Java并发编程实战系列8之线程池的使用
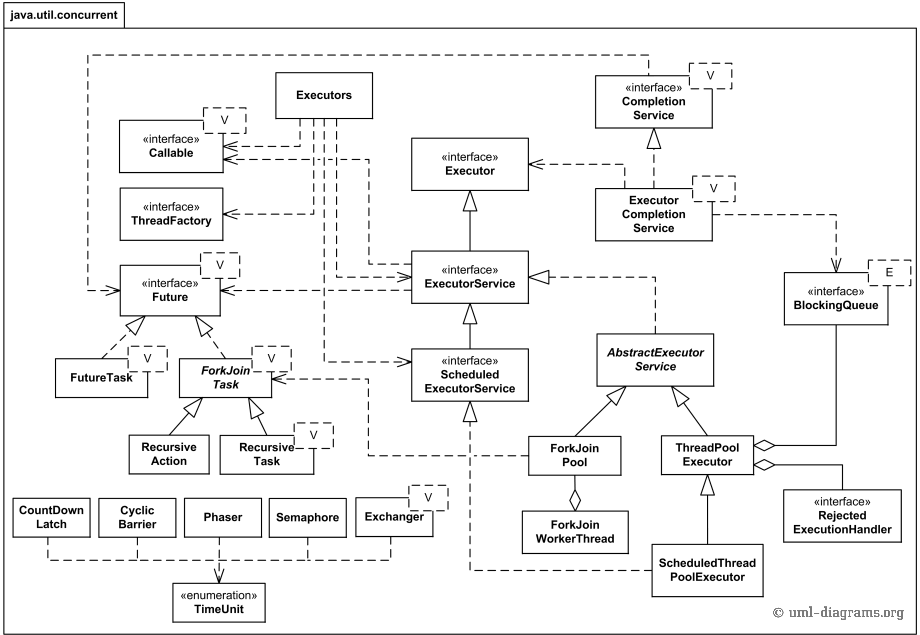
ThreadPoolExecutor UML图: image image 8.1 在任务和执行策略之间隐形耦合 避免Thread starvation deadlock 8.2 设置线程池大小 8.3 配置ThreadPoolExecutor image 构造函数如下: public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) { ... } 核心和最大池大小:如果运行的线程少于 corePoolSize,则创建新线程来处理请求(即一个Runnable实例),即使其它线程是空闲的。如果运行的线程多于 corePoolSize 而少于 maximumPoolSize,则仅当队列满时才创建新线程。 保持活动时间:如果池中当前有多于 corePoolSize 的线程,则这些多出的线程在空闲时间超过 keepAliveTime 时将会终止。 排队:如果运行的线程等于或多于 corePoolSize,则 Executor 始终首选将请求加入队列BlockingQueue,而不添加新的线程。 被拒绝的任务:当 Executor 已经关闭,或者队列已满且线程数量达到maximumPoolSize时(即线程池饱和了),请求将被拒绝。这些拒绝的策略叫做Saturation Policy,即饱和策略。包括AbortPolicy, CallerRunsPolicy, DiscardPolicy, and DiscardOldestPolicy. 另外注意: 如果运行的线程少于 corePoolSize,ThreadPoolExecutor 会始终首选创建新的线程来处理请求;注意,这时即使有空闲线程也不会重复使用(这和数据库连接池有很大差别)。 如果运行的线程等于或多于 corePoolSize,则 ThreadPoolExecutor 会将请求加入队列BlockingQueue,而不添加新的线程(这和数据库连接池也不一样)。 如果无法将请求加入队列(比如队列已满),则创建新的线程来处理请求;但是如果创建的线程数超出 maximumPoolSize,在这种情况下,请求将被拒绝。 newCachedThreadPool使用了SynchronousQueue,并且是无界的。 线程工厂ThreadFactory 8.4 扩展ThreadPoolExecutor 重写beforeExecute和afterExecute方法。 8.5 递归算法的并行化 实际就是类似Number of Islands或者N-Queens等DFS问题的一种并行处理。 串行版本如下: public class SequentialPuzzleSolver <P, M> { private final Puzzle<P, M> puzzle; private final Set<P> seen = new HashSet<P>(); public SequentialPuzzleSolver(Puzzle<P, M> puzzle) { this.puzzle = puzzle; } public List<M> solve() { P pos = puzzle.initialPosition(); return search(new PuzzleNode<P, M>(pos, null, null)); } private List<M> search(PuzzleNode<P, M> node) { if (!seen.contains(node.pos)) { seen.add(node.pos); if (puzzle.isGoal(node.pos)) return node.asMoveList(); for (M move : puzzle.legalMoves(node.pos)) { P pos = puzzle.move(node.pos, move); PuzzleNode<P, M> child = new PuzzleNode<P, M>(pos, move, node); List<M> result = search(child); if (result != null) return result; } } return null; } } 并行版本如下: public class ConcurrentPuzzleSolver <P, M> { private final Puzzle<P, M> puzzle; private final ExecutorService exec; private final ConcurrentMap<P, Boolean> seen; protected final ValueLatch<PuzzleNode<P, M>> solution = new ValueLatch<PuzzleNode<P, M>>(); public ConcurrentPuzzleSolver(Puzzle<P, M> puzzle) { this.puzzle = puzzle; this.exec = initThreadPool(); this.seen = new ConcurrentHashMap<P, Boolean>(); if (exec instanceof ThreadPoolExecutor) { ThreadPoolExecutor tpe = (ThreadPoolExecutor) exec; tpe.setRejectedExecutionHandler(new ThreadPoolExecutor.DiscardPolicy()); } } private ExecutorService initThreadPool() { return Executors.newCachedThreadPool(); } public List<M> solve() throws InterruptedException { try { P p = puzzle.initialPosition(); exec.execute(newTask(p, null, null)); // block until solution found PuzzleNode<P, M> solnPuzzleNode = solution.getValue(); return (solnPuzzleNode == null) ? null : solnPuzzleNode.asMoveList(); } finally { exec.shutdown(); } } protected Runnable newTask(P p, M m, PuzzleNode<P, M> n) { return new SolverTask(p, m, n); } protected class SolverTask extends PuzzleNode<P, M> implements Runnable { SolverTask(P pos, M move, PuzzleNode<P, M> prev) { super(pos, move, prev); } public void run() { if (solution.isSet() || seen.putIfAbsent(pos, true) != null) return; // already solved or seen this position if (puzzle.isGoal(pos)) solution.setValue(this); else for (M m : puzzle.legalMoves(pos)) exec.execute(newTask(puzzle.move(pos, m), m, this)); } } }