ceph 集群分裂
1 原理
![]()
![]()
1.1 概述
ceph 集群分裂,本来就是一个违反常理的事情。从ceph的设计原理上就是预防分裂,而且很对分裂有一个专有名词“脑裂”。
什么是脑裂?1个集群分裂为 2个集群叫做脑裂。
预防脑裂的原理:不管是mon,还是osd,服务个数至少>服务个数的一半,也就是经典的>=2n+1 理论。比如:
集群有3个mon服务,活动的mon至少大于等于2个,否则集群不能提供服务。osd也一样,3副本的时候,至少活动的个数超过2副本否则不可用。
1.2 场景
在有些场景中需要ceph集群迁移到其他服务器,但是源服务器上的数据又要保持不变,这就需要对ceph 进行人为分裂,也叫做“欺骗性脑裂”
1.3 原理
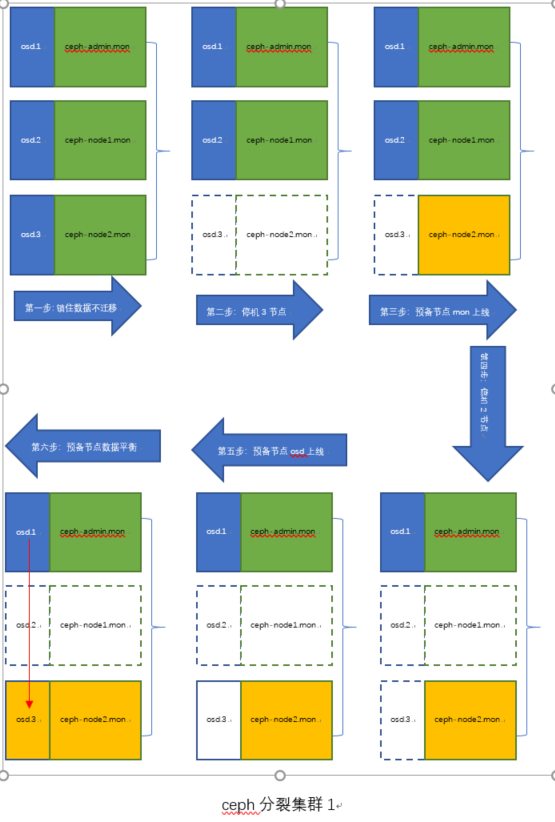
例如ceph集群3节点,3 mon,3osd 。ceph-admin ,ceph-node1,ceph-node2.
1 先设置集群数据不迁移使得数据在每个服务器上分布保持稳定
2 节点ceph-node2 停机
3 预备机ceph-test 系统环境,参数,软件 安装设置和ceph-node2一模一样,用来代替原来的ceph-node2
4 新ceph-node2 添加mon
5 ceph-node1 下线
6 删除老ceph-node2 遗留的下线的osd.2
7 新ceph-node2 osd 上线
8 设置集群数据可迁移进行数据平衡
9 当前分裂后的ceph集群1 是2个mon,2个osd,可以提供服务。
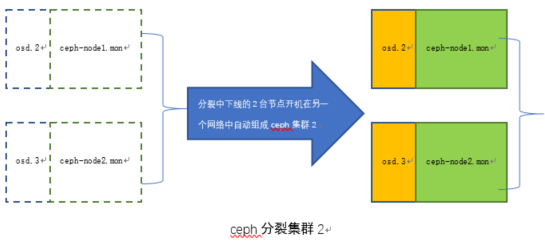
10 修改集群1的ip
11 启动下线的老的ceph-node2 和ceph-node1,组建集群2
12 放开集群2的数据迁移
13 扩容
分裂后的两个集群都是2副本,2节点。可以安装正常安装流程扩容至3节点3副本
2 停节点node2
先设置集群为不可迁移数据
ceph osd set nobackfill;
ceph osd set norecover;
再停机ceph-node2
shutdown -h now
3 添加新mon-node2
3.1 准备新节点node2
下面这些操作其实都是可以提前做的
# 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
# 设置yum 源
cd /etc/yum.repos.d
[root@ceph-admin yum.repos.d]# cat ceph.repo
[Ceph]
name=Ceph packages for $basearch
baseurl=http://mirrors.ustc.edu.cn/ceph/rpm-luminous/el7/$basearch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=http://mirrors.ustc.edu.cn/ceph/keys/release.asc
priority=1
[Ceph-noarch]
name=Ceph noarch packages
baseurl=http://mirrors.ustc.edu.cn/ceph/rpm-luminous/el7/noarch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=http://mirrors.ustc.edu.cn/ceph/keys/release.asc
priority=1
[ceph-source]
name=Ceph source packages
baseurl=http://mirrors.ustc.edu.cn/ceph/rpm-luminous/el7/SRPMS
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=http://mirrors.ustc.edu.cn/ceph/keys/release.asc
priority=1
[root@ceph-admin yum.repos.d]# cat epel.repo
[epel]
name=Extra Packages for Enterprise Linux 7 - $basearch
baseurl=http://mirrors.aliyun.com/epel/7/$basearch
#mirrorlist=https://mirrors.fedoraproject.org/metalink?repo=epel-7&arch=$basearch
failovermethod=priority
enabled=1
gpgcheck=0
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7
