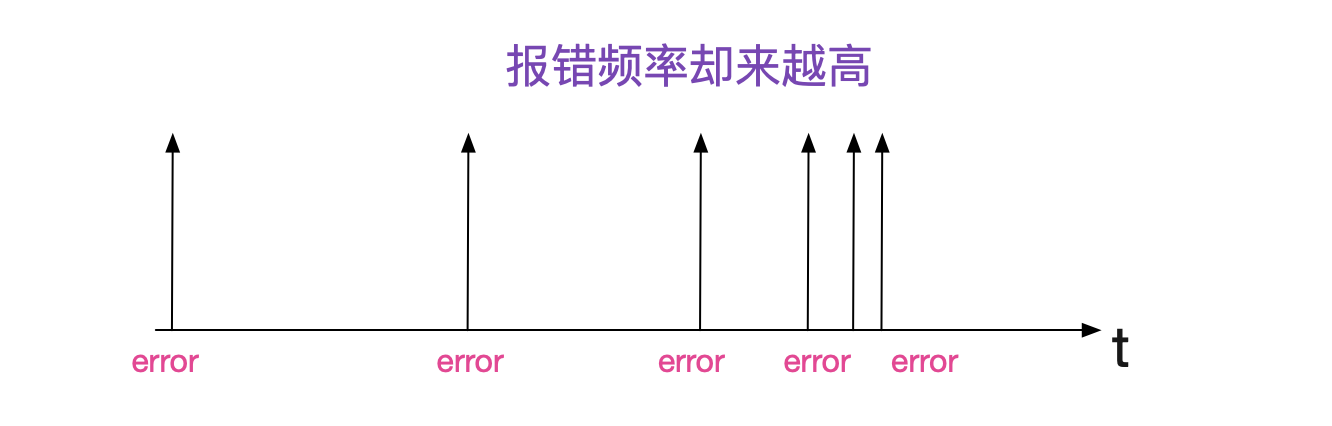
事实上,笔者一开始就发现中间件有调用后端数据库慢SQL的现象,由于比较偶发,所以将这个现象发给DBA之后就没有继续跟进,DBA也反馈SQL执行没有任何异常。笔者开始认真分析日志之后,发现一旦有 中间件的register err 必定会出现中间件调用后端数据库的sql read timeout的报错。
但这两个报错完全不是在一个线程里面的,一个是处理前端的Reactor线程,一个是处理后端SQL的Worker线程,如下图所示: 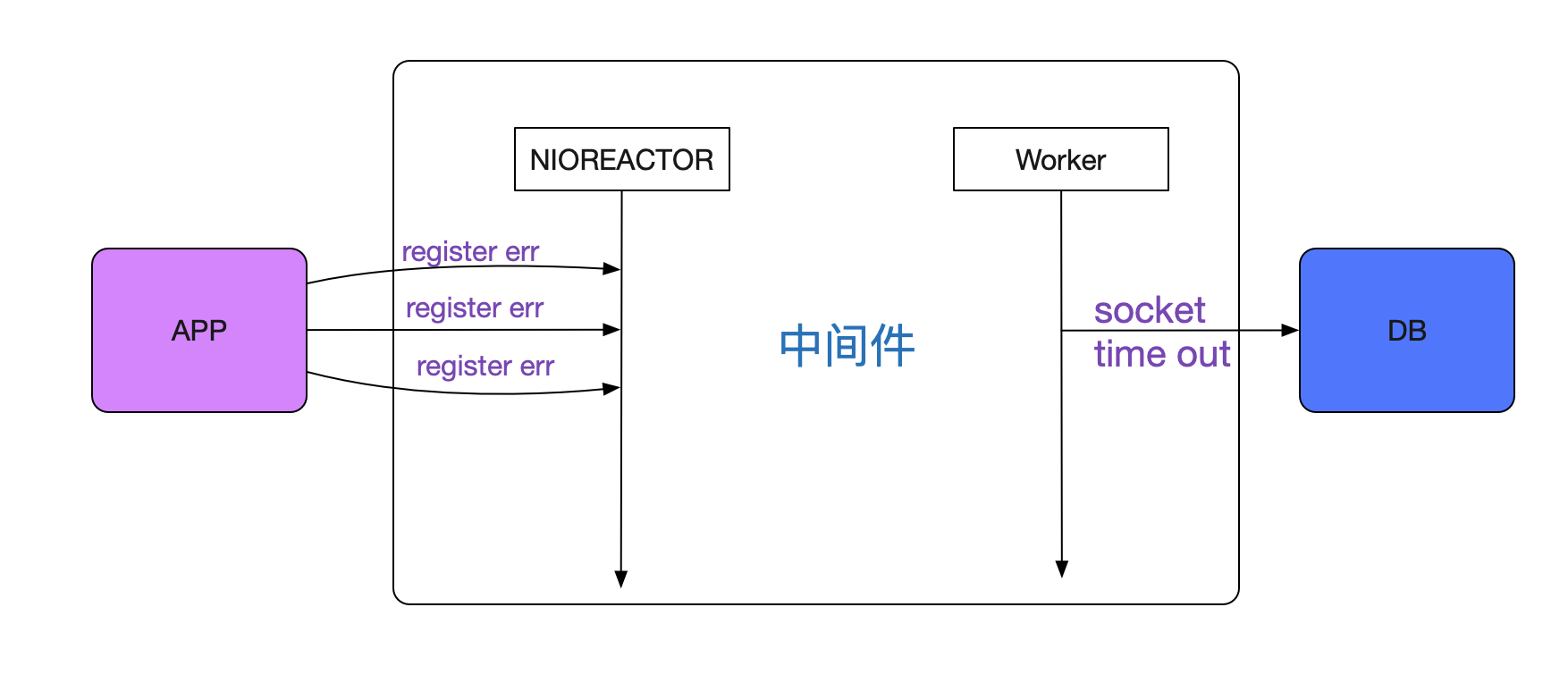
这两个线程是互相独立的,代码中并没有发现任何机制能让这两个线程互相影响。难道真是这些机器本身网络出了问题?前端APP失败,后端调用DB超时,怎么看都像网络的问题!
