马蜂窝技术原创文章,更多干货请搜索公众号:mfwtech
使用 Docker+Kubernetes 来简化开发人员的工作流,使应用更加快速地迭代,缩短发布周期,在很多研发团队中已经是常见的做法。
如果说 Docker 提供的是应用级的主机抽象,那么 Kubernetes 的作用就是应用级的集群抽象,提供容器集群运行所需的基础设施,旨在解决容器化应用的资源调度、部署运行、服务发现、扩容缩容等问题。
一直以来,容器网络设计都被认为是非常重要,但相对复杂的部分。 本文要介绍的 Kubernetes 网络,目前主要为马蜂窝旅游网大多数 Java 业务提供开发环境的底层基础设施。随着团队的调整及业务需求升级,整个系统对网络架构的要求也越来越严苛。基于这样的背景,Kubernetes 网络过去一年多经历了两次比较重要的改造,以期不断降低运维调试成本,提高研发效率。
借由本文分享我们的实践经验,与君共勉。
Part.1 Kubernetes 网络原理及挑战
1. Kubernetes Pod 设计
Pod 是 Kubernetes 的基本调度单元,我们可以将 Pod 认为是容器的一种延伸扩展,一个 Pod 也是一个隔离体,而 Pod 内部又包含一组共享的容器。
每个 Pod 中的容器由一个特殊的 Pause 容器,及一个或多个紧密相关的业务容器组成。Pause 容器是 Pod 的根容器,对应的镜像属于 Kubernetes 平台的一部分,以它的状态代表整个容器组的状态。同一个 Pod 里的容器之间仅需通过 localhost 就能互相通信。
