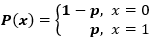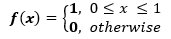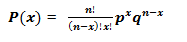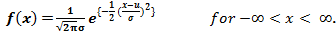介绍
假设你是一所大学的老师。在对一周的作业进行了检查之后,你给所有的学生打了分数。你把这些打了分数的论文交给大学的数据录入人员,并告诉他创建一个包含所有学生成绩的电子表格。但这个人却只存储了成绩,而没有包含对应的学生。
他又犯了另一个错误,在匆忙中跳过了几项,但我们却不知道丢了谁的成绩。我们来看看如何来解决这个问题吧。
一种方法是将成绩可视化,看看是否可以在数据中找到某种趋势。
![]()
上面展示的图形称为数据的频率分布。其中有一个平滑的曲线,但你注意到有一个异常情况了吗?在某个特定的分数范围内,数据的频率异常低。所以,最准确的猜测就是丢失值了,从而导致在分布中出现了凹陷。
这个过程展示了你该如何使用数据分析来尝试解决现实生活中的问题。对于任何一位数据科学家、学生或从业者来说,分布是必须要知道的概念,它为分析和推理统计提供了基础。
虽然概率为我们提供了数学上的计算,而分布却可以帮助我们把内部发生的事情可视化。
在本文中,我将介绍一些重要的概率分布,并会清晰全面地对它们进行解释。
注意:本文假设你已经具有了概率方面的基本知识。如果没有,可以参考这篇有关概率基础的文章。
目录
1、常见的数据类型
2、分布的类型
- 伯努利分布
- 均匀分布
- 二项分布
- 正态分布
- 泊松分布
- 指数分布
3、各个分布之间的关系
一、常见的数据类型
在开始详细讲述分布之前,先来看看我们会遇到哪些种类的数据。数据可以分为离散的和连续的。
- 离散数据:顾名思义,只包含指定的值。例如,当你投骰子的时候,输出结果只可能是1、2、3、4、5或6,而不可能出现1.5或2.45。
- 连续数据:可以在给定的范围内取任何值。范围可以是有限的,也可以是***的。例如,女孩的体重或身高、路程的长度。女孩的体重可以是54千克、54.5千克,或54.5436千克。
现在我们开始学习分布的类型。
2、分布的类型
2.1、伯努利分布
我们首先从最简单的分布伯努利分布开始。
伯努利分布只有两种可能的结果,1(成功)和0(失败)。因此,具有伯努利分布的随机变量X可以取值为1,也就是成功的概率,可以用p来表示,也可以取值为0,即失败的概率,用q或1-p来表示。
概率质量函数由下式给出:px(1-p)1-x, 其中x € (0, 1)。它也可以写成:
![]()
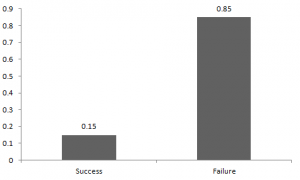
成功与失败的概率不一定相等。这里,成功的概率(p)与失败的概率不同。所以,下图显示了我们之间比赛结果的伯努利分布。
![]()
这里,成功的概率 = 0.15,失败的概率 = 0.85 。如果我打了你,我可能会期待你向我打回来。任何分布的基本预期值是分布的平均值。来自伯努利分布的随机变量X的期望值如为:
E(X) = 1p + 0(1-p) = p
随机变量与二项分布的方差为:
V(X) = E(X²) – [E(X)]² = p – p² = p(1-p)
伯努利分布的例子有很多,比如说明天是否要下雨,如果下雨则表示成功,如果不下雨,则表示失败。
2.2、均匀分布
对于投骰子来说,结果是1到6。得到任何一个结果的概率是相等的,这就是均匀分布的基础。与伯努利分布不同,均匀分布的所有可能结果的n个数也是相等的。
如果变量X是均匀分布的,则密度函数可以表示为:
![]()
均匀分布的曲线是这样的:
![]()
