> 本文只讲原理,不讲框架。
分布式系统中日志追踪需要考虑的几个点?
- 需要一个全服务唯一的id,即traceId,如何保证?
- traceId如何在服务间传递?
- traceId如何在服务内部传递?
- traceId如何在多线程中传递?
我们一一来解答:
- 全服务唯一的traceId,可以使用uuid生成,正常来说不会出现重复的;
- 关于服务间传递,对于调用者,在协议头加上traceId,对于被调用者,通过前置拦截器或者过滤器统一拦截;
- 关于服务内部传递,可以使用ThreadLocal传递traceId,一处放置,随处可用;
- 关于多线程传递,分为两种情况:
- 子线程,可以使用InheritableThreadLocal
- 线程池,需要改造线程池对提交的任务进行包装,把提交者的traceId包装到任务中
![hash]()
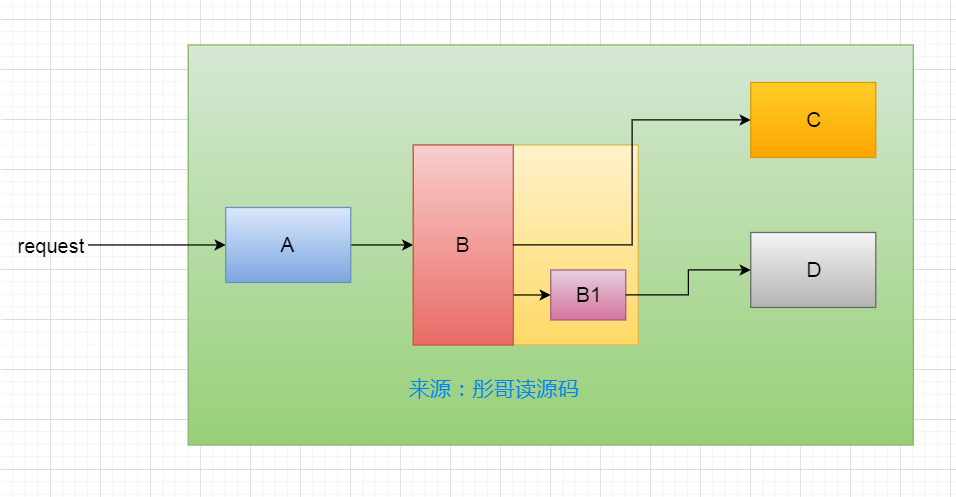
比如,上面这个系统,系统入口在A处,A调用B的服务,B里面又起了一个线程B1去访问D的服务,B本身又去访问C服务。
我们就可以这么来跟踪日志:
- 所有服务都需要一个全局的InheritableThreadLocal保存服务内部traceId的传递;
- 所有服务都需要一个前置拦截器或者过滤器,检测如果请求头没有traceId就生成一个,如果有就取出来,并把traceId放到全局的InheritableThreadLocal里面;
- 一个服务调用另一个服务的时候把traceId塞到请求头里,比如http header,本文来源于工从号彤哥读源码;
- 改造线程池,在提交的时候包装任务,这个工作量比较大,因为服务内部可能依赖其它框架,这些框架的线程池有可能也需要修改;
实现
我们模拟A到B这两个服务来实现一个日志跟踪系统。
为了简单起见,我们使用SpringBoot,它默认使用的日志框架是logback,而且Slf4j提供了一个包装了InheritableThreadLocal的类叫MDC,我们只要把traceId放在MDC中,打印日志的时候统一打印就可以了,不用显式地打印traceId。
我们分成三个模块:
- 公共包:封装拦截器,traceId的生成,服务内传递,请求头的传递等;
- A服务:只依赖于公共包,并提供一个接口接收外部请求;
- B服务:依赖于公共包,并内部起一个线程池,用于发送B1->D的请求,当然我们这里不发送请求,只在线程池中简单地打印一条日志;
公共包
- TraceFilter.java
前置过滤器,用拦截器实现也是一样的。
从请求头中获取traceId,如果不存在就生成一个,并放入MDC中。
@Slf4j
@WebFilter("/**")
@Component
public class TraceFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain chain) throws IOException, ServletException {
HttpServletRequest request = (HttpServletRequest) servletRequest;
// 从请求头中获取traceId
String traceId = request.getHeader("traceId");
// 不存在就生成一个
if (traceId == null || "".equals(traceId)) {
traceId = UUID.randomUUID().toString();
}
// 放入MDC中,本文来源于工从号彤哥读源码
MDC.put("traceId", traceId);
chain.doFilter(servletRequest, servletResponse);
}
@Override
public void destroy() {
}
}
- TraceThreadPoolExecutor.java
改造线程池,提交任务的时候进行包装。
public class TraceThreadPoolExecutor extends ThreadPoolExecutor {
public TraceThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<runnable> workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
}
public TraceThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<runnable> workQueue, ThreadFactory threadFactory) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory);
}
public TraceThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<runnable> workQueue, RejectedExecutionHandler handler) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, handler);
}
public TraceThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory, handler);
}
@Override
public void execute(Runnable command) {
// 提交者的本地变量
Map<string, string> contextMap = MDC.getCopyOfContextMap();
super.execute(()->{
if (contextMap != null) {
// 如果提交者有本地变量,任务执行之前放入当前任务所在的线程的本地变量中
MDC.setContextMap(contextMap);
}
try {
command.run();
} finally {
// 任务执行完,清除本地变量,以防对后续任务有影响
MDC.clear();
}
});
}
}
- TraceAsyncConfigurer.java
改造Spring的异步线程池,包装提交的任务。
@Slf4j
@Component
public class TraceAsyncConfigurer implements AsyncConfigurer {
@Override
public Executor getAsyncExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(8);
executor.setMaxPoolSize(16);
executor.setQueueCapacity(100);
executor.setThreadNamePrefix("async-pool-");
executor.setTaskDecorator(new MdcTaskDecorator());
executor.setWaitForTasksToCompleteOnShutdown(true);
executor.initialize();
return executor;
}
@Override
public AsyncUncaughtExceptionHandler getAsyncUncaughtExceptionHandler() {
return (throwable, method, params) -> log.error("asyc execute error, method={}, params={}", method.getName(), Arrays.toString(params));
}
public static class MdcTaskDecorator implements TaskDecorator {
@Override
public Runnable decorate(Runnable runnable) {
Map<string, string> contextMap = MDC.getCopyOfContextMap();
return () -> {
if (contextMap != null) {
