上一次我们谈到了各种类型的数据库,今天我们来谈谈在大数据,尤其是Hadoop栈下的数据和文件的存储。
我们知道为了解决大数据的存储和处理问题,google最先设计了推出了Map/Reduce的算法,而hadoop就是Google的map/reduce的开源实现。Hadoop主要由分布式的文件系统HDFS(参考Google的GFS)和Map/Reduce计算这两块。但随着Spark等更强大的计算引擎的出现,很少再有人使用Hadoop的Map/Reduce来做计算了,但是对于海量数据/文件的存储,除了HDFS,还真没有更多更好的选择。所以我们就来看看在Hadoop下,文件存储的各种选项。
原始文本文件
首先,我们什么都不需要做,HDFS提供分布式的文件存储,那么我们就直接把原始的文本文件存储在HDFS上就好了。通常我们会使用诸如txt,csv,json,xml等文本格式的文件存储在HDFS上,然后由各种计算引擎加载,计算。
HDFS是按照块来存储文件的,缺省的设置一个块的大小是64M,那么假定我的文本文件是1G,它会被分成16个分区,由计算引擎(Spark,Map/Reduce)来并行的处理,计算。
使用文本格式的主要问题是:
- 占用空间大
- 处理时有额外的序列化反序列化的开销,例如把日志中的文本‘12’转化为数字的12
所以这里就引入了两个解决方案:
- 压缩。
压缩是使用计算资源来换取存储/IO的资源。因为压缩后的体积小,存储和传输的效率就变高了,当然,压缩和解压缩都会消耗系统的计算资源。常见的压缩算法有:snappy,gzip,bzip,LZO,zlib等
| 压缩方式 |
压缩效率 |
压缩速度 |
是否可分割 |
| Gzip |
中高 |
中 |
否 |
| bzip2 |
高 |
慢 |
是 |
| Snappy |
低 |
快 |
否 |
| LZO |
低 |
快 |
是(但是要求建立索引) |
| Zlib |
低 |
快 |
是 |
- 使用二进制的序列化格式
使用二进制的序列化格式,本身就占存储空间比文本小,而且也有比较好的序列化和反序列化的支持。
支持压缩的SequenceFile
为了解决文本文件存储和传输效率不高的问题,Hadoop提供了SequenceFile格式, SequenceFile是Hadoop API 提供的一种二进制文件, 它将数据(Key/Value形式)序列化到文件中。这种二进制文件内部使用Hadoop 的标准的Writable 接口实现序列化和反序列化。 支持三种记录存储方式,无压缩,记录压缩和块压缩。SequenceFile只支持Java, SequenceFile一般用来作为小文件的容器使用, 防止小文件占用过多的NameNode内存空间来存储其在DataNode位置的元数据。