既然有DB(数据库)超时,笔者就先看看调用哪个DB超时吧,毕竟后面有一堆DB。笔者突然发现,和之前的慢SQL一样,都是调用第二个数据库超时,而DBA那边却说SQL执行没有任何异常, 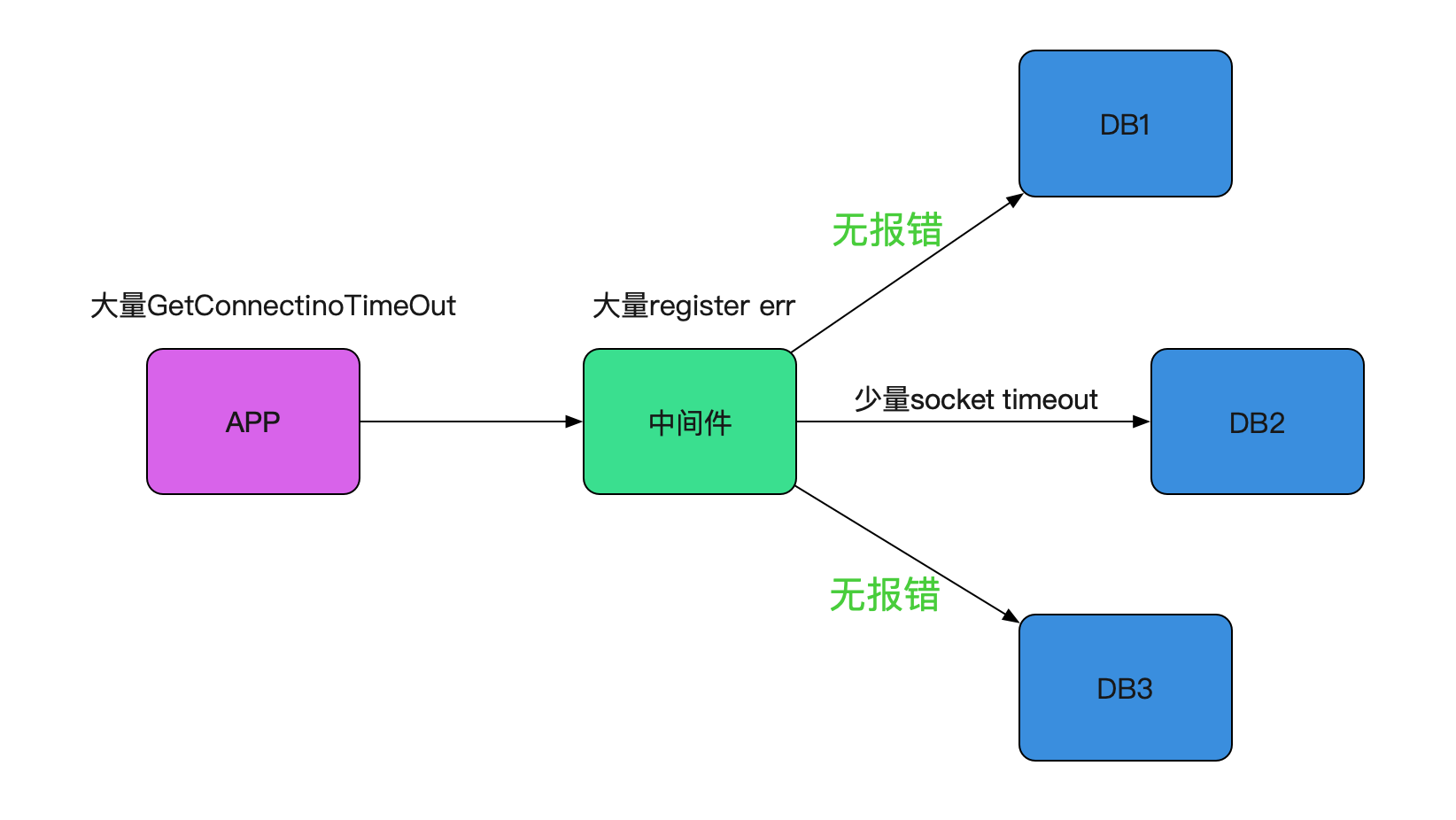
笔者感觉明显SQL执行有问题,只不过DBA是采样而且将采样耗时平均的,偶尔的几笔耗时并不会在整体SQL的耗时里面有所体现。 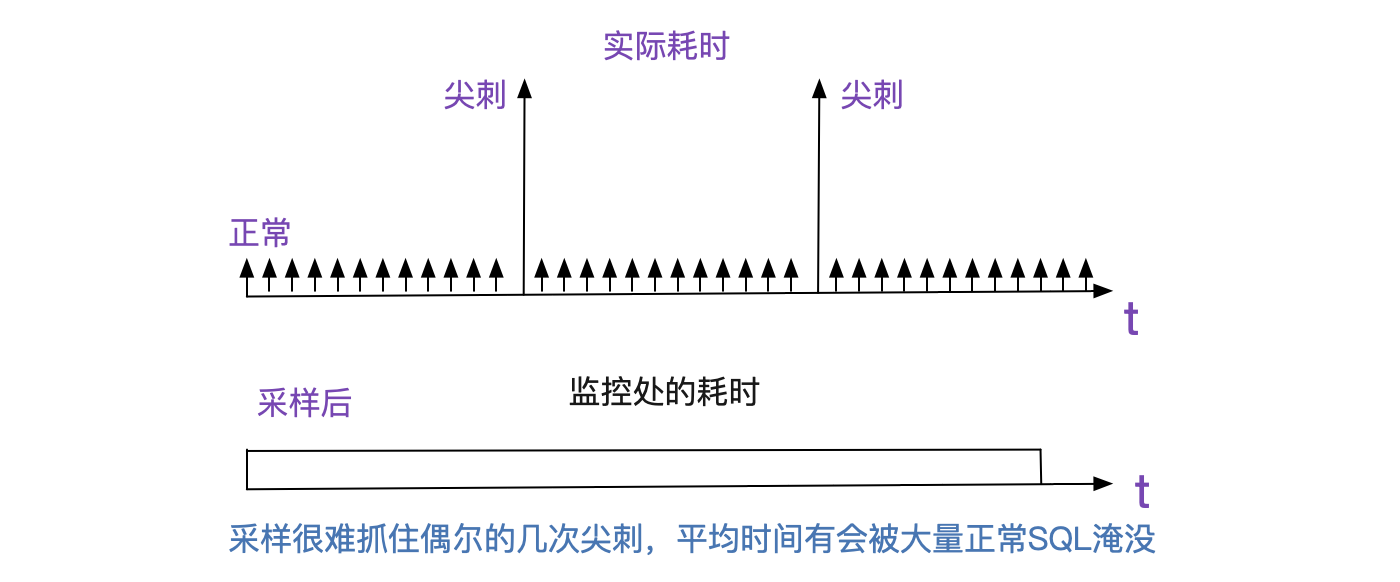
既然找不到什么头绪,那么只能从日志入手,好好分析推理了。REACTOR线程和Worker线程同时报错,但两者并无特殊的关联,说明可能是同一个原因引起的两种不同现象。笔者在线上报错日志里面进行细细搜索,发现在大量的
