MySQL 使用入门 (全)
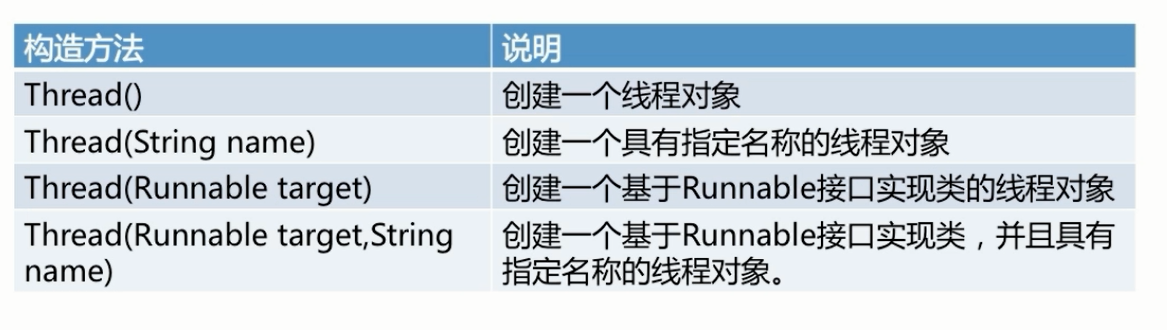
数据库简介 1.数据库概述 ①数据库:是按照某种数据结构对数据进行组织,存储和管理的容器,简单的说就是用来存储和管理数据的容器 ②数据库系统:是指在计算机中引入数据库后的系统,一般由数据库,数据库管理系统,应用程序和数据库管理员组成 ③数据库管理系统:是一个管理,控制数据库容器中各种数据库对象的系统软件 2.结构化查询语言SQL ①结构化查询语言:是一种用来与数据库通信的语言,其利用一些简单的句子构成基本的语法来存取数据库的内容,便于用户从数据库中获得和操作所需数据 ②SQL语言特点:非过程化语言,统一的语言,关系数据库的公共语言 ③SQL语言的组成:数据库定义语言(DDL),数据库操纵语言(DML),数据控制语言(DCL) 3.数据库设计基本步骤 ①需求分析阶段 ②概念结构设计阶段 ③逻辑结构设计阶段 ④数据库的物理结构设计阶段 ⑤数据库的实施阶段 ⑥数据库运行与维护阶段 4.MySQL数据库 它是一种关系型数据库管理系统,关系型数据库将数据保存在不同的表中,而不是将所有数据存放在一个大仓库,提高了速度和灵活性 特点: 体积小,运行速度快,成本低,开放源码 单进程,多线程架构,属于轻量级的数据库 5.MySQL体系结构 包括连接池组件,管理服务和工具组件,SQL接口组件,查询分析组件,优化器组件,缓存组件,插件式存储引擎以及物理组件 6.数据库系统解决的问题:持久化存储,优化读写,保证数据的有效性 7.数据库的分类 ①文档型,如sqlite,就是一个文件,通过对文件的复制完成数据库的复制 ②服务型,如mysql、postgresql,数据存储在一个物理文件中,但是需要使用终端以tcp/ip协议连接,进行数据库的读写操作 8.数据库的操作 ①数据库的操作,包括创建、删除 ②表的操作,包括创建、修改、删除 ③数据的操作,包括增加、修改、删除、查询,简称crud 10.常用的可视化操作工具:MySQL-Front,MySQL Workbench及Navicat for MySQL 11. SQL的基本书写规则 ①关键字大写 ②表名的首字大写 ③其余(列名)小写 E-R模型 1.E表示entry,实体;R表示relationship,关系当前物理的数据库都是按照E-R模型进行设计的 2.关系描述两个实体之间的对应规则,包括: ①一对一 ②一对多 ③多对多 3.三范式 ①第一范式(1NF):列不可拆分 ②第二范式(2NF):唯一标识 ③第三范式(3NF):引用主键 说明:后一个范式,都是在前一个范式的基础上建立的 4.数据完整性 一个数据库就是一个完整的业务单元,可以包含多张表,数据被存储在表中,在表中为了更加准确的存储数据,保证数据的正确有效,可以在创建表的时候,为表添加一些强制性的验证,包括数据字段的类型、约束 5.字段类型 ①数字:int,decimal:如decimal(5,2),表示数字长度不超过5位,小数不超过2位 ②字符串:char,varchar,text:其中char和varchar都是有限字符的,而text是不确定的。char和varchar都是8个字符,但char如果不够会补充空格,varchar是不会补充空格的 ③日期:datetime ④布尔:bit 6.约束 ①主键primary key ②非空not null ③惟一unique ④默认default ⑤外键foreign key ⑥auto_increment表示自动增长 7. 数据库的选型 ①开发人员的熟练程度,费用,数据规模,性能要求,集群能力等,也可参考数据库管理员的建议 ②对于有1:1关系的两个表,为两个表设置相同的主键列 ③对于有1:N关系的两个表,在N表中添加一个外键列,该列与1表的主键列向关联 ④对于M:N关系,生成一个单独的表表示该关系,该关系的列由两个表的主键组成 命令脚本命令 1.远程连接 一般在公司开发中,可能会将数据库统一搭建在一台服务器上,所有开发人员共用一个数据库,而不是在自己的电脑中配置一个数据库 运行命令: mysql-hip地址-uroot-p -h后面写要连接的主机ip地址 -u后面写连接的用户名 -p回车后写密码 2.数据库操作 ①创建数据库 createdatabase数据库名charset=utf8; ②删除数据库 dropdatabase数据库名; ③切换数据库 use数据库名; ④查看当前选择的数据库 selectdatabase(); 3.表操作 ①查看当前数据库中所有表 showtables; ②创建表 createtable表名(列及类型); ③修改表 增,改,删:altertable表名add|change|drop列名类型; 增加约束条件:altertable表名addconstraint约束名,类型(字段名); 删除约束条件:altertable表名dropprimarykey; 添加外键约束:altertable表名add约束名constraintforeignkey(字段名)references父表名(字段名); 修改存储引擎:altertable表名engine=新的存储引擎;(MyISAM,InooDB) 修改默认字符集:altertable表名defaultcharset=新的字符集; ④删除表 droptable表名; ⑤查看表结构 desc表名; ⑥更改表名称 renametable原表名to新表名; ⑦查看表的创建语句 showcreatetable表名; 4.