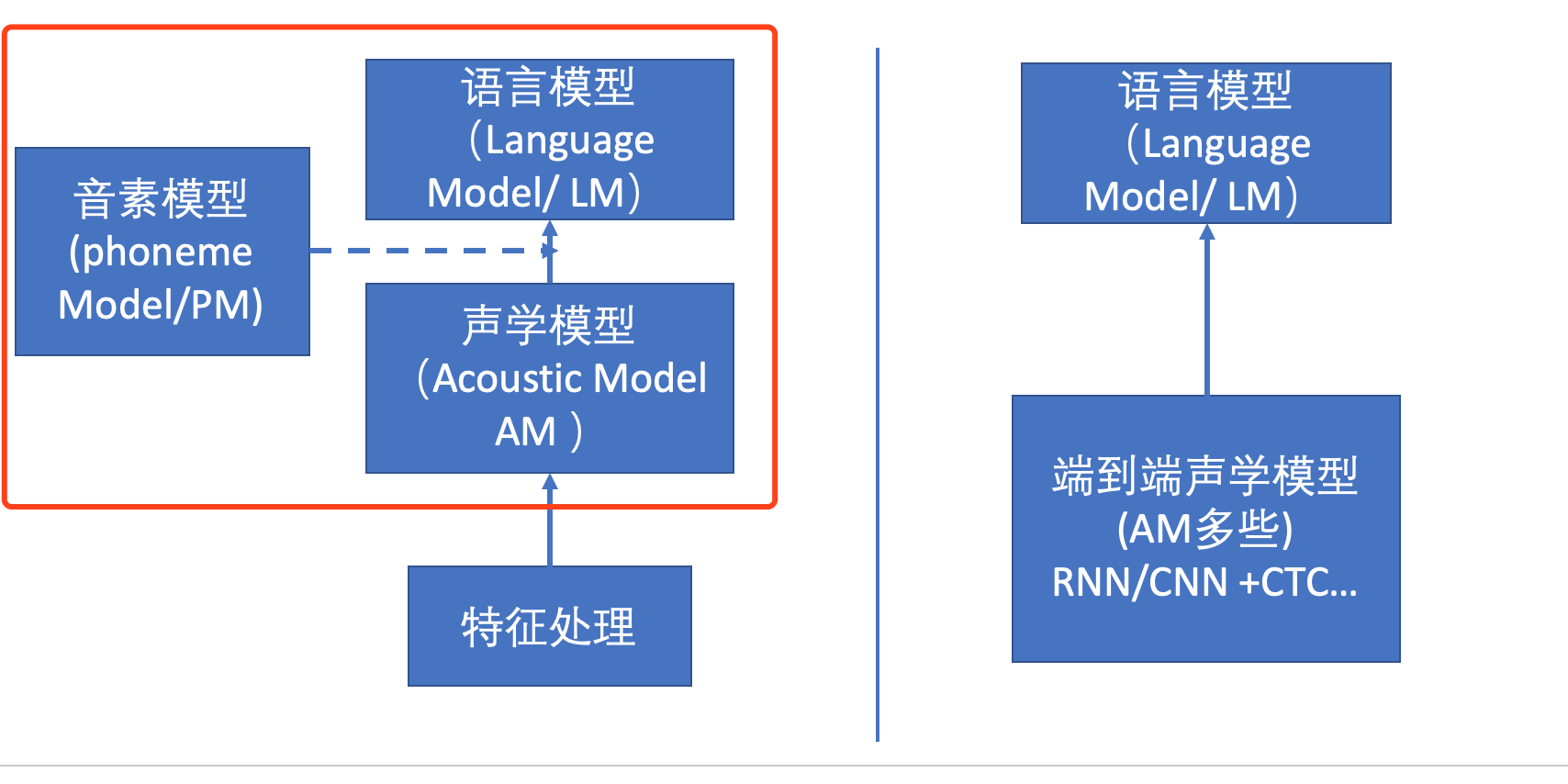
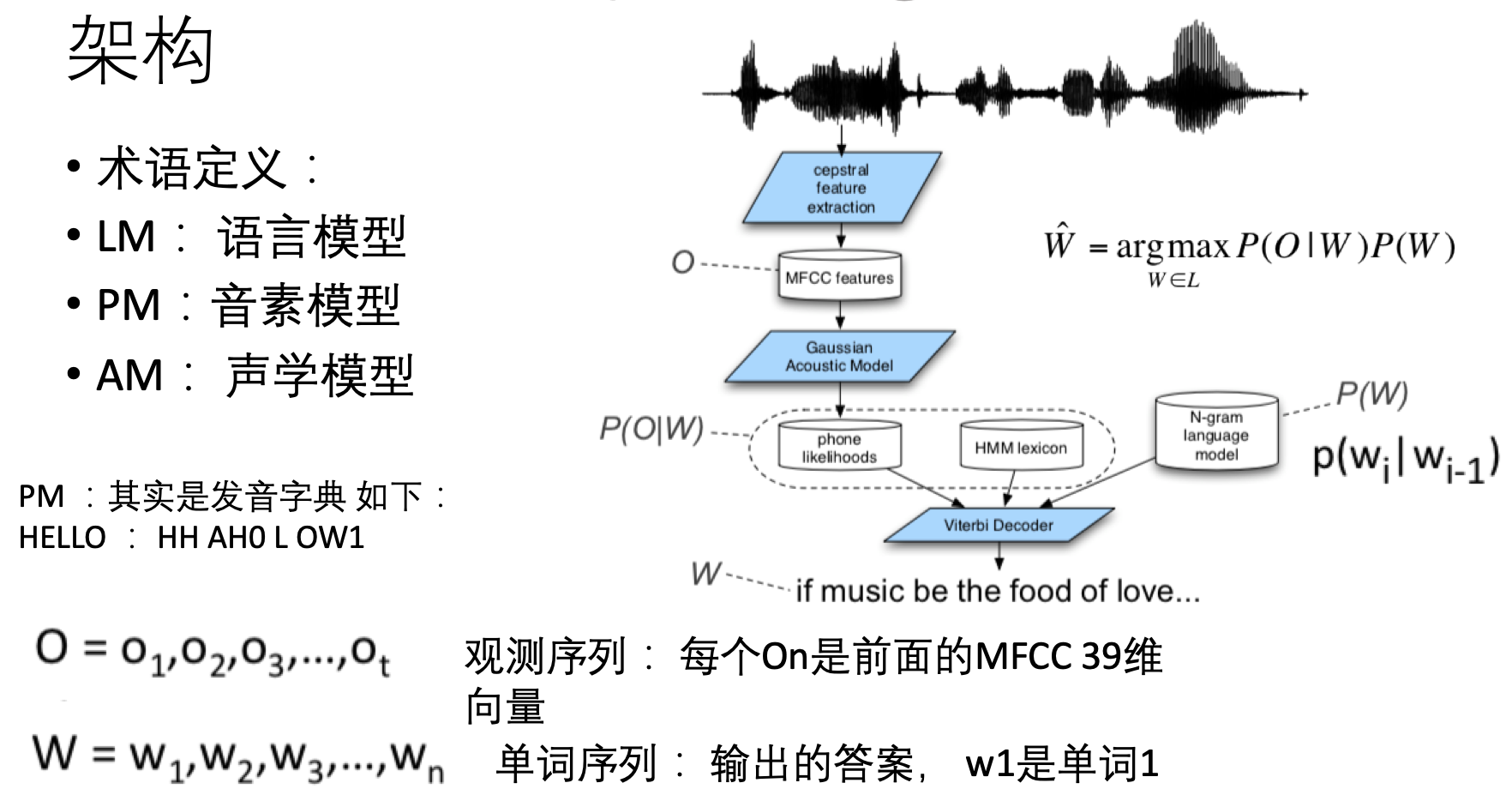

语音识别(ASR)基础介绍第四篇——当今流行做法与CTC
本篇开始,就进入到了asr当前的流行做法。 这里单独提到了CTC算法。 这个算法对当前asr使用deep learning的方法有重大影响。 总体感觉,写到本篇,工作量反而变得很小。因为进入deep learning时代后,神经网络模型基本都是那么几种,已经不再需要挨个详细介绍。而且看图就能理解的很明白。 所以本篇后半部分基本就是贴图了。。:D 一、CTC 在CTC之前,训练语料要配合上一篇中提到的方法,需要人工把音频中每个时间段对应的是哪个音素的信息标注清楚。 这个工作量和对人及金钱的需求是巨大的。基本都是百万级别手笔。 有个CTC之后, 给定一个音频,就只要告诉这个音频说的是什么文本就好了。 省掉了对齐的那一步。 由此,其重要性可自行判断。 关于CTC,感觉与其这里坑坑洼洼的介绍,不如直接参考这篇知乎的文章——https://z