![]()
每个 Pod 会被 Kubernetes 网络组件分配一个唯一的(在集群内的 IP 地址,称为 Pod IP,这样就允许不同 Pod 中的服务可以使用同一端口 (同一个 Pod 中端口只能被一个服务占用),避免了发生端口冲突的问题。
2. 挑战
Pod 的 IP 是在 Kubernetes 集群内的,是虚拟且局域的。这就带来一个问题,Pod IP 在集群内部访问没有问题,但在实际项目开发中,难免会有真实网络环境下的应用需要访问 Kubernetes 集群里的容器,这就需要我们做一些额外的工作。
本文将结合我们开发环境下基于 K8S 容器网络演进的过程,介绍在 Pod IP 为虚拟或真实 IP 情况下的几种直接访问 Pod IP 的解决方案。
Part.2 基于 Kubernetes 的容器网络演进
第一阶段:Kubernetes + Flannel
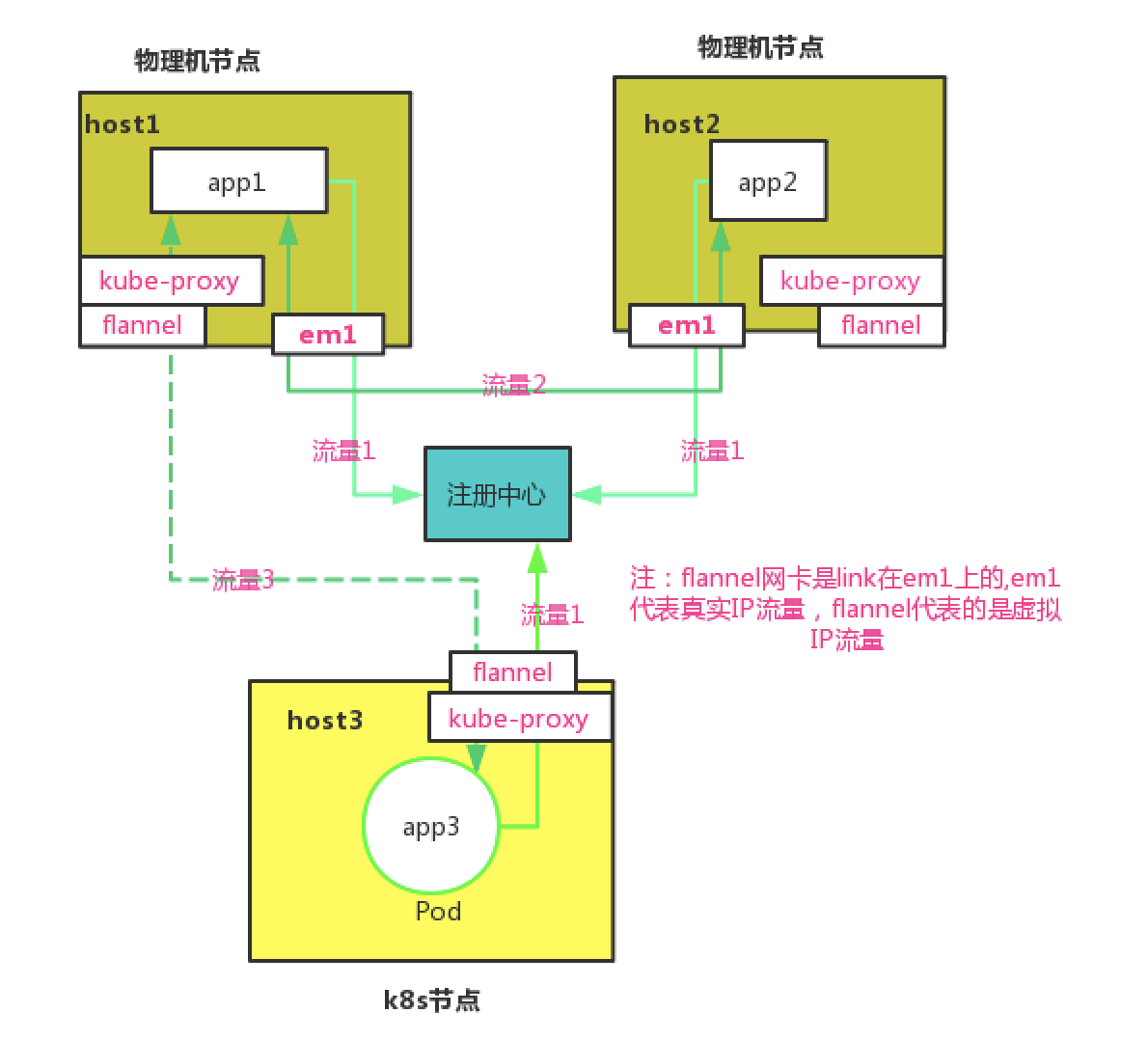
最早,我们的网络设计方案只服务于大交通业务。初期大交通的 Java 应用是部署在物理机上的,团队内部容器相关的底层基础设施几乎为 0。为了更加平稳地实现容器化的落地,中间我们没有直接把服务全部迁移到 K8S 中去,而是经历了一段混跑。