![Blog::: JvmNotFoundException: Hadoop : How to read and write ...]()
语言无关的序列化文件
SequenceFile虽然解决了本文文件的空间占用问题,但是它支持Java,而我们程序员都觉得PHP才是最好的语言,于是我们需要与语言无关的序列化文件格式。Facebook推出了thrift,用于实现跨语言提供服务和接口, 满足跨平台通信. 但是Thrift不支持分片, 且缺少MapReduce的原生支持。
Avro是一个语言无关的支持数据密集型的二进制文件格式和数据序列化的系统, 它的出现主要是为了解决Writables API缺少跨语言移植的缺陷。Avro将模式存储在文件头中, 所以每个文件都是自描述的, 而且Avro还支持模式演进(schema evolution), 也就是说, 读取文件的模式不需要与写入文件的模式严格匹配, 当有新需求时, 可以在模式中加入新的字段。Avro的文件格式更为紧凑,若要读取大量数据时, Avro能够提供更好的序列化和反序列化性能。Avro支持分片, 即使是进行Gzip压缩之后。
Avro是Hadoop的基于行的存储格式,已广泛用作序列化平台。Avro将模式Schema存储为JSON格式,使任何程序均可轻松读取和解释。数据本身以二进制格式存储,从而使其紧凑高效。Avro是与语言无关的数据序列化系统。 它可以由多种语言(当前为C,C ++,C#,Java,Python和Ruby)处理。Avro的一项关键功能是对数据架构的强大支持,该架构会随时间变化,即架构演变。 Avro处理架构更改,例如缺少字段,添加的字段和更改的字段。Avro提供了丰富的数据结构。 例如,您可以创建一个包含数组,枚举类型和子记录的记录。
![大数据文件格式]()
这种格式是在数据湖着陆区中存储数据的理想选择,因为:1。 通常将从登陆区读取的数据整体读取,以供下游系统进行进一步处理(在这种情况下,基于行的格式更有效)2。 下游系统可以轻松地从文件中检索表模式(无需将Schema分别存储在外部元存储中)3。 任何源模式更改都易于处理(模式Schema演变)。