你可以看到,均匀分布曲线的形状是一个矩形,这也是均匀分布又称为矩形分布的原因。其中,a和b是参数。
花店每天销售的花束数量是均匀分布的,最多为40,最少为10。我们来计算一下日销售量在15到30之间的概率。
- 日销售量在15到30之间的概率为(30-15)*(1/(40-10)) = 0.5
- 同样地,日销售量大于20的概率为 = 0.667
遵循均匀分布的X的平均值和方差为:
- 平均值 -> E(X) = (a+b)/2
- 方差 -> V(X) = (b-a)²/12
标准均匀密度的参数 a = 0 和 b = 1,因此标准均匀密度由下式给出:
![]()
2.3、二项分布
让我们来看看玩板球这个例子。假设你今天赢了一场比赛,这表示一个成功的事件。你再比了一场,但你输了。如果你今天赢了一场比赛,但这并不表示你明天肯定会赢。我们来分配一个随机变量X,用于表示赢得的次数。 X可能的值是多少呢?它可以是任意值,这取决于你掷硬币的次数。
只有两种可能的结果,成功和失败。因此,成功的概率 = 0.5,失败的概率可以很容易地计算得到:q = p – 1 = 0.5。
二项式分布就是只有两个可能结果的分布,比如成功或失败、得到或者丢失、赢或败,每一次尝试成功和失败的概率相等。
结果有可能不一定相等。如果在实验中成功的概率为0.2,则失败的概率可以很容易地计算得到 q = 1 - 0.2 = 0.8。
每一次尝试都是独立的,因为前一次投掷的结果不能决定或影响当前投掷的结果。只有两个可能的结果并且重复n次的实验叫做二项式。二项分布的参数是n和p,其中n是试验的总数,p是每次试验成功的概率。
在上述说明的基础上,二项式分布的属性包括:
- 每个试验都是独立的。
- 在试验中只有两个可能的结果:成功或失败。
- 总共进行了n次相同的试验。
- 所有试验成功和失败的概率是相同的。 (试验是一样的)
二项分布的数学表示由下式给出:
![]()
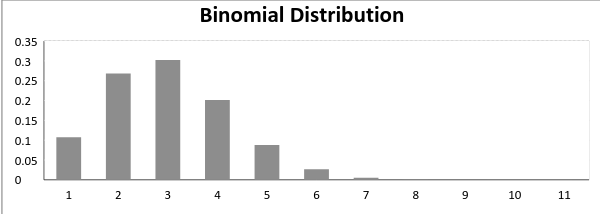
成功概率不等于失败概率的二项分布图:
![]()
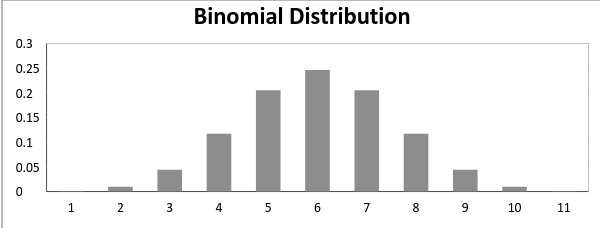
现在,当成功的概率 = 失败的概率时,二项分布图如下
![]()
二项分布的均值和方差由下式给出:
- 平均值 -> µ = n*p
- 方差 -> Var(X) = npq
2.4、正态分布
正态分布代表了宇宙中大多数情况的运转状态。大量的随机变量被证明是正态分布的。任何一个分布只要具有以下特征,则可以称为正态分布:
- 分布的平均值、中位数和模式一致。
- 分布曲线是钟形的,关于线 x = μ 对称。
- 曲线下的总面积为1。
- 有一半的值在中心的左边,另一半在右边。
- 正态分布与二项分布有着很大的不同。然而,如果试验次数接近于无穷大,则它们的形状会变得十分相似。
遵循正态分布的随机变量X的值由下式给出:
![]()
正态分布的随机变量X的均值和方差由下式给出:
- 均值 -> E(X) = µ
- 方差 -> Var(X) = σ^2
其中,μ(平均)和σ(标准偏差)是参数。
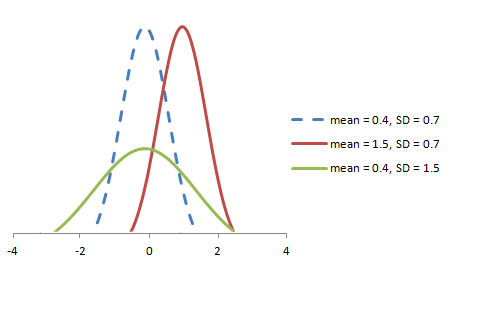
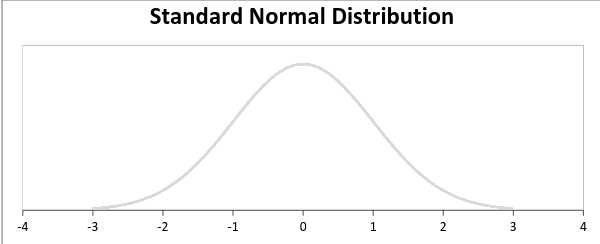
随机变量X〜N(μ,σ)的图如下所示。
![]()
标准正态分布定义为平均值等于0,标准偏差等于1的分布:
![]()
![]()
2.5、泊松分布
假设你在一个呼叫中心工作,一天里你大概会接到多少个电话?它可以是任何一个数字。现在,呼叫中心一天的呼叫总数可以用泊松分布来建模。这里有一些例子:
- 医院在一天内录制的紧急电话的数量。
- 某个地区在一天内报告的失窃的数量。