这个过程中必然会有物理机上的 Java 应用访问 K8S 里 Java 容器的情况 (一个注册中心)。当时我们选用的网络架构是 Flannel VXLAN + Kube-proxy,主要是考虑到 Flannel 的简洁性。
Flannel 是为 K8S 设计的一个非常简洁的多节点三层网络方案,主要用于解决容器的跨主机通信问题,是一个比较大一统的方案。它的设计目的是为集群中的所有节点重新规划 IP 地址的使用规则,从而使得不同节点上的容器能够获得「同属一个内网」且「不重复的」IP 地址,并让属于不同节点上的容器能够直接通过内网 IP 通信。
Flannel 的原理是为每个 host 分配一个 subnet,容器从此 subnet 中分配 IP,这些 IP 可以在 host 间路由,容器间无需 NAT 和 port mapping 就可以跨主机通信。每个 subnet 都是从一个更大的 IP 池中划分的,Flannel 会在每个 host 上面运行一个守护进程 flanneld,其职责就是从大池子中分配 subnet,为了各个主机间共享信息。Flannel 用 ETCD 存放网络配置、已分配的 subnet、host 的 IP 等信息。
Flannel 的节点间有三种通信方式:
我们在所有的业务物理机上都部署了 Flannel,并且启动 Flanneld 服务,使之加入 K8S 虚拟网络,这样物理机上的服务与 K8S 里的容器服务在互相调用时,就可以通过 Flannel+Kube-proxy 的虚拟网络。整体结构图如下:
![]()
第二阶段:Kubernetes + Flannel+ VPN-server
为了加速大交通业务微服务和容器化的落地,我们在团队内部完成了开发环境容器化的改造,并将所有流量全部迁移到 K8S 编排系统上。
大交通整体的微服务改造基于 Dubbo。了解的朋友都知道,Dubbo 服务中 Consumer 和 Provider 的通讯很常见,对应到我们的场景就有了本地 Dubbo 服务 (Consumer) 消费开发环境微服务 (Provider),以及本地远程 debug 开发环境的情况。但是 Dubbo consumer 从注册中心拿到的都是容器的虚拟网络 IP,在集群外的真实网络环境里根本访问不通。
为了解决这个问题,提高开发与联调效率,我们开始了第一次 K8S 容器网络方案的改造。
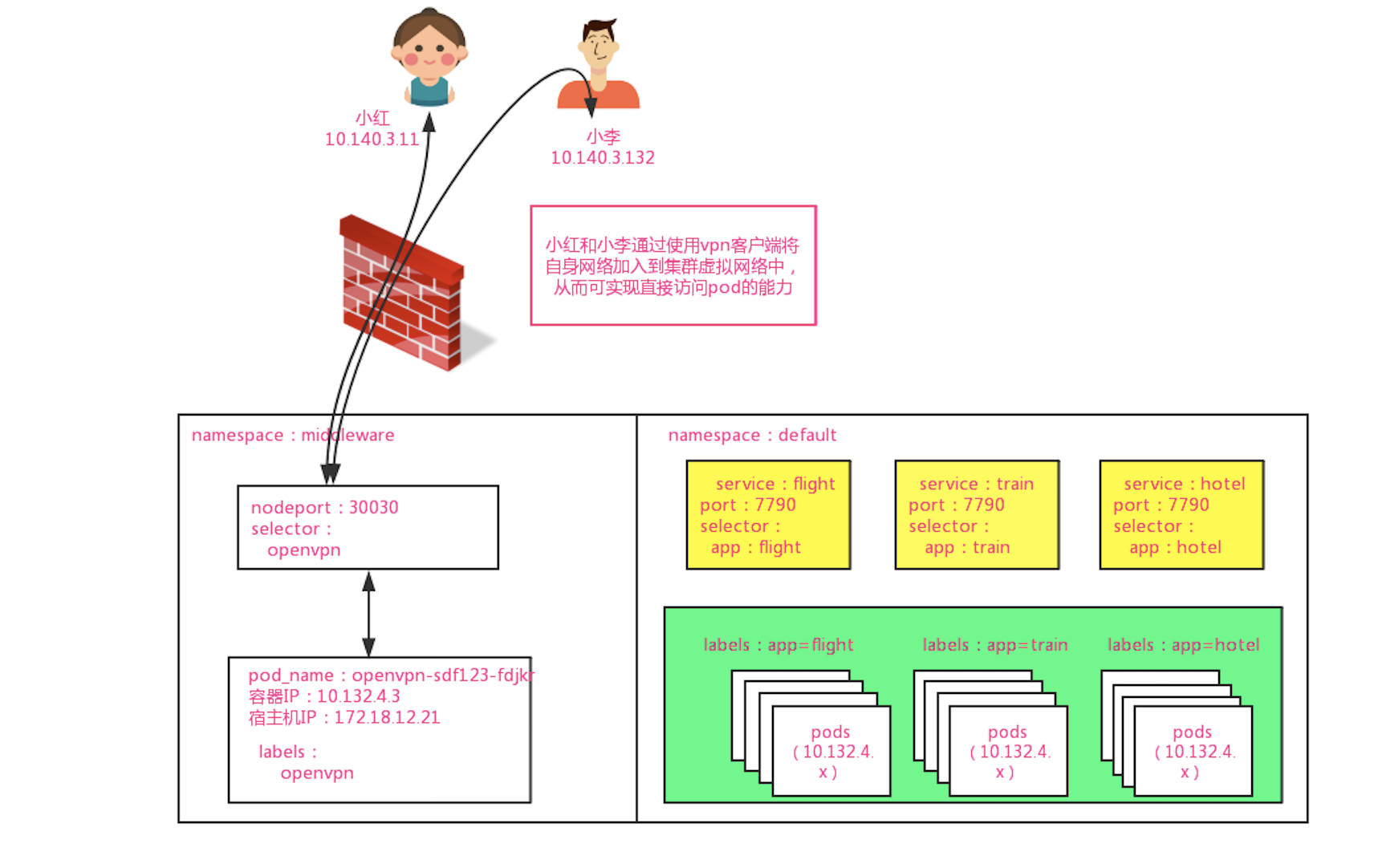
我们设想,既然一个公司的员工可以通过拨通 VPN,从公网进入到公司的内网,那如果在 K8S 集群内部署一个 OpenVPN 的 Server,是不是也可以从集群外进入到集群的内网之中?实现思路如下图所示:
![]()
-
我们在集群的 middleware 空间下以 nodeport 的方式部署了 VPN Server,并给客户端分配了 10.140 的网段
-
当客户端通过 172.18.12.21:30030 拨通 VPN 时,客户端与 VPN Server 间的网络被打通