NIOReactor-1-RW register err java.nio.channels.CloasedChannelException
日志中会掺杂着这个报错:
NIOReactor-1-RW Socket Read timed out
at XXXXXX . doCommit
at XXXXXX Socket read timedout
这一看就发现了端倪,Reactor作为一个IO线程,怎么会有数据库调用呢?于是翻了翻源码,原来,我们的中间件在处理commit/rollback这样的操作时候还是在Reactor线程进行的!很明显Reactor线程卡主是由于commit慢了!笔者立马反应过来,而这个commit慢也正是导致了regsiter err以及客户端无法创建连接的元凶。如下面所示: 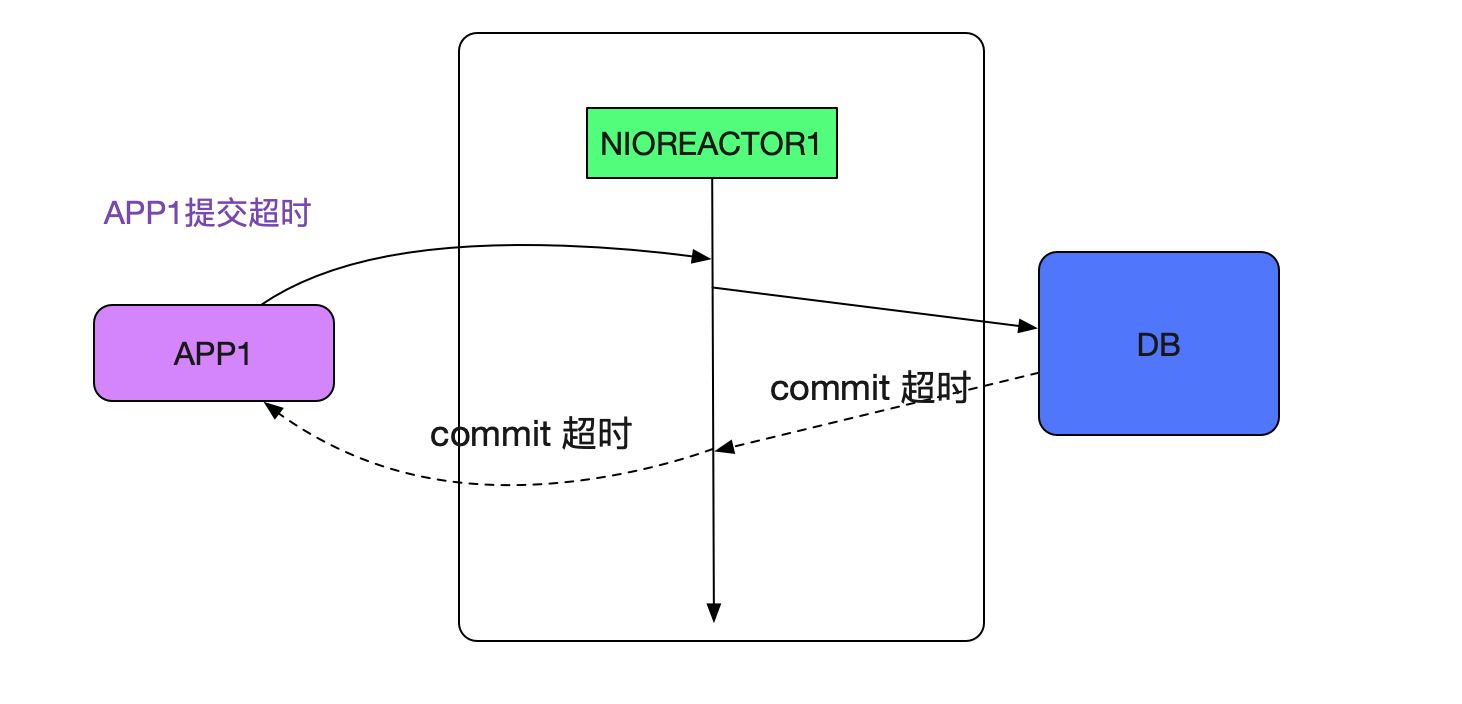