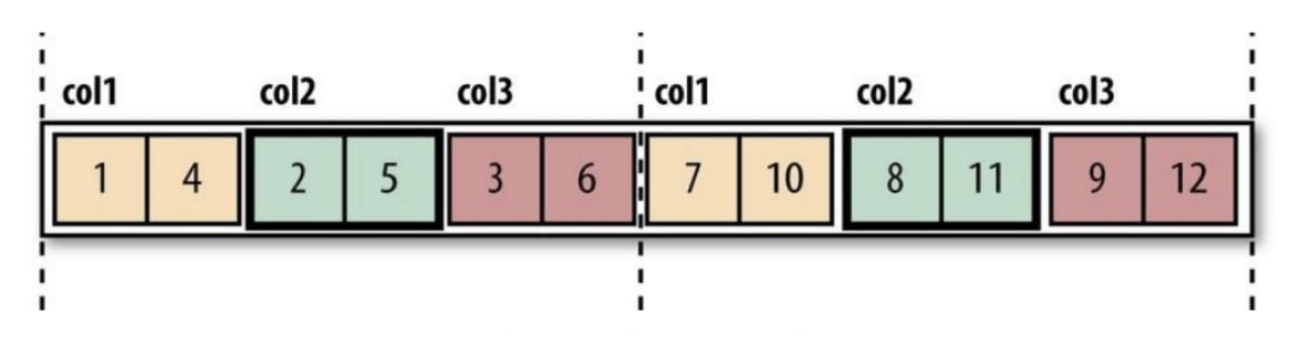
面向行/列的存储格式
之前的文件格式都是面向行的,同一行的数据存储在一起,即连续存储。采用这种方式,如果只需要访问行的一小部分数据,亦需要将整行读入内存,推迟序列化一定程度上可以缓解这个问题,但是从磁盘读取整行数据的开销却无法避免。面向行的存储适合于整行数据需要同时处理的情况。在大数据分析的场景下,我们常常对针对不同的列来做分析,大部分的分析计算,只会使用到少数的列,这个时候,行存储的效率就不高了,因为会读入并不需要的整行的数据。
![]()
![]()
为了解决行存储对分析应用效率不高的问题,程序猿们发明了面向列的存储格式。
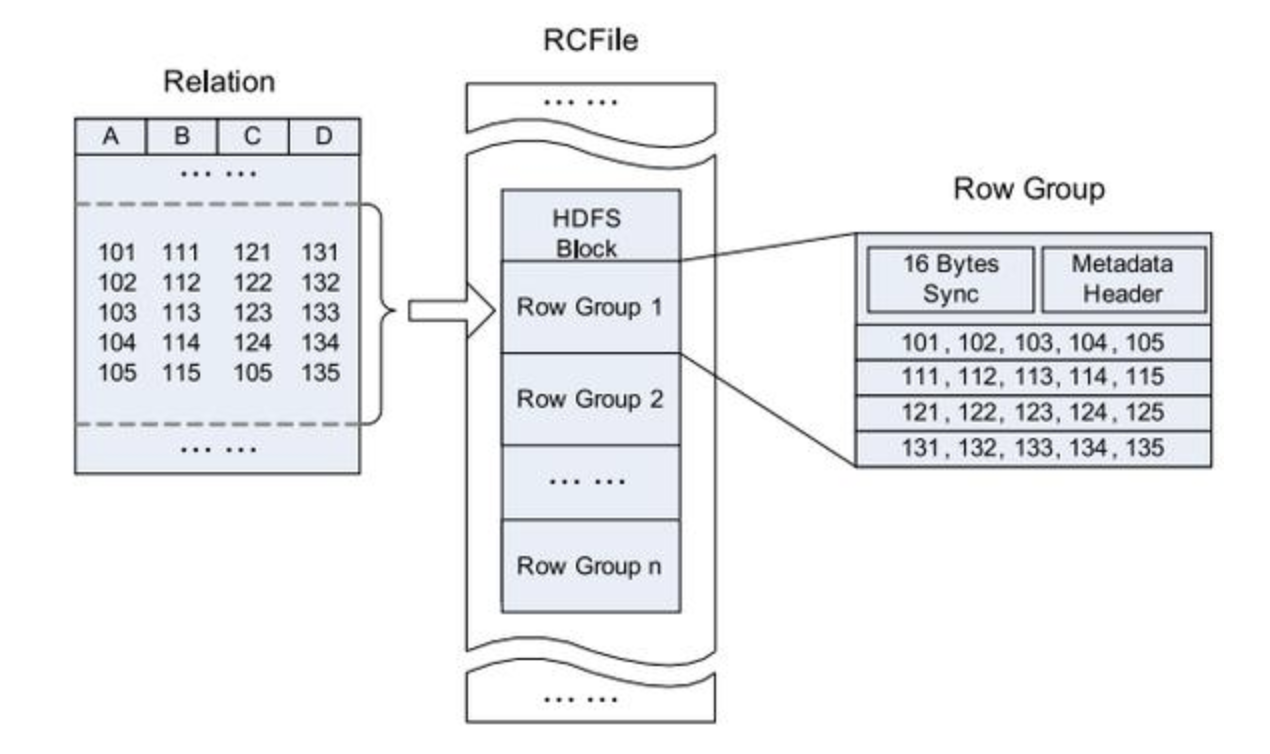
RC文件
Hive的Record Columnar File(记录列文件),这种类型的文件首先将数据按行划分为行组,然后在行组内部将数据存储在列中。 它遵循“先按列划分,再垂直划分”的设计理念。当查询过程中,针对它并不关心的列时,它会在IO上跳过这些列。需要说明的是,RCFile在map阶段从 远端拷贝仍然是拷贝整个数据块,并且拷贝到本地目录后RCFile并不是真正直接跳过不需要的列,并跳到需要读取的列, 而是通过扫描每一个row group的头部定义来实现的,但是在整个HDFS Block 级别的头部并没有定义每个列从哪个row group起始到哪个row group结束。所以在读取所有列的情况下,RCFile的性能反而没有SequenceFile高。它的结构如下:
![]()
ORC文件
ORC是一种专为Hadoop工作负载设计的自我描述类型感知列式文件格式。它针对大型流读取进行了优化,但具有集成支持,可快速查找所需的行。以列格式存储数据使阅读器仅可以读取,解压缩和处理当前查询所需的值。由于ORC文件可识别类型,因此编写器为该类型选择最合适的编码,并在写入文件时建立内部索引。
ORC文件格式提供了一种高效的数据存储方式。 提供了比RCFile更有效的文件格式。它旨在克服其他文件格式的限制。 它理想地存储紧凑的数据,并且无需大型,复杂或手动维护的索引就可以跳过不相关的部分。 ORC文件格式解决了所有这些问题。
![大数据文件格式]()
ORC文件格式具有许多优点,例如:
- 一个文件作为每个任务的输出,从而减轻了NameNode的负担
- 支持Hive类型,包括DateTime,十进制和复杂类型(结构,列表,映射和联合)
