在之前的文章中分析过kubernetes是如何进行多版本管理中提到了一个关键的设计解码器, 负责将请求对象反序列化成一个具体的数据模型,今天一起来了解下其内部是如何实现多版本管理、转换的设计要点
1.版本化管理的关键设计
1.1 从拓扑转换到星状转换
在通常的web开发中更多的时候,大家都是断代向前兼容更新,大多数情况下当版本更新之后会独立演进,如果要在多版本之间转换通常则会出现如下的情况 ![image.png]() 如果我们要为每个版本都去适配其他所有的版本,则复杂度会指数级上升,而在kubernetes中则通过一个内部版本的设计来进行解决,内部版本是一个稳定的版本,所有的版本都只针对目标版本来进行转换的实现,而不关注其他版本
如果我们要为每个版本都去适配其他所有的版本,则复杂度会指数级上升,而在kubernetes中则通过一个内部版本的设计来进行解决,内部版本是一个稳定的版本,所有的版本都只针对目标版本来进行转换的实现,而不关注其他版本
1.2 兼容设计之转换
![image.png]() 那如果谋个版本需要独立的演进,或者增设一些新的字段,修改字段名称等破坏性更新的时候,则就需要一种转换机制,负责在当前版本和内部版本之间来进行字段或者数据的转换
那如果谋个版本需要独立的演进,或者增设一些新的字段,修改字段名称等破坏性更新的时候,则就需要一种转换机制,负责在当前版本和内部版本之间来进行字段或者数据的转换
1.3 转换的最终之反射
![image.png]() 转换其实核心目标是完成从目标对象的字段中获取数据,然后经过一系列操作最终为目标对象的对应的字段进行赋值操作,要完成该操作,则就需要借助反射来实现,通过枚举字段,来获取对应的转换函数,执行转换函数,完成目标赋值
转换其实核心目标是完成从目标对象的字段中获取数据,然后经过一系列操作最终为目标对象的对应的字段进行赋值操作,要完成该操作,则就需要借助反射来实现,通过枚举字段,来获取对应的转换函数,执行转换函数,完成目标赋值
2. 关键设计的实现
为了实现上面的方案,kubernetes中设计了如下组件:Scheme(负责各个版本的注册和管理)、Convert(转换实现)、Serializer(实现对应版本的反序列化),让我们依次看下其关键设计
2.1 Convert
![image.png]()
Convert实现从一个目标对象到另外一个目标对象的转换, 为了实现这种转换,kubernetes里面主要是借助反射和不同版本的转换函数来共同完成
1.首先我们通过目标函数来获取对应的属性字段,然后针对该字段进行计算赋值操作 2.如果发现对应的字段需要来转换,则会调用对应的转换函数来进行赋值操作,如果不需要转换则会直接通过反射来进行赋值
2.2 外部版本到内部版本的转换