由于app1的commit特别慢而卡住了reactor1线程,从而落在reactor1线程上的握手操作都会超时!如下图所示: 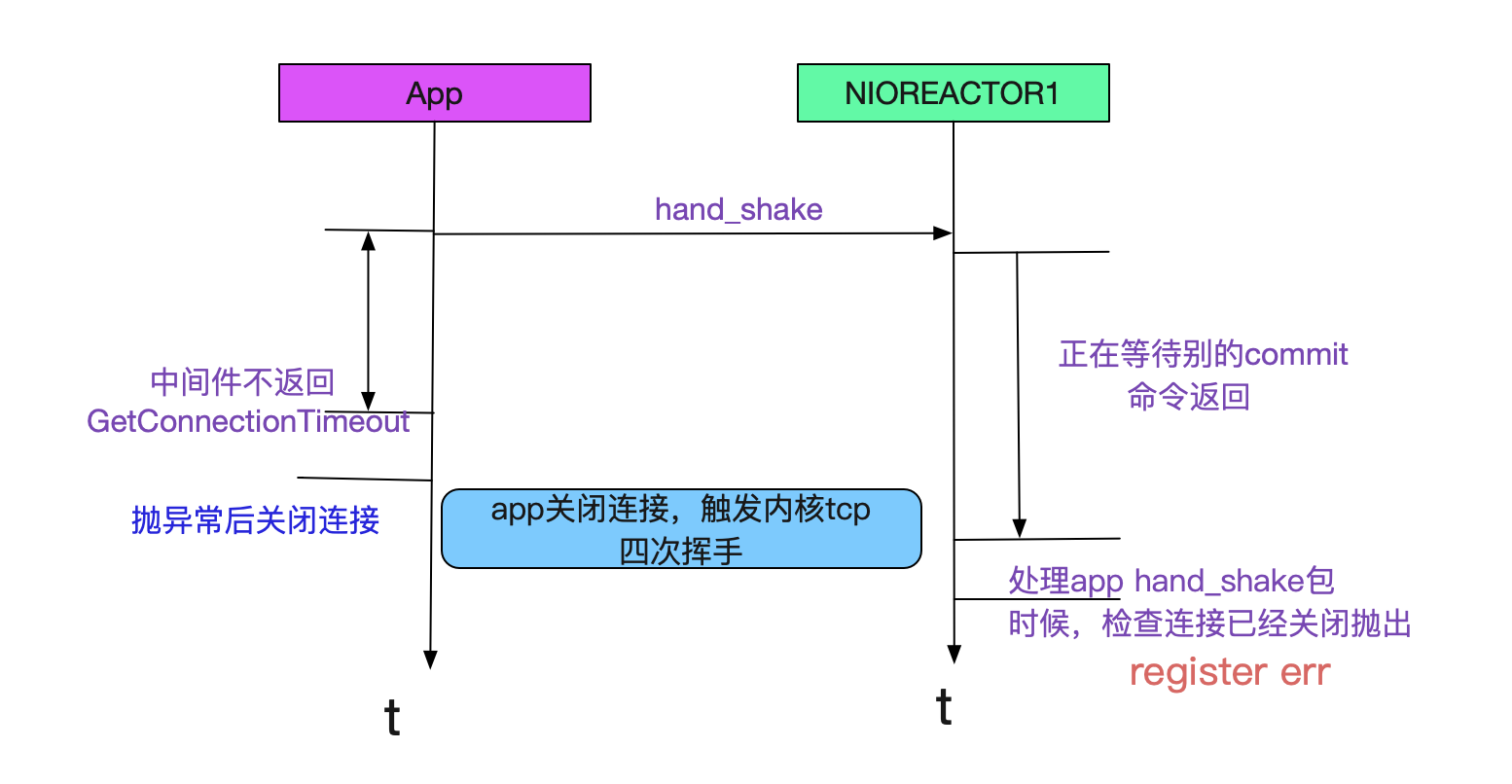
因为模拟宕机的时候,在事务开始的第一条SQL就会报错,而执行SQL都是在Worker线程里面, 所以并不会触发reactor线程中commit超时这种现象,所以测试的时候就遗漏了这一点。
系统一直跑的好好的,为什么突然commit就变慢了呢,而且笔者发现,这个commit变慢所关联的DB正好也是出现慢SQL的那个DB。于是笔者立马就去找了DBA,由于我们应用层和数据库层都没有commit时间的监控(因为一般都很快,很少出现慢的现象)。DBA在数据库打的日志里面进行了统计,发现确实变慢了,而且变慢的时间和我们应用报错的时间相符合! 