大多数NoSQL数据库的基本理念是面向任务(task-oriented)的数据库管理系统。如同老生常谈:如果你唯一的工具是锤子,那么一切看起来都像钉子(If all you have is ahammer, everything looks like a nail.)。
![常见的四种非关系型数据库都适合什么业务场景?]()
现在我们有不同种类的锤子、起子、凿子、铲子,还有更多的工具来解决数据管理问题。当然,最好的方法是选择合适的工具来完成不同的工作,如果只用关系数据库事实上可能会适得其反。除SQL数据库外,其他的可以分成四类:
- 键值存储(key-value stores)
- 列式存储(column-family stores)
- 文档存储(document stores)
- 图数据库(graph databases)
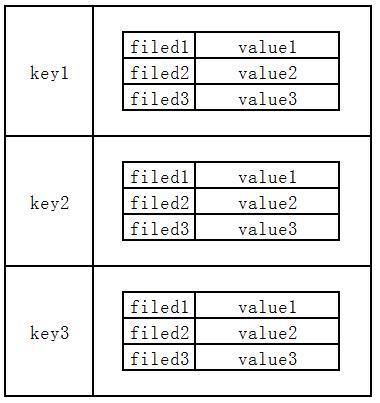
键值存储可能是最简单的面向任务的NoSQL数据库。其最初的数据模型并不复杂:主要基于亚马逊在两年一度的ACM操作系统研讨会(ACM Symposium on Operating SystemsPrinciples)上发布的白皮书,一篇叫Dynamo的论文。在此讨论的数据模型就是亚马逊的购物车系统(Amazon's shopping cart system),该系统要求高可用和高负载。因此,键值存储数据库的底层数据模型的确很简单:键和值存储为无模式(schema-less)数据模型。事实上,该系统采用大量的商业硬件搭建成集群,可扩展性非常高,并承载了多个高端应用,比如Amazon等。键值存储的产品还有DynamoDB、Riak、Project Voldemort、Redis、Aerospike等。
![常见的四种非关系型数据库都适合什么业务场景?]()
列式存储是另一个面向任务的数据库解决方案。其数据模型比键值存储稍复杂,包含一个大而稀疏的表结构,其中包括存储键的多个列。与Dynamo系统类似,列式存储也是源于一个特定公司的特殊需求,即Google公司提出的解决方案,发表在2006年OSDI会议(Operating SystemsDesign and Implementation symposium,操作系统设计与实现研讨会)上的BigTable论文中。除谷歌的产品外,还涌现出一批有趣的开源实现,如Apache Cassandra和HBase。大多数情况下,这些系统可结合Map/Reduce批处理来处理高级查询。
文件存储:随着网页和应用的爆炸式增长,文档存储可能是最有名、最常用的NoSQL数据库类型。顾名思义,文档存储中的关键概念——文档,是一个半结构化的信息单元,可以是XML、JSON、YAML、OpenOffice、MS Office,或者其他任何可用的文档。其存储和检索为简单的无模式方式。文档存储产品包括广受欢迎的MongoDB、Apache CouchDB、MarkLogic和Virtuoso等。
![常见的四种非关系型数据库都适合什么业务场景?]()
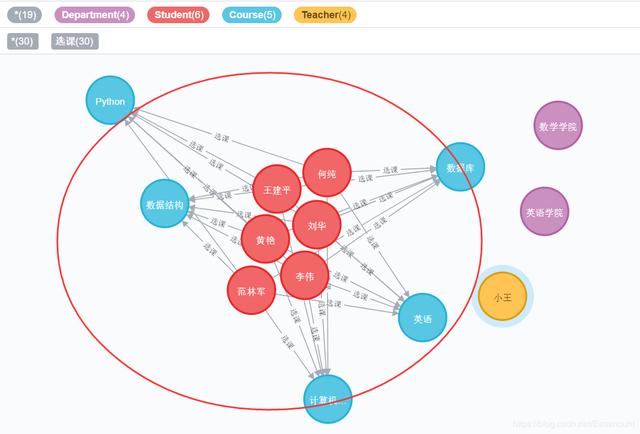
图数据库与其他三类有着本质上的差异。图数据库所要解决的问题与图和图论相关。图数据库,例如Neo4j,其目的是为用户提供一种更好的方法用于管理结构复杂、呈网状分布的数据。当然,基于图模型实现的解决方案并不仅有Neo4j,有的产品成熟度不同,有的开源或闭源,例如AllegroGraph、Dex、FlockDB、InfiniteGraph、OrientDB和Sones等。