![image.png]() 在构建rest接口的时候,每个rest接口都会持有一个生成当前版本对象的构造函数,当请求进入之后,会首先通过目标版本获取对应的decoder decoder会利用当前的GroupVersionKind来进行第一步解析,首先将字节数组解析成当前版本,然后在解析成目标对象之后,又会根据目标版本进行转换
在构建rest接口的时候,每个rest接口都会持有一个生成当前版本对象的构造函数,当请求进入之后,会首先通过目标版本获取对应的decoder decoder会利用当前的GroupVersionKind来进行第一步解析,首先将字节数组解析成当前版本,然后在解析成目标对象之后,又会根据目标版本进行转换
2.3 Scheme
![image.png]() Scheme负责各个资源版本的统一注册和管理,为其他组件提供根据GVK来获取对应的资源对象,也提供通过资源对象获取版本等操作,内部还持有convert对象,包装了源对象到目标对象的转换操作
Scheme负责各个资源版本的统一注册和管理,为其他组件提供根据GVK来获取对应的资源对象,也提供通过资源对象获取版本等操作,内部还持有convert对象,包装了源对象到目标对象的转换操作
Scheme对象是一个复合的数据结构,其实现了多种结果,诸如typer、defaulter、creater等,很多地方都是通过直接传递scheme来进行对应的参数的填充, 其内部关键数据结构如下
GVK与资源类型的映射,以及当前资源类型支持哪些GVK
gvkToType map[schema.GroupVersionKind]reflect.Type
typeToGVK map[reflect.Type][]schema.GroupVersionKind
则创建对象的时候可以直接通过New来实例化对应的对象
func (s *Scheme) New(kind schema.GroupVersionKind) (Object, error) {
if t, exists := s.gvkToType[kind]; exists {
// 利用反射来创建对象
return reflect.New(t).Interface().(Object), nil
}
// 省略相关代码
}
默认初始化函数
defaulterFuncs map[reflect.Type]func(interface{})
根据对应的类型来完成初始化操作
func (s *Scheme) Default(src Object) {
if fn, ok := s.defaulterFuncs[reflect.TypeOf(src)]; ok {
fn(src)
}
}
提供转换函数注册接口, 注册到convert中
func (s *Scheme) AddConversionFunc(a, b interface{}, fn conversion.ConversionFunc) error {