顺藤摸瓜,我们又联系了SA,发现其中和存储相关的HBA卡有报错!如下图所示: 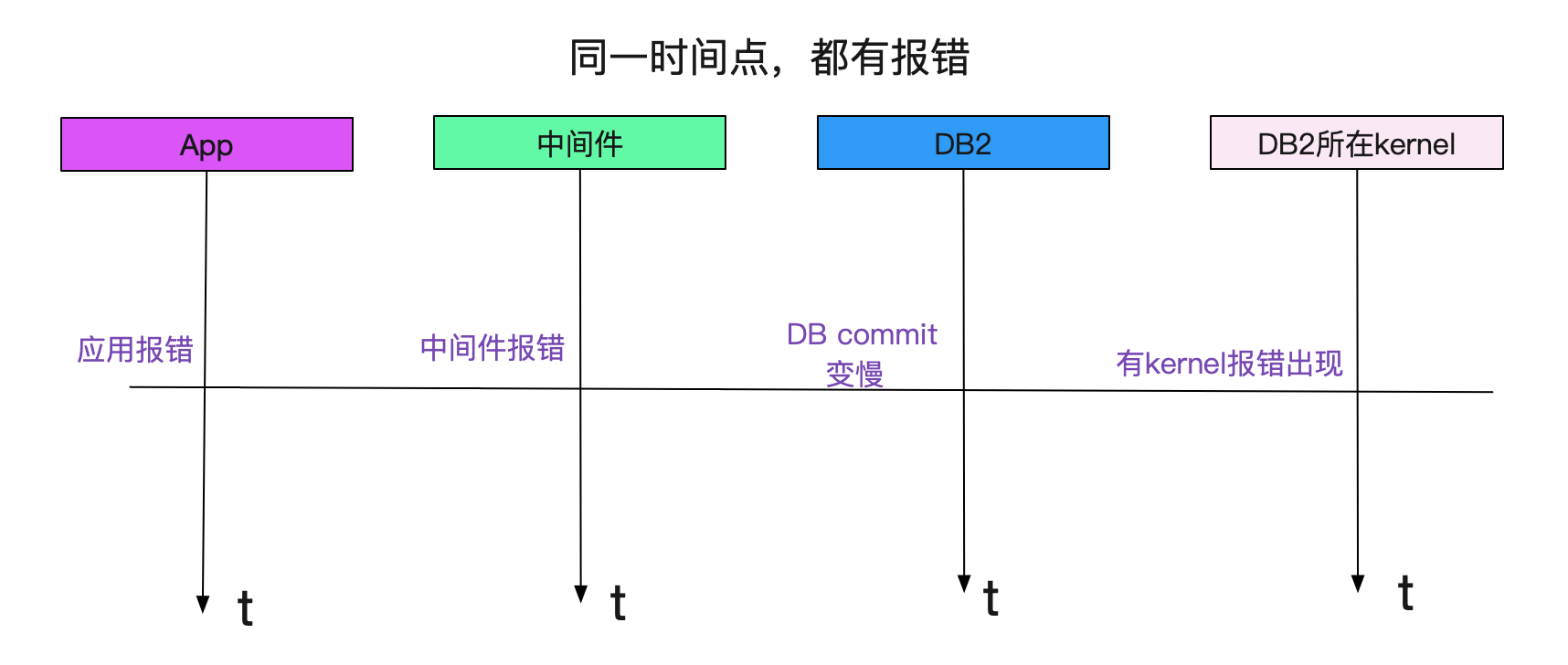
报错时间都是一致的!
由于是HBA卡报错了,属于硬件故障,而硬件故障并不是很快就能进行修复的。所以DBA做了一次紧急的主从切换,进而避免这一问题。 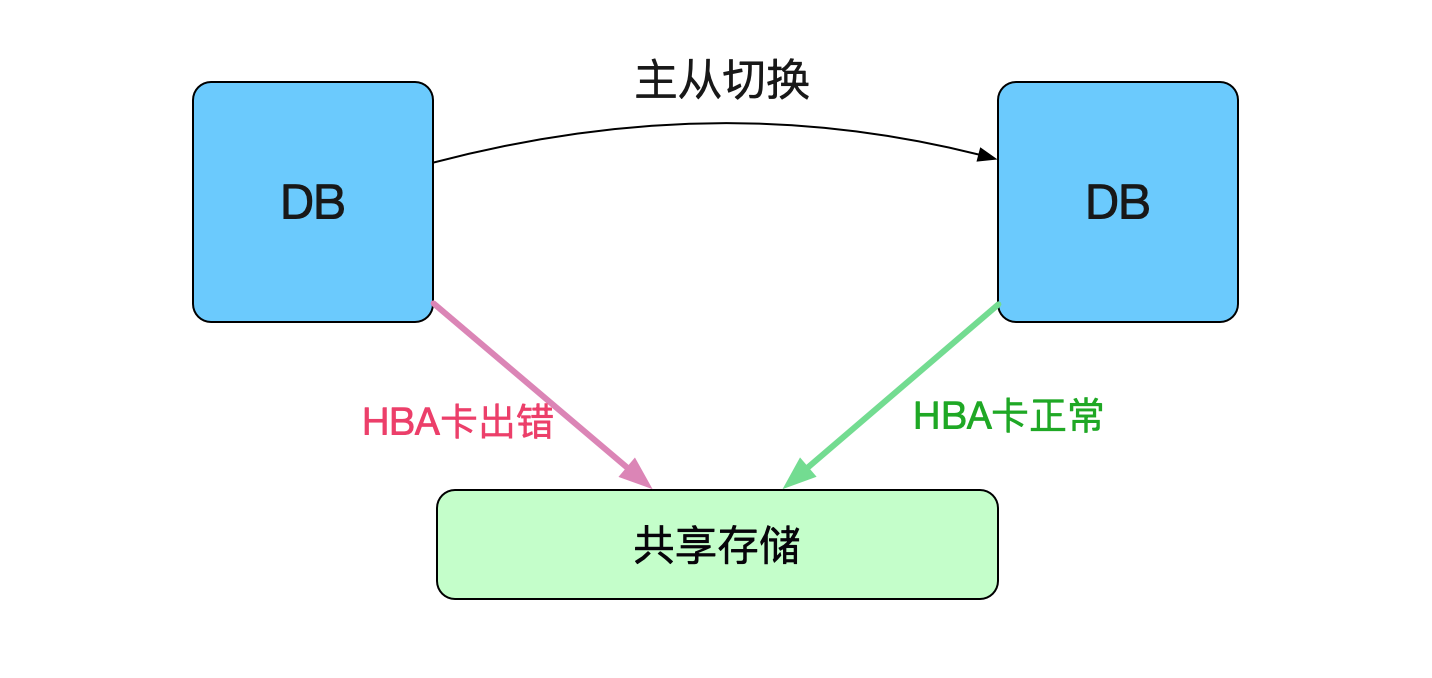
之前就有慢sql慢慢变多,而后突然数据库存储hba卡宕机导致业务不可用的情况。 而这一次到最后主从切换前为止,报错越来越频繁,感觉再过一段时间,HBA卡过段时间就完全不可用,重蹈之前的覆辙了!
我们在中间件层面将commit和rollback操作挪到Worker里面。这样,commit如果卡住就不再会引起创建连接失败这种应用报错了。