- 使用单独的RecordReader并发读取同一文件
- 无需扫描标记即可分割文件的能力
- 根据文件页脚中的信息,估计读取器/写入器在堆内存分配上的上限。
- 使用协议缓冲区存储的元数据,允许添加和删除字段
Parquet文件
Apache Parquet是Hadoop生态系统中任何项目均可使用的列式存储格式,而与数据处理框架,数据模型或编程语言的选择无关。
Parquet的独特功能之一是它也可以以列形式存储具有嵌套结构的数据。 这意味着在Parquet文件格式中,即使嵌套字段也可以单独读取,而无需读取嵌套结构中的所有字段。 Parquet格式使用记录粉碎和组装算法以列形式存储嵌套结构。
![大数据新人应该了解的Hadoop中的各种文件格式]()
要了解Hadoop中的Parquet文件格式,您应该注意以下术语:
- 行组:将数据逻辑地水平划分为行。 行组由数据集中每个列的列块组成。
- 列块:特定列的数据块。 这些列块位于特定的行组中,并保证在文件中是连续的。
- 页面:列块分为重新写回的页面。 这些页面共享一个公共标题,读应用可以跳过他们不感兴趣的页面。
![大数据文件格式]()
Apache Arrow
Apache Arrow是用于内存数据的跨语言开发平台。它为平面和分层数据指定了一种与语言无关的标准化列式存储格式,该格式组织用于在现代硬件上进行有效的分析操作。它还提供计算库和零复制流式消息传递和进程间通信。当前支持的语言包括C,C ++,C#,Go,Java,JavaScript,MATLAB,Python,R,Ruby和Rust。
简而言之,它促进了许多组件之间的通信,例如,使用Python Pandas 读取Parquet文件并转换为Spark数据框,Falcon Data Visualization或Cassandra,而无需担心转换。
Apache Arrow利用列缓冲区来减少IO并加快分析处理性能。
如上图所示,我们可以理解它是面向列的存储,但是实在内存内实现的。它可以用于优化在计算系统之间的数据交换。
CarbonData
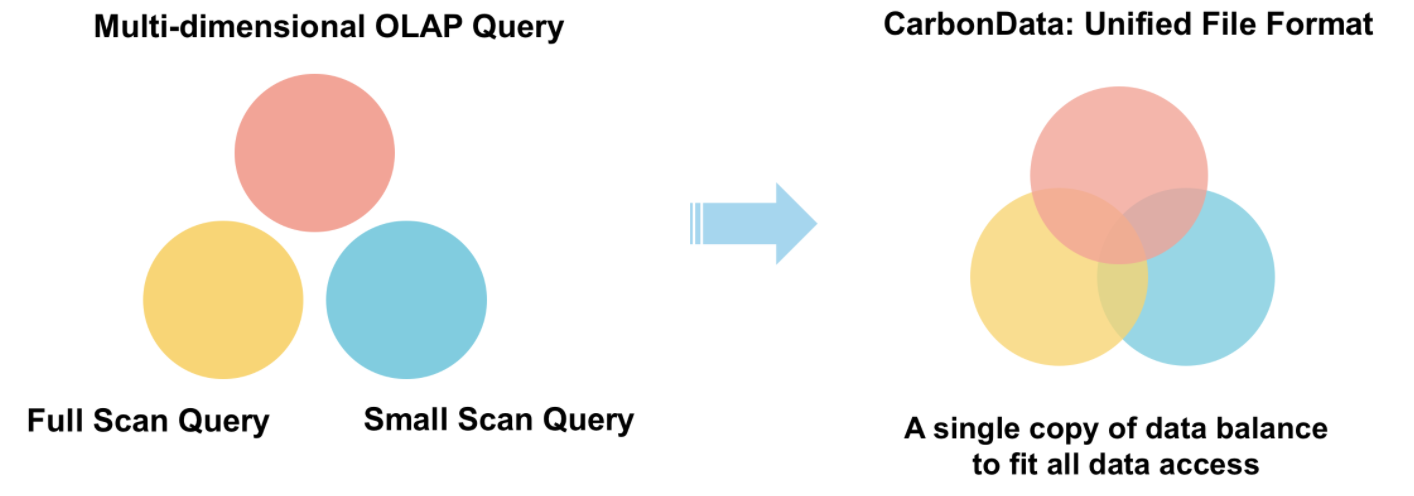
Apache CarbonData是带有多维索引的列式数据格式,用于在大数据平台上进行快速分析。
CarbonData是华为开源,将使您能够使用单个副本访问整个数据。 查询处理中的挑战是我们有不同类型的查询:
- OLAP查询和详细查询。