return s.converter.RegisterUntypedConversionFunc(a, b, fn)
}
3.学习总结
![image.png]() 实现上无疑是复杂的作为一个工业设计有很多需要care的边缘情况,剖丝抽茧每个人看到的都不一样,这可能就是源码阅读的乐趣,从上面可以看到核心其实就三个点:将HTTP数据反序列化成为当前URL的资源对象,然后目标资源对象进行初始化默认值函数的执行,最后通过convert来处理不同版本之间的差异,最后统一操作内部版本,好了今天就到这了,希望对大家有所帮助 > 微信号:baxiaoshi2020
实现上无疑是复杂的作为一个工业设计有很多需要care的边缘情况,剖丝抽茧每个人看到的都不一样,这可能就是源码阅读的乐趣,从上面可以看到核心其实就三个点:将HTTP数据反序列化成为当前URL的资源对象,然后目标资源对象进行初始化默认值函数的执行,最后通过convert来处理不同版本之间的差异,最后统一操作内部版本,好了今天就到这了,希望对大家有所帮助 > 微信号:baxiaoshi2020 ![]() > 关注公告号阅读更多源码分析文章
> 关注公告号阅读更多源码分析文章 ![21天大棚]() > 更多文章关注 www.sreguide.com > 本文由博客一文多发平台 OpenWrite 发布
> 更多文章关注 www.sreguide.com > 本文由博客一文多发平台 OpenWrite 发布
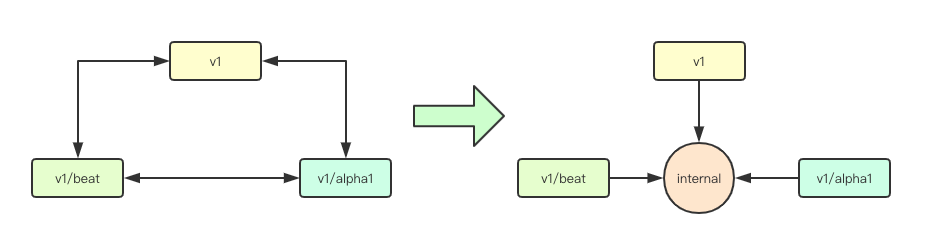 如果我们要为每个版本都去适配其他所有的版本,则复杂度会指数级上升,而在kubernetes中则通过一个内部版本的设计来进行解决,内部版本是一个稳定的版本,所有的版本都只针对目标版本来进行转换的实现,而不关注其他版本
如果我们要为每个版本都去适配其他所有的版本,则复杂度会指数级上升,而在kubernetes中则通过一个内部版本的设计来进行解决,内部版本是一个稳定的版本,所有的版本都只针对目标版本来进行转换的实现,而不关注其他版本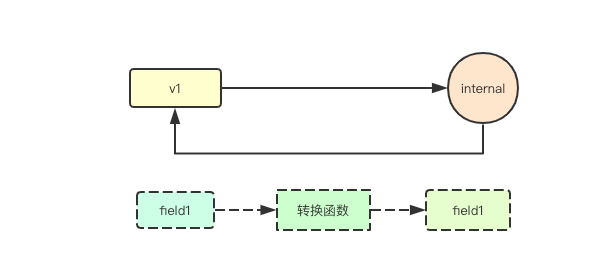 那如果谋个版本需要独立的演进,或者增设一些新的字段,修改字段名称等破坏性更新的时候,则就需要一种转换机制,负责在当前版本和内部版本之间来进行字段或者数据的转换
那如果谋个版本需要独立的演进,或者增设一些新的字段,修改字段名称等破坏性更新的时候,则就需要一种转换机制,负责在当前版本和内部版本之间来进行字段或者数据的转换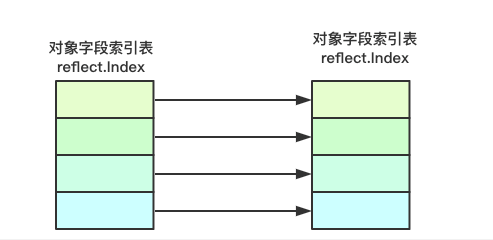 转换其实核心目标是完成从目标对象的字段中获取数据,然后经过一系列操作最终为目标对象的对应的字段进行赋值操作,要完成该操作,则就需要借助反射来实现,通过枚举字段,来获取对应的转换函数,执行转换函数,完成目标赋值