- 在一小时内抵达沙龙的客户人数。
- 在特定城市上报的自杀人数。
- 书中每一页打印错误的数量。
- 泊松分布适用于在随机时间和空间上发生事件的情况,其中,我们只关注事件发生的次数。
当以下假设有效时,则称为泊松分布:
- 任何一个成功的事件都不应该影响另一个成功的事件。
- 在短时间内成功的概率必须等于在更长的间内成功的概率。
- 时间间隔变小时,在给间隔时间内成功的概率趋向于零。
泊松分布中使用了这些符号:
- λ是事件发生的速率
- t是时间间隔的长
- X是该时间间隔内的事件数。
- 其中,X称为泊松随机变量,X的概率分布称为泊松分布。
- 令μ表示长度为t的间隔中的平均事件数。那么,µ = λ*t。
泊松分布的X由下式给出:
![]()
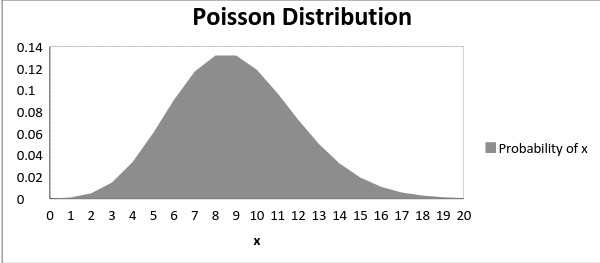
平均值μ是该分布的参数。 μ也定义为该间隔的λ倍长度。泊松分布图如下所示:
![]()
下图显示了随着平均值的增加曲线的偏移情况:
![]()
可以看出,随着平均值的增加,曲线向右移动。
泊松分布中X的均值和方差:
- 均值 -> E(X) = µ
- 方差 -> Var(X) = µ
2.6、指数分布
让我们再一次看看呼叫中心的那个例子。不同呼叫之间的时间间隔是多少呢?在这里,指数分布模拟了呼叫之间的时间间隔。
其他类似的例子有:
指数分布广泛用于生存分析。从机器的预期寿命到人类的预期寿命,指数分布都能成功地提供结果。
具有的指数分布的随机变量X:
- f(x) = { λe-λx, x ≥ 0
- 参数 λ>0 也称为速率。
对于生存分析,λ被称为任何时刻t的设备的故障率,假定它已经存活到t时刻。
遵循指数分布的随机变量X的均值和方差为:
- 平均值 -> E(X) = 1/λ
- 方差 -> Var(X) = (1/λ)²
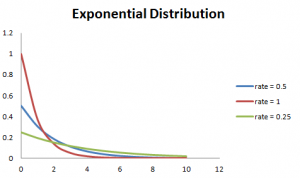
此外,速率越大,曲线下降越快,速率越慢,曲线越平坦。下面的图很好地解释了这一点。
![]()
为了简化计算,下面给出一些公式。
- P{X≤x} = 1 – e-λx 对应于x左侧曲线下的面积。
- PP{X>x} = e-λx 对应于x右侧曲线下的面积。
- P{x1-λx1 – e-λx2, corresponds to the area under the density curve between x1 and x2.
- P{x1-λx1 – e-λx2 对应于x1和x2之间地曲线下的面积。
3、各种分布之间的关系
伯努利与二项分布之间的关系
- 伯努利分布是具有单项试验的二项式分布的特殊情况。
- 伯努利分布和二项式分布只有两种可能的结果,即成功与失败。
- 伯努利分布和二项式分布都具有独立的轨迹。
泊松与二项式分布之间的关系
泊松分布在满足以下条件的情况下是二项式分布的极限情况:
- 试验次数***大或n → ∞。
- 每个试验成功的概率是相同的,***小的,或p → 0。
- np = λ,是有限的。
正态分布与二项式分布之间的关系,以及正态分布与泊松分布之间的关系
正态分布是在满足以下条件的情况下二项分布的另一种限制形式:
- 试验次数***大,n → ∞。
- p和q都不是***小。
正态分布也是参数λ → ∞的泊松分布的极限情况。
指数和泊松分布之间的关系
如果随机事件之间的时间遵循速率为λ的指数分布,则时间长度t内的事件总数遵循具有参数λt的泊松分布。
结束语
概率分布在许多领域都很常见,包括保险、物理、工程、计算机科学甚至社会科学,如心理学和医学。它易于应用,并应用很广泛。本文重点介绍了日常生活中经常能遇到的六个重要分布,并解释了它们的应用。现在,你已经能够识别、关联和区分这些分布了。