- 大扫描查询和小扫描查询:您可能有需要比较大扫描的查询,也可能有在较小区域内扫描的查询。
- 点查询:消耗大表的很少部分。
因此,统一的文件格式使您可以拥有不同类型的查询(导致不同类型的数据访问)。
![]()
CarbonData文件格式是基于列式存储的,并存储在HDFS之上;其包含了现有列式存储文件格式的许多优点,比如:可分割、可压缩、支持复杂数据类型等。CarbonData为了解决前面提到的几点要求,加入了许多独特的特性,主要概括为以下四点:
(1)数据及索引:在有过滤的查询中,它可以显著地加速查询性能,减少I/O和CPU资源;CarbonData的索引由多级索引组成,计算引擎可以利用这些索引信息来减少调度和一些处理的开销;扫描数据的时候可以仅仅扫描更细粒度的单元(称为blocklet),而不再是扫描整个文件;
(2)可操作的编码数据:通过支持高效的压缩和全局编码模式,它可以直接在压缩或者编码的数据上查询,仅仅在需要返回结果的时候才进行转换,更好的查询下推;
(3)列组:支持列组,并且使用行格式进行存储,减少查询时行重建的开销;
(4)多种使用场景:顺序存取、随机访问、类OLAP交互式查询等。
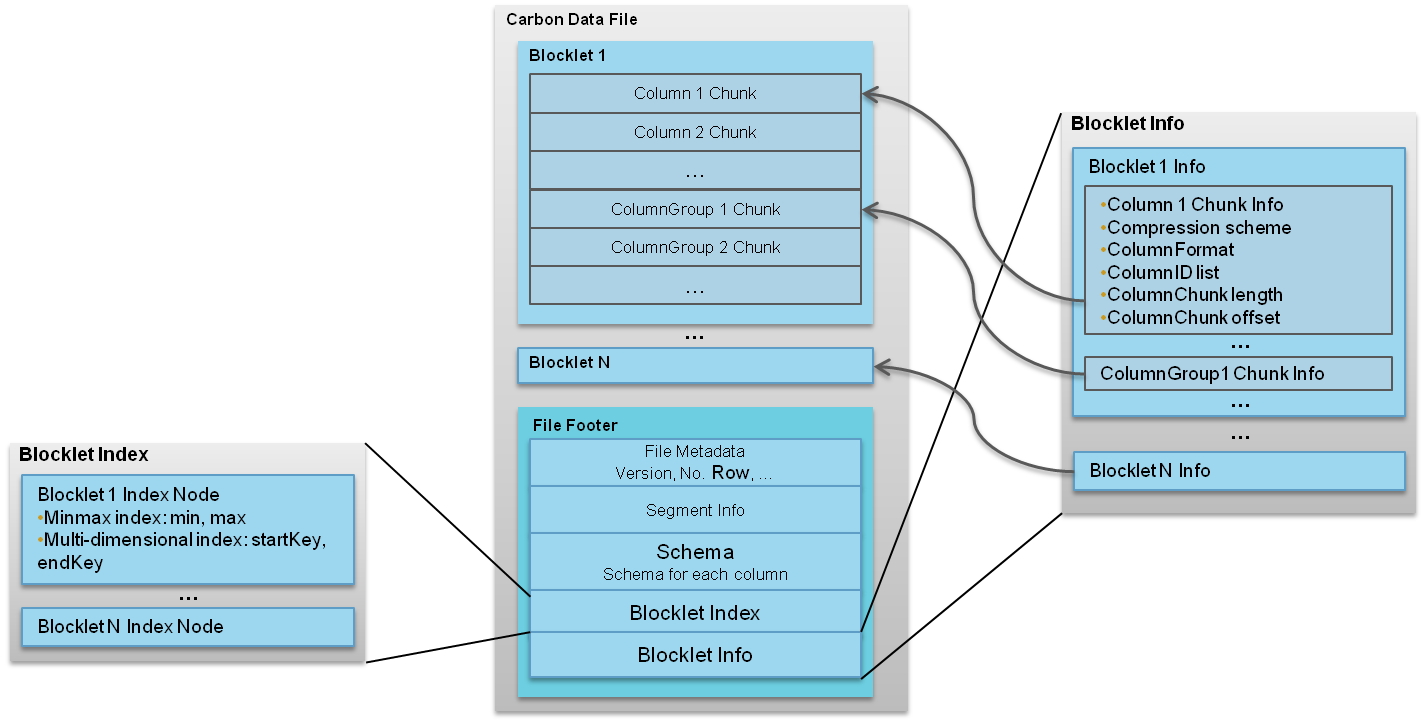
一个CarbonData文件是由一系列被称为blocklet组成的,除了blocklet,还有许多其他的元信息,比如模式、偏移量以及索引信息等,这些元信息是存储在CarbonData文件中的footer里。
当在内存中建立索引的时候都需要读取footer里面的信息,因为可以利用这些信息优化后续所有的查询。
每个blocklet又是由许多Data Chunks组成。Data Chunks里面的数据可以按列或者行的形式存储;数据既可以是单独的一列也可以是多列。文件中所有blocklets都包含相同数量和类型的Data Chunks。CarbonData文件格式如下图所示。
![CarbonData文件格式]()
每个Data Chunk又是由许多被称为Pages的单元组成。总共有三种类型的pages:
(1)Data Page:包含一列或者列组的编码数据;
(2)Row ID Page:包含行id的映射,在Data Page以反向索引的形式存储时会被使用;
(3)RLE Page:包含一些额外的元信息,只有在Data Page使用RLE编码的时候会被使用。