数据操作 ①查询 selectdistinct列名fromstudents;消除重复 select*from表名where条件; ②增加 全列插入:insertinto表名values(...) 缺省插入:insertinto表名(列1,...)values(值1,...) 同时插入多条数据:insertinto表名values(...),(...)...; 或insertinto表名(列1,...)values(值1,...),(值1,...)...; 主键列是自动增长,但是在全列插入时需要占位,通常使用0,插入成功后以实际数据为准 ③修改 update表名set列1=值1,...where条件 ④删除 deletefrom表名where条件 ⑤逻辑删除,本质就是修改操作update altertablestudentsaddisdeletebitdefault0; ⑥如果需要删除则 updatestudentsisdelete=1where...; 5.备份与恢复 数据备份 ①进入超级管理员 sudo-s ②进入mysql库目录 cd/var/lib/mysql ③运行mysqldump命令 mysqldump–uroot–p数据库名>~/Desktop/备份文件.sql; ④按提示输入mysql的密码 数据恢复 ①连接mysql,创建数据库 ②退出连接,执行如下命令 mysql-uroot–p数据库名<~/Desktop/备份文件.sql ③根据提示输入mysql密码 查询(条件) 1.比较运算符 select*fromstudentswhereid>3; 2.逻辑运算符 select*fromstudentswhereid>3andgender=0; 3.模糊查询 Like:select*fromstudentswheresnamelike'黄_'; ①%表示任意多个任意字符 ②_表示一个任意字符 4.范围查询 ①in表示在一个非连续的范围内 select*fromstudentswhereidin(1,3,8); ②between ... and ...表示在一个连续的范围内 select*fromstudentswhereidbetween3and8; 5.空判断 ①判空is null select*fromstudentswherehometownisnull; ②判非空is not null select*fromstudentswherehometownisnull; 6.优先级 ①小括号,not,比较运算符,逻辑运算符 ②and比or先运算,如果同时出现并希望先算or,需要结合()使用 查询(聚合) 1.count(*)表示计算总行数,括号中写星与列名,结果是相同的 selectcount(*)fromstudents; 2.max(列)表示求此列的最大值 selectmax(id)fromstudentswheregender=0; 3.min(列)表示求此列的最小值 selectmin(id)fromstudentswhereisdelete=0; 4.sum(列)表示求此列的和 selectsum(id)fromstudentswheregender=1; 5.avg(列)表示求此列的平均值 selectavg(id)fromstudentswhereisdelete=0andgender=0; 查询(分组) 1.语法: select列1,列2,聚合...from表名groupby列1,列2,列3... 分组后的数据筛选 2.语法: select列1,列2,聚合...from表名 groupby列1,列2,列3... having列1,...聚合... having后面的条件运算符与where的相同,不同的是having对分组的结果集进行筛选,where对原始集筛选 3.与聚合函数和Group by子句有关的常见错误 在select子句中书写了多余的列 selectproduct_id,purchase_price,count(*)fromProductGroupbypurchase_price; 在Group by子句中写了列的别名 selectproduct_typeaspt,count(*)FromProductGroupbypt; ①Group by的子句是随机的,不能人为排序 ②不能在where子句中使用聚合函数 ③只有select子句和having子句以及(order by)中才能够使用count等聚合函数 查询(排序) 语法: select*from表名 orderby列1asc|desc,列2asc|desc,... 将行数据按照列1进行排序,如果某些行列1的值相同时,则按照列2排序,以此类推默认按照列值从小到大排列,asc从小到大排列,即升序,desc从大到小排序,即降序查询(分页) 语法: select*from表名 limitstart,count 查询(总结) 1.