K8s中的批处理任务模块主要是由Job控制器完成,今天我们就来关注下其底层的关键设计,包括完成状态、并行模式、并行策略等关键机制
1. 基础概念
在聊k8s的任务模块的实现的时候,我们先看一下传统的任务系统的设计与实现,然后聊下基于k8s的基础的概念
1.1 传统的任务系统设计
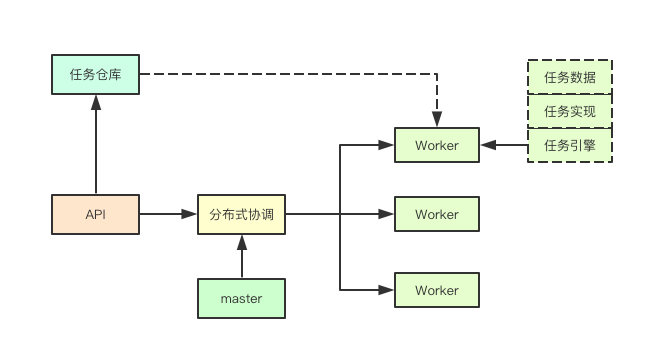
![image.png]() 传统的任务系统设计主要可以分为master(任务分配/故障感知/负载均衡)、Worker(任务执行/任务监控/任务管理)、分布式协调(etcd等存储元数据)、任务仓库(存储任务的实现比如类或者接口)等几部分, 从大的部分又可以切分为两个部分管控端(分布式协调/master/仓库)、执行端(Worker),传统的任务系统大概就是这样
传统的任务系统设计主要可以分为master(任务分配/故障感知/负载均衡)、Worker(任务执行/任务监控/任务管理)、分布式协调(etcd等存储元数据)、任务仓库(存储任务的实现比如类或者接口)等几部分, 从大的部分又可以切分为两个部分管控端(分布式协调/master/仓库)、执行端(Worker),传统的任务系统大概就是这样
通常复杂的就是如何在master如何做任务的负载均衡、任务的快速完成、依赖等管控功能,其次就是如何在worker端实现一个牛x的引擎,可以支持各种不同任务的执行环境和类型的执行
1.2 基于Pod的任务载体
![image.png]() k8s中的最小单元调度是Pod,同样的job控制器调度的最小单元也是Pod, Pod里面包含容器,以容器为载体k8s屏蔽了传统worker模块的任务执行环境与实现两个部分,只需要添加一些配置数据,对应的Pod就可以完成对应的任务的执行
k8s中的最小单元调度是Pod,同样的job控制器调度的最小单元也是Pod, Pod里面包含容器,以容器为载体k8s屏蔽了传统worker模块的任务执行环境与实现两个部分,只需要添加一些配置数据,对应的Pod就可以完成对应的任务的执行
1.3 简化的调度层
在k8s中Pod通常被定义为一个不稳定的单元,即k8s并不保证你的pod在被调度到某一台机器后就会一直的稳定运行,直到这台机器下线,这与传统的系统都不太一样,基于该特点,Job调度器的调度层其实也是一种面向于终态的设计。
大概就先介绍这些,接下来我们去分析k8s中job的核心实现机制
2. 核心实现
Job控制器的核心实现有几个关键点:并行粒度、完成状态、并行策略、并行模式、删除策略,记住这些关键点,我们来一一剖析
2.1 并行粒度
并行的粒度是指的针对同一任务可以同时有多少个并行的Pod即同时运行的Pod,Job控制器会根据用户设定的并行粒度确定需要同时运行的Pod
2.2 完成状态
在一些批处理调度的系统里面可能会通过数据分片后,等待所有分片的任务都完成后,来确定任务的完成状态,但是在k8s中Job控制器是一个通用的实现, 而且调度层本身也并不关注调度任务的具体数据 ![image.png]() 所以在k8s中里面其实是通过Completion的和backoffLimit来完成状态转移的,即通过Completion来确定需要等待的Pod的完成的数量,而通过backoffLimit确定到底可以允许失败重试的次数,确定重试多少次就认为任务失败了
所以在k8s中里面其实是通过Completion的和backoffLimit来完成状态转移的,即通过Completion来确定需要等待的Pod的完成的数量,而通过backoffLimit确定到底可以允许失败重试的次数,确定重试多少次就认为任务失败了
2.3 并行模式
在k8s的job控制器模式介绍中提到四种并发模式, 那实现上是不是真的有四种模式呢,答案是否定的。可以说k8s的job控制器根本也就不关注是那种模式,模式是应用层自己的设计,而job控制器只负责并行粒度、当前状态、完成状态