[epel-debuginfo]
name=Extra Packages for Enterprise Linux 7 - $basearch - Debug
baseurl=http://mirrors.aliyun.com/epel/7/$basearch/debug
#mirrorlist=https://mirrors.fedoraproject.org/metalink?repo=epel-debug-7&arch=$basearch
failovermethod=priority
enabled=0
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7
gpgcheck=0
[epel-source]
name=Extra Packages for Enterprise Linux 7 - $basearch - Source
baseurl=http://mirrors.aliyun.com/epel/7/SRPMS
#mirrorlist=https://mirrors.fedoraproject.org/metalink?repo=epel-source-7&arch=$basearch
failovermethod=priority
enabled=0
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7
gpgcheck=0
# 安装vim,net-tools,ceph 软件
yum install ceph ceph-radosgw ntp ntpdate net-tools vim -y
3.2 预备服务器修改IP
预备节点修改IP为原来ceph-node2 的IP,用来“欺骗”原有的ceph集群
sed -i "s/{old-ip}/{new-ip}/g" /etc/sysconfig/network-scripts/ifcfg-ens3
systemctl restart network
修改完IP后并重新从ceph-admin节点进行免密设置
ssh-copy-id -i ~/.ssh/id_rsa.pub ceph-node2
注意:应提前从ceph-admin中删除私钥否则公钥发送会出做(因为毕竟现在的ceph-node2 不是原来的ceph-node2,是假扮的)
cat ~/.ssh/known_hosts
3.3 添加新节点ceph-node2 的mon服务
ceph-deploy mon add ceph-node2
# 添加mon的时候可能出现下面错误
“bootstrap-osd keyring not found; run 'gatherkeys'"
解决办法:ceph-deploy gatherkeys ceph-node2
4 停节点node1
检查备用node2节点上mon服务一定要加入集群后才可以停node1节点
5 删除node2的osd.2
在node1 停机后,在ceph-admin上测试命令”ceph -s 是否可以查看集群状态。一定要可以访问集群后续才可以进行。
删除node2上的osd.2
ceph osd rm osd.2
ceph osd crush rm osd.2
ceph osd crush rm ceph-node2
6 删除node2的osd.2的秘钥
# 后续要重新把数据平衡到新的node2节点上的osd.2,所以要把之前老的osd.2 和osd.2的秘钥都删除
ceph auth rm osd.2
7 添加新的node2的osd.2
注意:
# parted 分区日志盘,这里就不多展示,参照ceph集群部署文档
# ceph-deploy osd create ceph-node2 --data /dev/vda --block-db /dev/vdb1 --block-wal /dev/vdc1
8 平衡数据
# 新的node2 上的osd.2添加成功后进行数据平衡
ceph osd unset nobackfill;
ceph osd unset norecover;
由于当前集群只有老的ceph-admin节点和新的ceph-node2节点,所以只有2副本。但是可以对外服务的。
9 扩容
当前集群只有2副本,2节点。如果扩容就按照正常部署步骤扩容就好。这里就不多展示
10 恢复对象存储rgw.node2
重新在新节点node2上安装对象存储实例就可以,参照ceph对象存储安装文档,这里就不多展示
11 恢复文件系统mds.osd.2
重新在新节点node2 上安装文件系统就可以,参照ceph 文件系统安装文档,这里就不多展示
12 验证
12.1 验证块存储
做rbd 创建,rbd映射,挂载,写入数据
12.2 验证对象存储
设置s3 对象存储客户端,创建桶,写入数据
12.3 验证文件系统
挂载远程目录