-
因为 VPN Server 本身处于集群虚拟网络环境中,所以其他容器的 IP 对于 vpn server 是可见的,因此拨通 VPN 后,VPN 客户端就可以直接对集群内的 Pod 进行访问
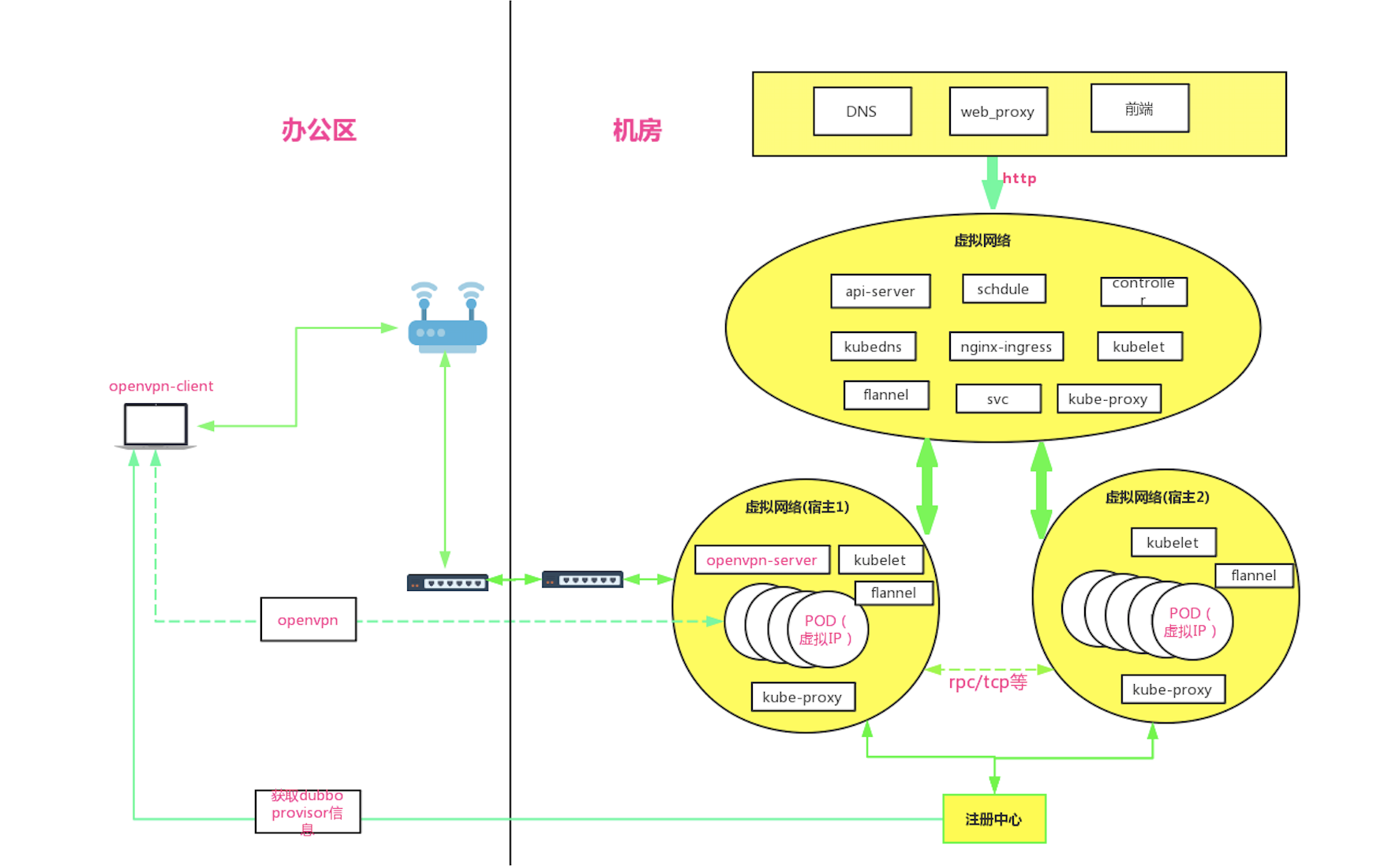
改造后开发环境与机房 K8S 集群之间的网络架构图如下所示:
![]()
通过在 K8S 集群里架设 OpenVPN,我们暂时解决了办公区对机房 K8S 集群的 RPC 通讯问题。该方案的优缺点如下:
优点:
不足:
第三阶段:基于 MAC-VLAN 的 Kubernetes CNI
为了更好地支持 Java 业务的微服务改造,避免重复造轮子,我们构建了统一的 Java 基础平台,之前的网络方案也面向更多的部门提供服务。
随着服务的业务和人员越来越多,由人工操作带来的不便和问题越来越明显,我们决定对 K8S 网络进行再一次改造。从之前的经验中我们感到,如果 K8S 的虚拟网络不去除,容器服务的 IP 是不可能直接由集群外的真实网络到达的。
为了快速满足不同业务场景下对于 K8S 网络功能的需求,我们开始深入研究 CNI。
关于 CNI
CNI (Conteinre Network Interface) 旨在为容器平台提供统一的网络标准,由 Google 和 CoreOS 主导制定。它本身并不是一个完整的解决方案或者程序代码,而是综合考虑了灵活性、扩展性、IP 分配、多网卡等因素后,在 RKT 的基础上发展起来的一种容器网络接口协议。