转换其实核心目标是完成从目标对象的字段中获取数据,然后经过一系列操作最终为目标对象的对应的字段进行赋值操作,要完成该操作,则就需要借助反射来实现,通过枚举字段,来获取对应的转换函数,执行转换函数,完成目标赋值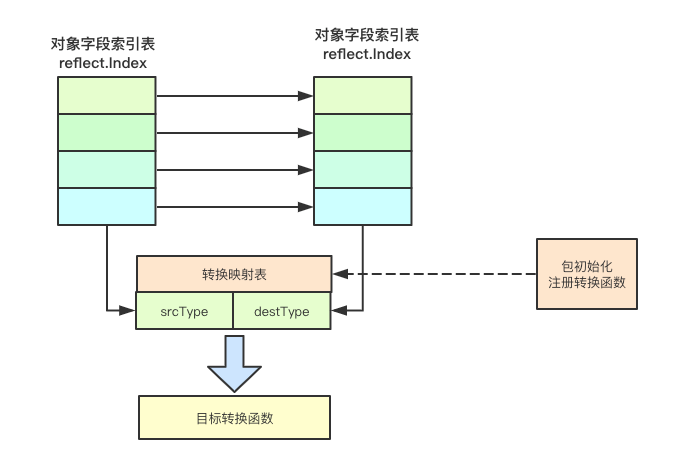
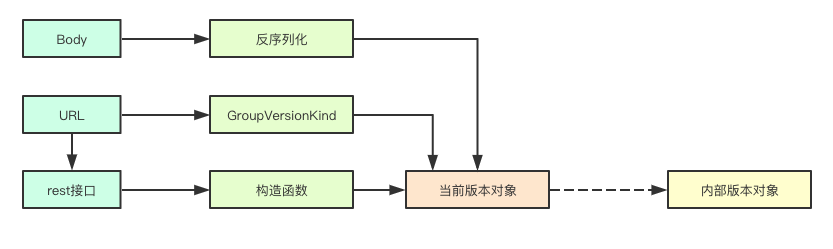 在构建rest接口的时候,每个rest接口都会持有一个生成当前版本对象的构造函数,当请求进入之后,会首先通过目标版本获取对应的decoder decoder会利用当前的GroupVersionKind来进行第一步解析,首先将字节数组解析成当前版本,然后在解析成目标对象之后,又会根据目标版本进行转换
在构建rest接口的时候,每个rest接口都会持有一个生成当前版本对象的构造函数,当请求进入之后,会首先通过目标版本获取对应的decoder decoder会利用当前的GroupVersionKind来进行第一步解析,首先将字节数组解析成当前版本,然后在解析成目标对象之后,又会根据目标版本进行转换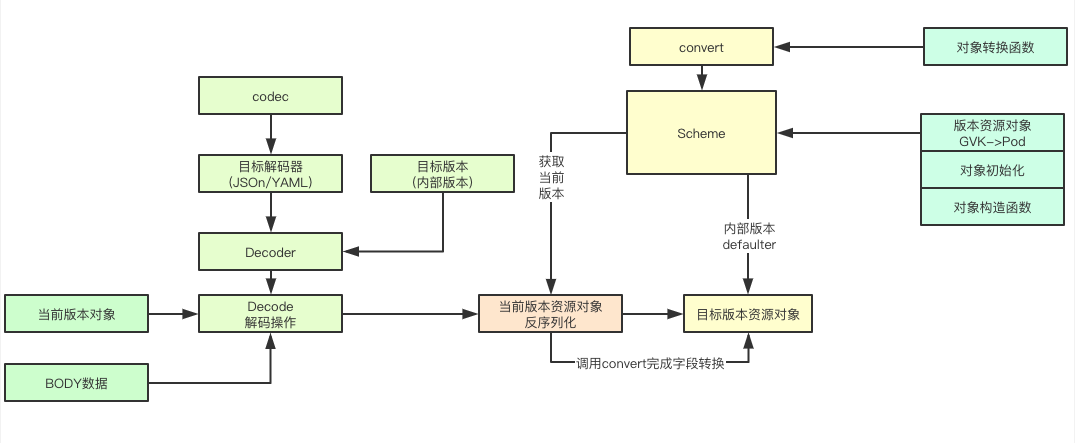 Scheme负责各个资源版本的统一注册和管理,为其他组件提供根据GVK来获取对应的资源对象,也提供通过资源对象获取版本等操作,内部还持有convert对象,包装了源对象到目标对象的转换操作
Scheme负责各个资源版本的统一注册和管理,为其他组件提供根据GVK来获取对应的资源对象,也提供通过资源对象获取版本等操作,内部还持有convert对象,包装了源对象到目标对象的转换操作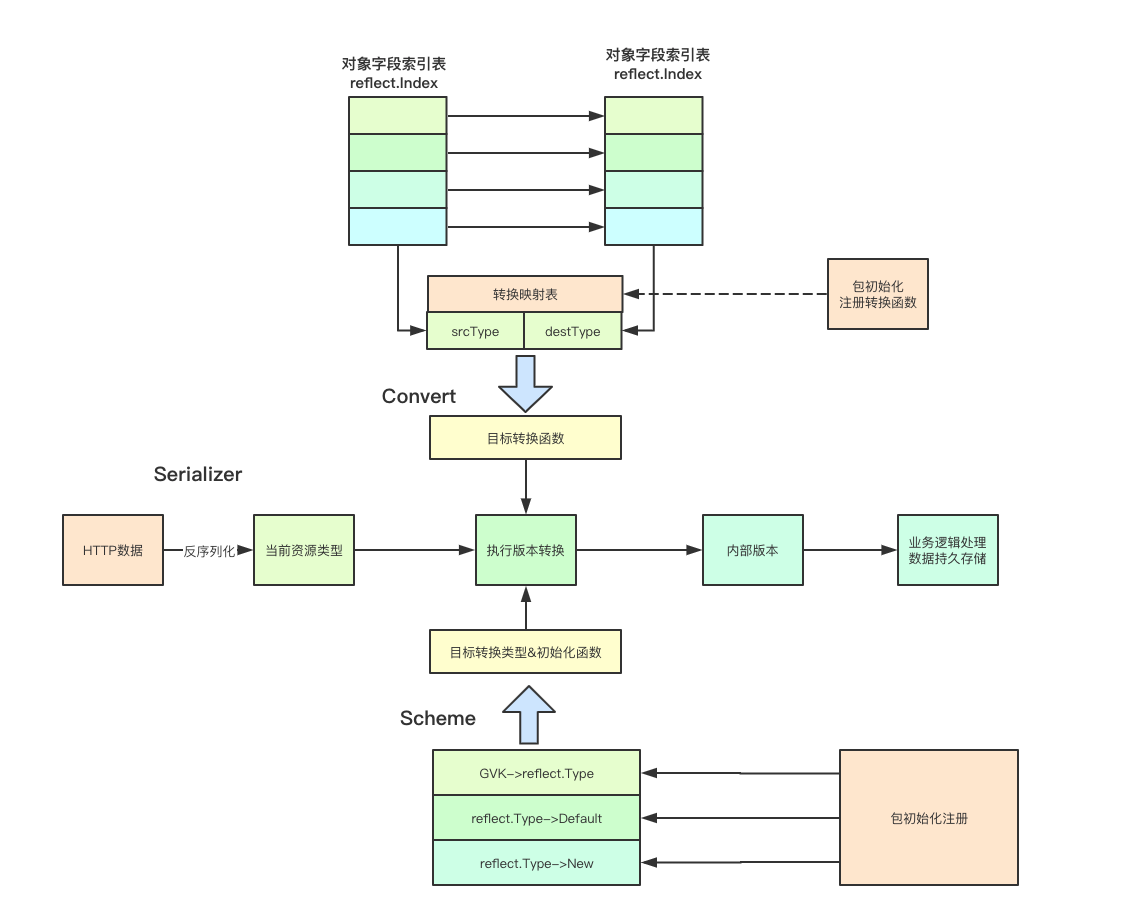 实现上无疑是复杂的作为一个工业设计有很多需要care的边缘情况,剖丝抽茧每个人看到的都不一样,这可能就是源码阅读的乐趣,从上面可以看到核心其实就三个点:将HTTP数据反序列化成为当前URL的资源对象,然后目标资源对象进行初始化默认值函数的执行,最后通过convert来处理不同版本之间的差异,最后统一操作内部版本,好了今天就到这了,希望对大家有所帮助 > 微信号:baxiaoshi2020
实现上无疑是复杂的作为一个工业设计有很多需要care的边缘情况,剖丝抽茧每个人看到的都不一样,这可能就是源码阅读的乐趣,从上面可以看到核心其实就三个点:将HTTP数据反序列化成为当前URL的资源对象,然后目标资源对象进行初始化默认值函数的执行,最后通过convert来处理不同版本之间的差异,最后统一操作内部版本,好了今天就到这了,希望对大家有所帮助 > 微信号:baxiaoshi2020  > 关注公告号阅读更多源码分析文章
> 关注公告号阅读更多源码分析文章  > 更多文章关注
> 更多文章关注 