MDC.setContextMap(contextMap);
}
try {
runnable.run();
} finally {
MDC.clear();
}
};
}
}
}
- HttpUtils.java
封装Http工具类,把traceId加入头中,带到下一个服务。
@Slf4j
public class HttpUtils {
public static String get(String url) throws URISyntaxException {
RestTemplate restTemplate = new RestTemplate();
MultiValueMap<string, string> headers = new HttpHeaders();
headers.add("traceId", MDC.get("traceId"));
URI uri = new URI(url);
RequestEntity<!--?--> requestEntity = new RequestEntity<>(headers, HttpMethod.GET, uri);
ResponseEntity<string> exchange = restTemplate.exchange(requestEntity, String.class);
if (exchange.getStatusCode().equals(HttpStatus.OK)) {
log.info("send http request success");
}
return exchange.getBody();
}
}
A服务
A服务通过Http调用B服务。
@Slf4j
@RestController
public class AController {
@RequestMapping("a")
public String a(String name) {
log.info("Hello, " + name);
try {
// A中调用B
return HttpUtils.get("http://localhost:8002/b");
} catch (Exception e) {
log.error("call b error", e);
}
return "fail";
}
}
A服务的日志输出格式:
中间加了[%X{traceId}]一串表示输出traceId。
# 本文来源于工从号彤哥读源码
logging:
pattern:
console: '%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(%5p) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr([%X{traceId}]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n%wEx'
B服务
B服务内部有两种跨线程调用:
BController.java
@Slf4j
@RestController
public class BController {
@Autowired
private BService bService;
@RequestMapping("b")
public String b() {
log.info("Hello, b receive request from a");
bService.sendMsgBySpring();
bService.sendMsgByThreadPool();
return "ok";
}
}
BService.java
@Slf4j
@Service
public class BService {
public static final TraceThreadPoolExecutor threadPool = new TraceThreadPoolExecutor(5, 5, 60, TimeUnit.SECONDS, new LinkedBlockingQueue<>(100));
@Async
public void sendMsgBySpring() {
log.info("send msg by spring success");
}
public void sendMsgByThreadPool() {
threadPool.execute(()->log.info("send msg by thread pool success"));
}
}
B服务的日志输出格式:
中间加了[%X{traceId}]一串表示输出traceId。
logging:
pattern:
console: '%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(%5p) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr([%X{traceId}]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n%wEx'
测试
打开浏览器,输入http://localhost:8001/a?name=andy。
A服务输出日志:
2019-12-26 21:36:29.132 INFO 5132 --- [nio-8001-exec-2] [8a59cb96-bbc8-42a9-aa62-df7a52875447] com.alan.trace.a.AController : Hello, andy
2019-12-26 21:36:35.380 INFO 5132 --- [nio-8001-exec-2] [8a59cb96-bbc8-42a9-aa62-df7a52875447] com.alan.trace.common.HttpUtils : send http request success
B服务输出日志:
2019-12-26 21:36:29.244 INFO 2368 --- [nio-8002-exec-1] [8a59cb96-bbc8-42a9-aa62-df7a52875447] com.alan.trace.b.BController : Hello, b receive request from a
2019-12-26 21:36:29.247 INFO 2368 --- [nio-8002-exec-1] [8a59cb96-bbc8-42a9-aa62-df7a52875447] o.s.s.concurrent.ThreadPoolTaskExecutor : Initializing ExecutorService
2019-12-26 21:36:35.279 INFO 2368 --- [ async-pool-1] [8a59cb96-bbc8-42a9-aa62-df7a52875447] com.alan.trace.b.BService : send msg by spring success
2019-12-26 21:36:35.283 INFO 2368 --- [pool-1-thread-1] [8a59cb96-bbc8-42a9-aa62-df7a52875447] com.alan.trace.b.BService : send msg by thread pool success
可以看到,A服务成功生成了traceId,并且传递给了B服务,且B服务线程间可以保证同一个请求的traceId是可以传递的。
![]() </string></string,></string,></string,></runnable></runnable></runnable></runnable>
</string></string,></string,></string,></runnable></runnable></runnable></runnable>
 </string></string,></string,></string,></runnable></runnable></runnable></runnable>
</string></string,></string,></string,></runnable></runnable></runnable></runnable>