CNI 的网络分类和主流的实现工具主要包括:
MAC-VLAN 及其带来的问题
通过对比测试,考虑到当下需求,我们最终决定基于网络改造、运维成本和复杂度都较低的 MAC-VLAN 方案:
![]()
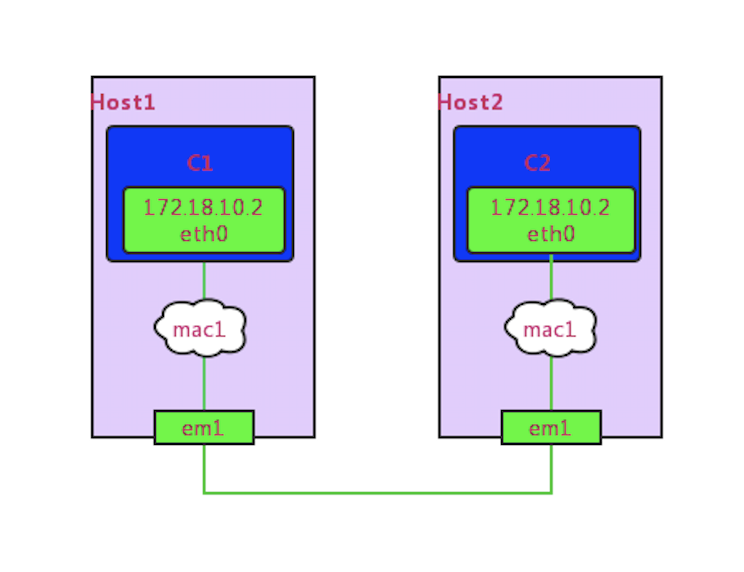
MAC-VLAN 具有 Linux Kernal 的特性,用于给一个物理网络接口(parent)配置虚拟化接口。虚拟化接口与 parent 网络接口拥有不同的 mac 地址,但 parent 接口上收到发给其对应的虚拟化接口的 mac 包时,会分发给对应的虚拟化接口,有点像将虚拟化接口和 parent 接口进行了「桥接」,使虚拟化网络接口在配置了 IP 和路由后就能互相访问。
在 MAC-VLAN 场景下,K8S 容器访问可能会遇到一些问题,比如配置 MAC-VLAN 后,容器不能访问 parent 接口的 IP。
通过调研,发现有以下两种解决方案:
1. 虚拟网卡:打开网卡混杂模式,通过在宿主机上虚拟出一个虚拟网卡,将虚拟网卡与宿主机真实网卡聚合绑定
2. PTP 方案:类似 Bridge 的简化版,但是网络配置更复杂,并且有一些配置在自测过程中发现并没有太大用处。与 Bridge 主要的不同是 PTP 不使用网桥,而是直接使用 vethpair+路由配置。