这里我们主要分析下Parallel JOb with a fix completion count和Parallel Job with a work queue的实现来聊聊Job控制器是如何实现的,两者很大的一个区别就是后者不能设置Completions,即不需要设置需要等待多少个Pod完成,为什么一个参数的设定就可以实现两者模式呢? ![image.png]() 答案就是期望的完成数量不同,如果Completions不设定,则实际上Job控制器发现有任一一个Pod成功并且当前活跃的Pod的数量为0,则表示当前任务完成, 该模式主要适用于单次的批任务,即本次批任务的所有Pod任务都完成,通常也意味着本次批任务是有限的集合
答案就是期望的完成数量不同,如果Completions不设定,则实际上Job控制器发现有任一一个Pod成功并且当前活跃的Pod的数量为0,则表示当前任务完成, 该模式主要适用于单次的批任务,即本次批任务的所有Pod任务都完成,通常也意味着本次批任务是有限的集合
而Completions设定为数量则意味着只需要完成指定数量的批任务,即任务可能类似于流处理模式,本次只期望完成一部分即可,即Completions设定数量的任务
2.4 并行策略
并行策略主要是指的如果我们指定的Parallelism的数量过大,为了避免单个任务同时创建大量的Job任务对集群带来的影响则采用分批逐次递增的策略,逐步完成并行所需要的Pod的更新
2.5 期望计数
![image.png]() 期望计数是k8s中控制器常见的机制,即当控制器进行Pod操作完成后,会设定当前期望的Pod的增加或者删除的计数,通过期望计数的统计来确定当前是否需要继续更新对应的pod, 期望的满足主要来源于两个地方:informer和当前控制流,informer通过监听apiserver来感知事件,而当前控制流则主要是在操作Pod失败的时候,直接更新期望,因为这些操作失败的Pod并不会从后续的informer中感知到
期望计数是k8s中控制器常见的机制,即当控制器进行Pod操作完成后,会设定当前期望的Pod的增加或者删除的计数,通过期望计数的统计来确定当前是否需要继续更新对应的pod, 期望的满足主要来源于两个地方:informer和当前控制流,informer通过监听apiserver来感知事件,而当前控制流则主要是在操作Pod失败的时候,直接更新期望,因为这些操作失败的Pod并不会从后续的informer中感知到
2.6 删除策略
我们提到过期望计数来决定是否更新状态,但这个并不保证一致性,很有可能因为事件的延迟导致控制器创建了大量的Pod此时就需要基于终态的继续调整,即需要根据当前的数量来删除部分的Pod, 删除策略主要是包含六点:1)未分配优先 2)未运行优先 3)未就绪优先 4)运行时间最短优先 5)重启次数多优先 6)创建时间较短优先
3. 总结
![image.png]() Job控制器的实现设计上还是很好玩的,主要是是面向常见的批处理场景,但本身并没有考虑优先级、关系、效率、分片等功能,只是一个通用的基础的任务调度的实现, 当前k8s中还有很多针对不同场景的专用任务调度实现,但基于k8s的任务系统设计本身就给我们降低了很多的复杂度,这也就是云原生带来的好处,今天就到这里,谢谢大家
Job控制器的实现设计上还是很好玩的,主要是是面向常见的批处理场景,但本身并没有考虑优先级、关系、效率、分片等功能,只是一个通用的基础的任务调度的实现, 当前k8s中还有很多针对不同场景的专用任务调度实现,但基于k8s的任务系统设计本身就给我们降低了很多的复杂度,这也就是云原生带来的好处,今天就到这里,谢谢大家
kubernetes学习笔记地址: https://www.yuque.com/baxiaoshi/tyado3
> 微信号:baxiaoshi2020 ![]() > 关注公告号阅读更多源码分析文章
> 关注公告号阅读更多源码分析文章 ![图解源码]() > 更多文章关注 www.sreguide.com
> 更多文章关注 www.sreguide.com
 传统的任务系统设计主要可以分为master(任务分配/故障感知/负载均衡)、Worker(任务执行/任务监控/任务管理)、分布式协调(etcd等存储元数据)、任务仓库(存储任务的实现比如类或者接口)等几部分, 从大的部分又可以切分为两个部分管控端(分布式协调/master/仓库)、执行端(Worker),传统的任务系统大概就是这样