完整的select语句 selectdistinct* from表名 where.... groupby...having... orderby... limitstar,count From字句是否真的有必要? 并不是,只使用select子句也是可以的,如select(100+300)*3 as calculation,但在oracle中不允许 2.子查询 ①子查询就是一次性视图.与视图不同,子查询在select语句执行完毕之后就会消失 ②标量子查询:标量就是单一的意思,标量子查询有一个特殊的限制,必须而且只能返回1行1列的结果 ③关联子查询:在子查询中添加where子句条件,where p1.product_type=p2.product_type 关系 1.外键 为stuid添加外键约束 altertablescoresaddconstraintstu_scoforeignkey(stuid)referencesstudents(id); 2.外键的级联操作 ①在删除students表的数据时,如果这个id值在scores中已经存在,则会抛异常 ②推荐使用逻辑删除,还可以解决这个问题 ③可以创建表时指定级联操作,也可以在创建表后再修改外键的级联操作 语法: altertablescoresaddconstraintstu_scoforeignkey(stuid)referencesstudents(id)ondeletecascade; 级联操作的类型包括: ①restrict(限制):默认值,抛异常 ②cascade(级联):如果主表的记录删掉,则从表中相关联的记录都将被删除 ③set null:将外键设置为空 ④no action:什么都不做 连接查询 1.连接查询分类 ①表A inner join 表B:表A与表B匹配的行会出现在结果中 ②表A left join 表B:表A与表B匹配的行会出现在结果中,外加表A中独有的数据,未对应的数据使用null填充 ③表A right join 表B:表A与表B匹配的行会出现在结果中,外加表B中独有的数据,未对应的数据使用null填充 ④查询学生的姓名、平均分 selectstudents.sname,avg(scores.score) fromscores innerjoinstudentsonscores.stuid=students.id groupbystudents.sname; 2.自关联 创建areas表的语句如下: createtableareas( idintprimarykey, atitlevarchar(20), pidint, foreignkey(pid)referencesareas(id) ); 视图 1.视图:从SQL的角度来看,视图和表是相同的两者的区别在于表中保存的是实际数据,而视图中保存的是select语句(视图本身并不存储数据) 定义视图: createviewstuscoreas selectstudents.*,scores.scorefromscores innerjoinstudentsonscores.stuid=students.id; 2.视图的用途就是查询 select*fromstuscore; 3.视图的优点: 视图无需保存数据,因此可以节省存储设备的容量 可以将频繁使用的select语句保存成视图,这样就不用每次都重写了 4.视图的限制: ①定义视图时不能使用order by子句,这是因为视图和表一样数据行都是没有顺序的 ②对视图进行更新(未被汇总得到的视图) ③条件: select子句未使用Dintinct From子句中只有一张表 未使用group by子句 未使用having子句 ④删除视图(多重视图) dropview视图名cascade 事务 1.事务:是恢复和并发控制的基本单位,什么是事务,就是需要在一个处理单元中执行的一系列更新处理的集合,通过使用事务,可以对数据库中的数据更新处理提交和取消进行<beigin,commit,rollback>视图本质就是对查询的一个封装 2.使用事务的请况:当数据被更改时,包括insert,update,delete,使用事务可以完成退回的功能,保证业务逻辑的正确性 3.事务四大特性(简称ACID) ①原子性(Atomicity):事务中的全部操作在数据库中是不可分割的,要么全部完成,要么均不执行 ②一致性(Consistency):几个并行执行的事务,其执行结果必须与按某一顺序串行执行的结果相一致 ③隔离性(Isolation):事务的执行不受其他事务的干扰,事务执行的中间结果对其他事务必须是透明 ④持久性(Durability):对于任意已提交事务,系统必须保证该事务对数据库的改变不被丢失,即使数据库出现故障 ⑤要求:表的类型必须是innodb或bdb类型,才可以对此表使用事务 ⑥事务语句: begin;//开启 commit;//提交 rollback;//回滚 索引 1.单列索引和组合索引 ①单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引 ②组合索引,即一个索包含多个列 2.