通过对比两种方案的可实施性,最终我们选择了第一种方案,但是第一种方案在虚拟机环境中经过测试发现偶尔会有宿主机与本机容器不通的现象,建议采用第一种方案的同学尽量不要使用虚拟机环境(怀疑还是网卡混杂设置的问题)。
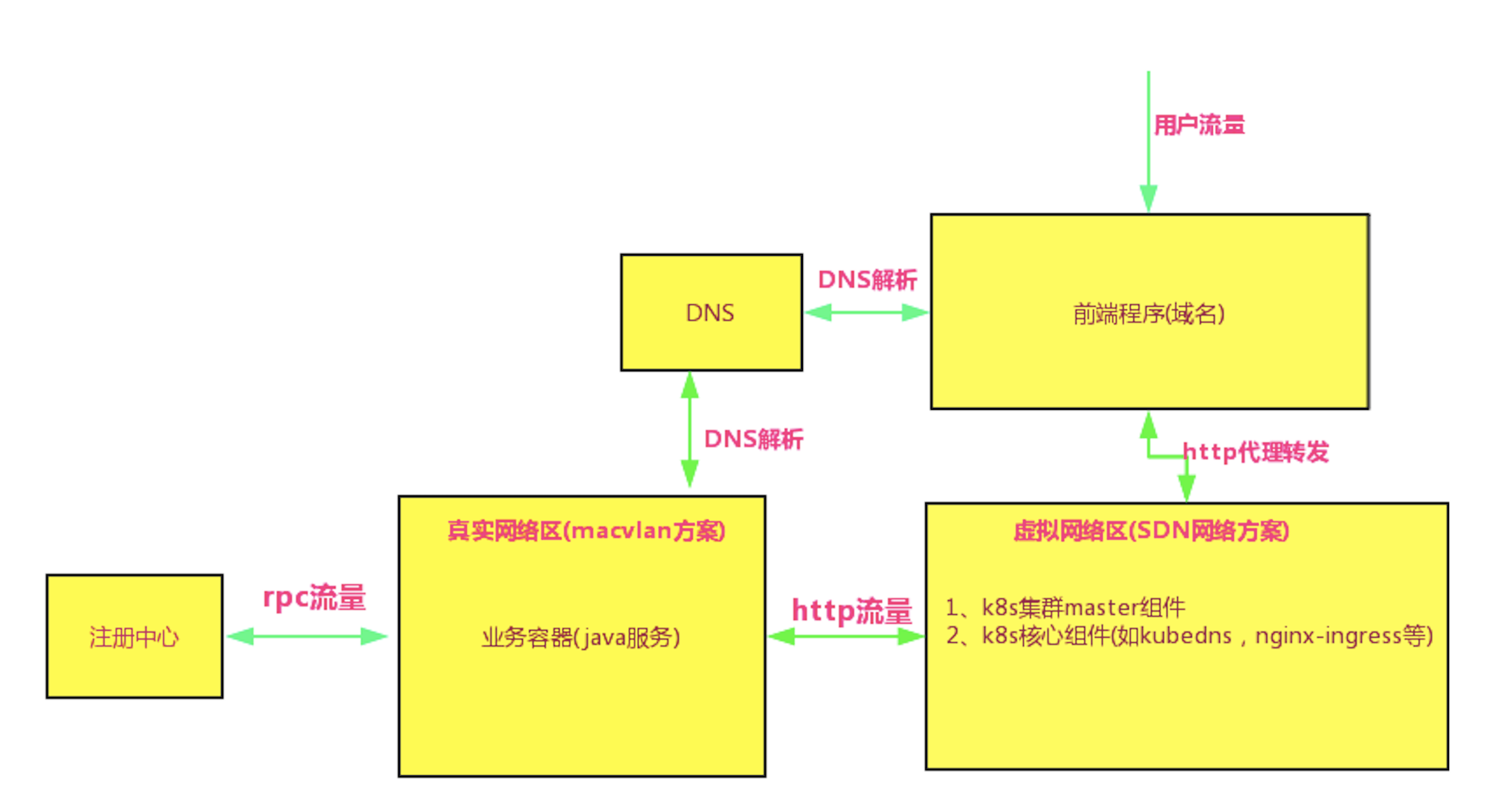
「分区而治」的网络改造
K8S 的核心组件 KubeDNS 在启动时默认会访问 ClusterIP 段的第一个 IP;如果继续使用原有的 Nginx-ingress,那么 Nginx-ingress 的容器在启动时也是使用 ClusterIP 去连接 KubeDNS。而使用 MAC-VLAN 给 KubeDNS 和 Nginx-ingress 分配的都是真实网络 IP,他们是无法联通 ClusterIP 的,所以 KubeDNS 和 Nginx-ingress 容器又不能使用 MAC-VLAN 方案,否则容器服务的域名访问能力将丧失。
综合考虑之下,最终我们采取了「分区而治」的措施,将不同类别的容器调度到不同的区域,使用不同的网络方案,大致的图解如下:
![]()
采用 MAC-VLAN 方案时容器 IP 的分配方案有两种:DHCP 和 host-local。考虑到公司目前没有统一的 DHCP 和 IPAM 服务器为容器分配 IP,开发环境的机器数量不多,我们就采用了人工参与每个节点的网络 IP 段分配。