在一些给出的测试报告中,CarbonData的查询性能要优与Parquet和Orc (作为列村格式一起比较)。
CarbonData的问题是它对于Spark的依赖比较重。
Apache Kudu
Apache Kudu是一种数据存储技术,可以对快速数据进行快速分析。 Cloudera启动了该项目,但它是完全开源的。 Kudu提供快速插入和更新功能以及快速搜索功能,以加快分析速度。 它位于带有Parquet的HBase和Impala之间,试图消除快速扫描和快速随机访问之间的折衷。
![5分钟内的Apache Kudu]()
我们直到列存储对于分析优化,而HBase之类的数据库是对随机访问优化,Kudu希望在这两者中取得折衷,当然折衷的结果也可能是两者都不是最优。
像传统的关系数据库模型一样,Kudu需要在表上使用主键。 表具有列和原始数据类型,并支持更新。 如果要将关系数据库迁移到Hadoop集群,维护更新/删除可能是一个挑战。 这是由于"数据库"工具直接位于HDFS之上。 由于HDFS是一次写入的架构,因此更新行可能会很困难,因为您必须通过重写基础数据来复制此功能。
它不使用HDFS。 但是,它可以与HDFS在同一群集上共存。 您可以在Kudu常见问题解答页面上找到做出此设计决定的多种原因。
每个表必须具有一个唯一的主键。 这充当索引,以允许快速访问更新和删除。 表由平板电脑组成,就像分区一样。 平板电脑可跨多个节点复制,以实现弹性。 数据以列形式存储。 这意味着由于每个列中的所有数据都按顺序存储,因此列式聚合更快。 这也意味着可以更轻松地对数据进行矢量化和压缩,因为每列的所有数据都是同一类型。
![5分钟内的Apache Kudu]()
尽管Kudu位于HDFS之外,但它仍然是Hadoop集群上的"好公民"。 它可以与HDFS节点共享数据磁盘,并且占用的内存很少。 它还允许您透明地将Kudu表与Hadoop中其他位置(包括HBase表)存储的数据连接在一起。
总结
在你的大数据应用中,文件存储是不可少的部分,如何选择最适合的存储格式是很重要的。
- 为了节省存储空间和I/O,你需要考虑支持压缩和二进制的序列化的格式,同时需要考虑是否有多语言和Schema的支持。这里Avro是不错的选择。
- 为了更好的支持分析类的查询,使用列存储格式例如Parquet,Orc。你也可以选择CarbonData和Apache Kudu
- Apache Arrow能有效的在计算系统之间交换数据
谢谢阅读,欢迎和我交流相关的话题。