操作 ①查看索引: showindexfromtable_name; ②创建索引: createindexindexNameonmytable(usrname(length)); ③删除索引: dropindex[indexName]onmytable; 3.缺点 ①虽然索引提高了查询速度,同时却会降低更新表的速度,如对表进行insert,update和delete。 ②因为更新表时,mysql不仅要保存数据,还要保存一下索引文件 ③建立索引会占用磁盘空间的索引文件 4.检测运行时间 ①开启运行时间检测: setprofiling=1; ②执行查询语句: ③查看执行的时间: showprofiles; 谓词 1.就是返回值为真值的函数 like,in,not in,between,is null,is not null 函数 1.根据用途大致分为以下 ①算术函数(用来进行数值计算的函数) ②字符串函数(用来进行字符串操作的函数) ③日期函数(用来进行日期操作的函数) ④转换函数(用来转换数值类型和值的函数) ⑤聚合函数(用来进行数据聚合的函数) 2.case表达式 case表达式分为简单case表达式和搜索case表达式两种 搜索case表达式包含简单case表达式的全部功能 case搜索表达式; casewhen<求值表达式>then<表达式> when<求值表达式>then<表达式> .... else<表达式> end case简单表达式: case<表达式> when<表达式>then<表达式> when<表达式>then<表达式> when<表达式>then<表达式> ..... else<表达式> end 集合运算 1.集合运算:集合在数据库领域表示记录的集合,具体来说表,视图和查询执行的结果都是记录的集合 2.集合运算注意事项 ①作为运算对象的记录的列数必须相同 ②作为运算对象的记录中列的类型必须一致 ③可以使用任何select语句,但order by子句只能在最后使用一次 3.表的加法-union并集 selectproduct-id,product_namefromProductunion(all)selectproduct_id,product_namefromproduct2; 4.选取表中的公共部分-intersect交集 selectproduct_id,product_namefromProductintersectselectproduct_id,product_namefromProduct2orderbyproduct_id; 5.记录的减法-except差集 selectproduct_id,product_namefromProductexceptselectproduct_id,product_namefromProduct2orderbyproduct_id; 6.表的联结 联结join就是将其他表的列添加过来,进行添加列的集合运算,union是以行(纵向)为单位进行操作,而联结则是以列(横向)为单位进行的 与python交互 1.安装引入模块 ①安装mysql模块 sudoapt-getinstallpython-mysqldb,pymysql ②在文件中引入模块 importMysqldb 2.Connection对象 用于建立与数据库的连接 创建对象:调用connect()方法 conn=connect(参数列表) 参数host:连接的mysql主机,如果本机是'localhost' 参数port:连接的mysql主机的端口,默认是3306 参数db:数据库的名称 参数user:连接的用户名 参数password:连接的密码 参数charset:通信采用的编码方式,默认是'gb2312',要求与数据库创建时指定的编码一致 3.对象的方法 close()关闭连接 commit()事务所以需要提交才会生效 rollback()事务放弃之前的操作 cursor()返回Cursor对象用于执行sql语句并获得结果 4.Cursor对象 执行sql语句 创建对象:调用Connection对象的cursor()方法 cursor1=conn.cursor() 5.对象的方法 close()关闭 execute(operation[,parameters])执行语句,返回受影响的行数 fetchone()执行查询语句时,获取查询结果集的第一个行数据,返回一个元组 next()执行查询语句时,获取当前行的下一行 fetchall()执行查询时,获取结果集的所有行,一行构成一个元组,再将这些元组装入一个元组返回 scroll(value[,mode])将行指针移动到某个位置 mode表示移动的方式 mode的默认值为relative表示基于当前行移动到value,value为正则向下移动,value为负则向上移动 mode的值为absolute表示基于第一条数据的位置,第一条数据的位置为0 6.对象的属性 ①rowcount只读属性,表示最近一次execute()执行后受影响的行数 ②connection获得当前连接对象 7.sql语句参数化 sname=raw_input("请输入学生姓名:") params=[sname] count=cs1.execute('insertintostudents(sname)values(%s)',params)