由于软件层面其实是比较信任硬件的,所以在硬件出问题时,就会产生很多诡异的现象,而且和硬件最终的原因在表面上完全产生不了关联。只有通过抽丝剥茧,慢慢的去探寻现象的本质才会解决最终的问题。要做到高可用真的是要小心评估各种细节,才能让系统更加健壮!
关注笔者公众号,获取更多干货文章:



微信关注我们
转载内容版权归作者及来源网站所有!
低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service 的首字母简称,一个易于构建 AI Agent 应用的动态服务发现、配置管理和AI智能体管理平台。Nacos 致力于帮助您发现、配置和管理微服务及AI智能体应用。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据、流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。
Spring框架(Spring Framework)是由Rod Johnson于2002年提出的开源Java企业级应用框架,旨在通过使用JavaBean替代传统EJB实现方式降低企业级编程开发的复杂性。该框架基于简单性、可测试性和松耦合性设计理念,提供核心容器、应用上下文、数据访问集成等模块,支持整合Hibernate、Struts等第三方框架,其适用范围不仅限于服务器端开发,绝大多数Java应用均可从中受益。
Rocky Linux(中文名:洛基)是由Gregory Kurtzer于2020年12月发起的企业级Linux发行版,作为CentOS稳定版停止维护后与RHEL(Red Hat Enterprise Linux)完全兼容的开源替代方案,由社区拥有并管理,支持x86_64、aarch64等架构。其通过重新编译RHEL源代码提供长期稳定性,采用模块化包装和SELinux安全架构,默认包含GNOME桌面环境及XFS文件系统,支持十年生命周期更新。
WebStorm 是jetbrains公司旗下一款JavaScript 开发工具。目前已经被广大中国JS开发者誉为“Web前端开发神器”、“最强大的HTML5编辑器”、“最智能的JavaScript IDE”等。与IntelliJ IDEA同源,继承了IntelliJ IDEA强大的JS部分的功能。
扫码在手机上查看文章
扫描二维码,手机阅读更方便
有任何问题或合作意向欢迎联系我们
Email: 99873273@qq.com
QQ: 99873273