传统的任务系统设计主要可以分为master(任务分配/故障感知/负载均衡)、Worker(任务执行/任务监控/任务管理)、分布式协调(etcd等存储元数据)、任务仓库(存储任务的实现比如类或者接口)等几部分, 从大的部分又可以切分为两个部分管控端(分布式协调/master/仓库)、执行端(Worker),传统的任务系统大概就是这样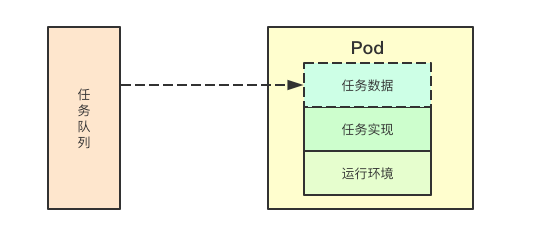 k8s中的最小单元调度是Pod,同样的job控制器调度的最小单元也是Pod, Pod里面包含容器,以容器为载体k8s屏蔽了传统worker模块的任务执行环境与实现两个部分,只需要添加一些配置数据,对应的Pod就可以完成对应的任务的执行
k8s中的最小单元调度是Pod,同样的job控制器调度的最小单元也是Pod, Pod里面包含容器,以容器为载体k8s屏蔽了传统worker模块的任务执行环境与实现两个部分,只需要添加一些配置数据,对应的Pod就可以完成对应的任务的执行 所以在k8s中里面其实是通过Completion的和backoffLimit来完成状态转移的,即通过Completion来确定需要等待的Pod的完成的数量,而通过backoffLimit确定到底可以允许失败重试的次数,确定重试多少次就认为任务失败了
所以在k8s中里面其实是通过Completion的和backoffLimit来完成状态转移的,即通过Completion来确定需要等待的Pod的完成的数量,而通过backoffLimit确定到底可以允许失败重试的次数,确定重试多少次就认为任务失败了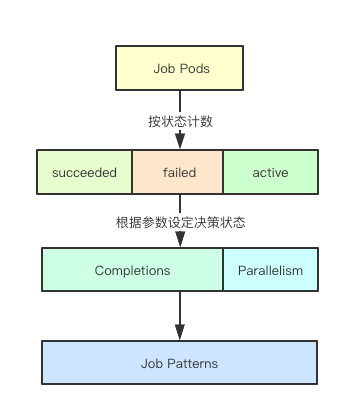 答案就是期望的完成数量不同,如果Completions不设定,则实际上Job控制器发现有任一一个Pod成功并且当前活跃的Pod的数量为0,则表示当前任务完成, 该模式主要适用于单次的批任务,即本次批任务的所有Pod任务都完成,通常也意味着本次批任务是有限的集合
答案就是期望的完成数量不同,如果Completions不设定,则实际上Job控制器发现有任一一个Pod成功并且当前活跃的Pod的数量为0,则表示当前任务完成, 该模式主要适用于单次的批任务,即本次批任务的所有Pod任务都完成,通常也意味着本次批任务是有限的集合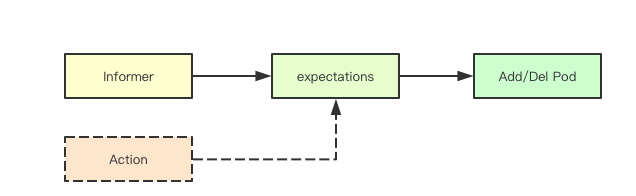 期望计数是k8s中控制器常见的机制,即当控制器进行Pod操作完成后,会设定当前期望的Pod的增加或者删除的计数,通过期望计数的统计来确定当前是否需要继续更新对应的pod, 期望的满足主要来源于两个地方:informer和当前控制流,informer通过监听apiserver来感知事件,而当前控制流则主要是在操作Pod失败的时候,直接更新期望,因为这些操作失败的Pod并不会从后续的informer中感知到
期望计数是k8s中控制器常见的机制,即当控制器进行Pod操作完成后,会设定当前期望的Pod的增加或者删除的计数,通过期望计数的统计来确定当前是否需要继续更新对应的pod, 期望的满足主要来源于两个地方:informer和当前控制流,informer通过监听apiserver来感知事件,而当前控制流则主要是在操作Pod失败的时候,直接更新期望,因为这些操作失败的Pod并不会从后续的informer中感知到 Job控制器的实现设计上还是很好玩的,主要是是面向常见的批处理场景,但本身并没有考虑优先级、关系、效率、分片等功能,只是一个通用的基础的任务调度的实现, 当前k8s中还有很多针对不同场景的专用任务调度实现,但基于k8s的任务系统设计本身就给我们降低了很多的复杂度,这也就是云原生带来的好处,今天就到这里,谢谢大家
Job控制器的实现设计上还是很好玩的,主要是是面向常见的批处理场景,但本身并没有考虑优先级、关系、效率、分片等功能,只是一个通用的基础的任务调度的实现, 当前k8s中还有很多针对不同场景的专用任务调度实现,但基于k8s的任务系统设计本身就给我们降低了很多的复杂度,这也就是云原生带来的好处,今天就到这里,谢谢大家 > 关注公告号阅读更多源码分析文章
> 关注公告号阅读更多源码分析文章  > 更多文章关注
> 更多文章关注 