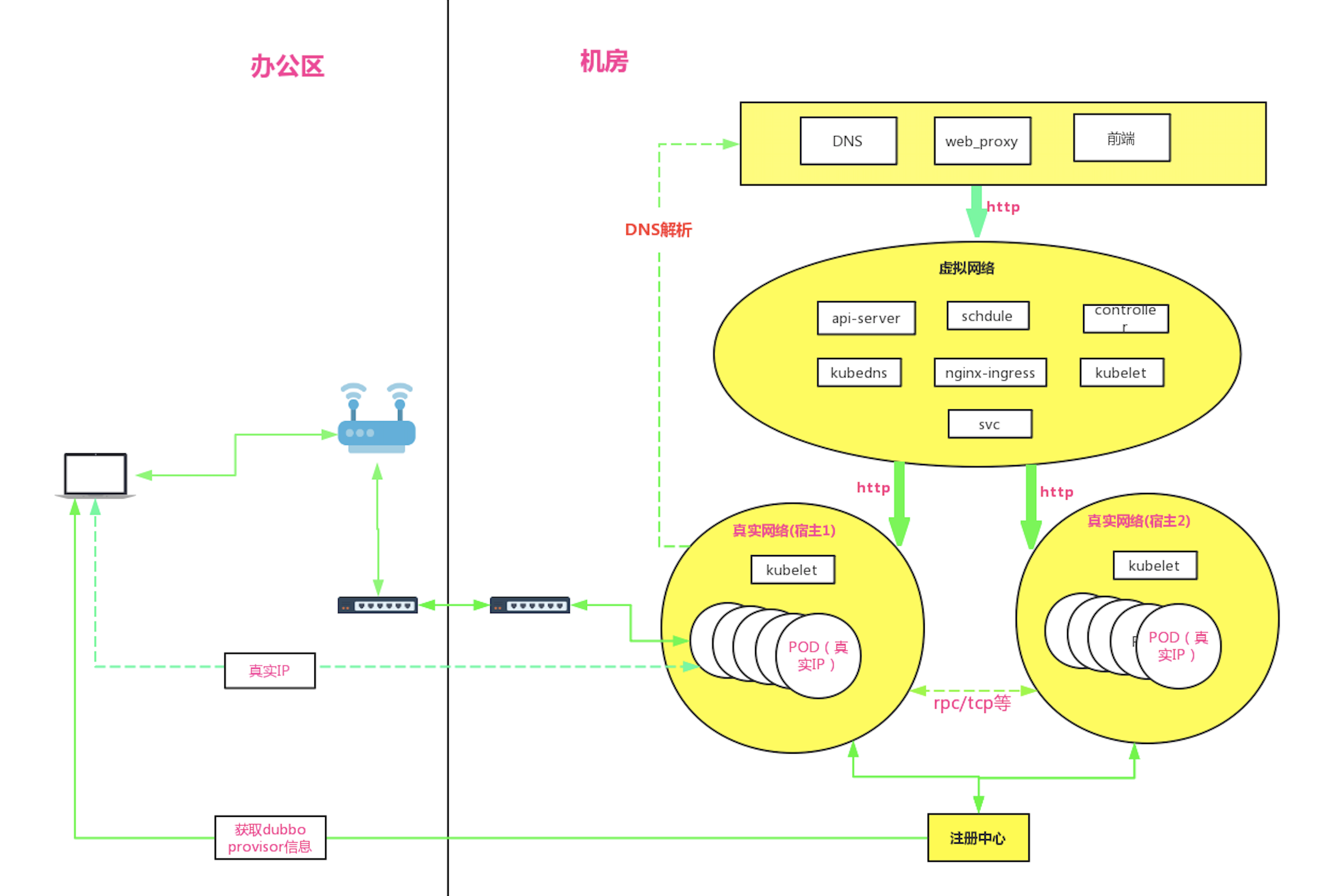
综上,此次改造后的网络架构图大致如下:
![]()
效果
可以看到与第一次网络改造的架构图对比:
-
宿主机 1 和宿主机 2 上已经抛弃了 Kube-proxy 和 Flannel 这些虚拟网络的组件
-
宿主机 1 和宿主机 2 这些业务容器节点直接使用了公司公共 DNS 设施
-
办公区本地 consumer 服务在注册中心拿到 provider 的 IP 后,可以直接连接消费,反之亦可
-
K8S 集群分为了虚拟网络区 (运行 K8S 集群管理组件) 和真实网络区 (运行业务容器)
此次改造的优势和不足总结为:
优点:
缺点:
Part.3 近期优化方向
每一次挑战都是进步的基石。K8S 网络系统自上线以来,极大提高了 Java 业务容器化的运维效率,降低了运维成本,同时提供了更灵活、更稳定的服务运行环境。
在使用和改造 K8S 网络的过程中, 我们也遇到了很多问题,比如服务的优雅上下线、容器 HPA 的设定规则、容器模版的多样化支持等等,近期我们将重点针对以下几方面近一步优化和改进:
1. 生产环境逐步进行网络改造,并实现集群多机房部署,提高容灾能力
2. 对第二次网络改造中的虚拟网络区中的 Nginx-ingress 二次开发,使其支持使用公司公共 DNS,并且废弃 SVC,彻底抛弃虚拟网络的使用
本文作者:张小伍,马蜂窝旅游网交酒平台研发工程师。
![]()