Ubuntu16.04安装HBASE集群
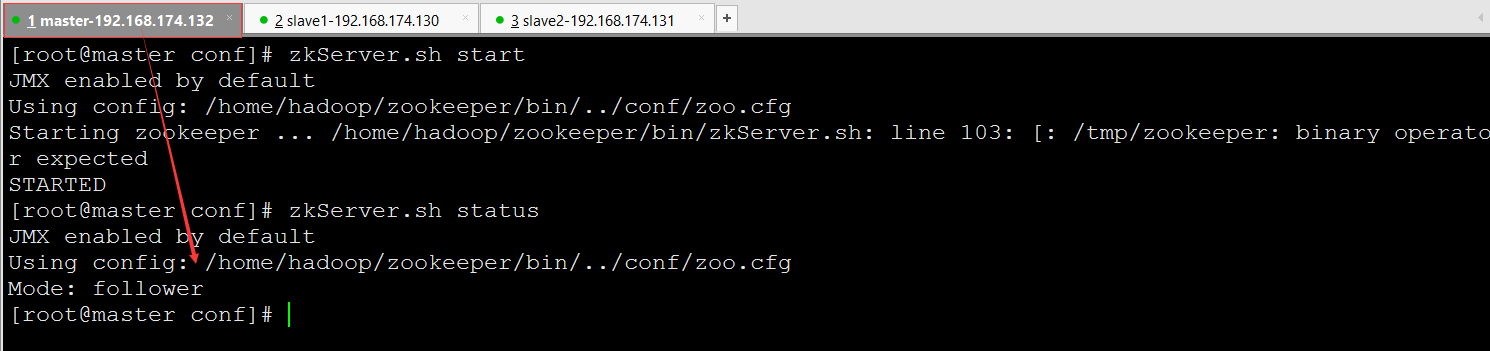
http://mirrors.hust.edu.cn/apache/hbase/ http://mirrors.hust.edu.cn/apache/hbase/1.3.1/hbase-1.3.1-bin.tar.gz root@master:/usr/local/hbase-1.3.1# vim /etc/profile #Hbase_Home export HBASE_HOME=/usr/local/hbase-1.3.1 export PATH=$PATH:$HBASE_HOME/bin root@master:/usr/local/hbase-1.3.1# source /etc/profile root@master:/usr/local/hbase-1.3.1# vim conf/hbase-env.sh export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 root@master:/usr/local/hbase-1.3.1# vim conf/hbase-site.xml <configuration> <property> <name>hbase.rootdir</name> <value>hdfs://master:8020/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>master,slave1,slave2</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/usr/local/hbase-1.3.1/data</value> </property> </configuration> root@master:/usr/local/hbase-1.3.1# vim conf/regionservers slave1 slave2 root@master:/usr/local# scp -r hbase-1.3.1 slave1:/usr/local root@master:/usr/local# scp -r hbase-1.3.1 slave2:/usr/local root@master:/usr/local/hbase-1.3.1# bin/start-hbase.sh root@master:/usr/local/hbase-1.3.1# jps 2738 SecondaryNameNode 3493 QuorumPeerMain 8070 Jps 2951 ResourceManager 2521 NameNode 7866 HMaster 3356 Master root@slave1:/usr/local/hbase-1.3.1# jps 4528 Worker 5778 HRegionServer 4436 Worker 4058 DataNode 5930 Jps 4636 QuorumPeerMain 本文转自 OpenStack2015 博客,原文链接: http://blog.51cto.com/andyliu/1967309 如需转载请自行联系原作者