1.Hadoop
a).配置core-site.xml
hadoop文件core-site.xml中配置信息如下,重启HDFS
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
b).启停HDFS
## 启动HDFS
./hadoop/sbin/start-dfs.sh
## 停止HDFS
./hadoop/sbin/stop-dfs.sh
c).HDFS退出安全模式
./hadoop/bin/hdfs dfsadmin -safemode leave
2.Hive
a).配置hive-site.xml
修改hive-site.xml中thrift相关配置项
## 配置host和port
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hostname</value>
</property>
## 访问权限
<property>
<name>hive.scratch.dir.permission</name>
<value>755</value>
</property>
b).启动
## 启动server2
./hive/bin/hive --service server2
## 启动thrift服务
./hive/bin/hive --service metastore -p 9083
3.Zeppline配置Hive Interpreter
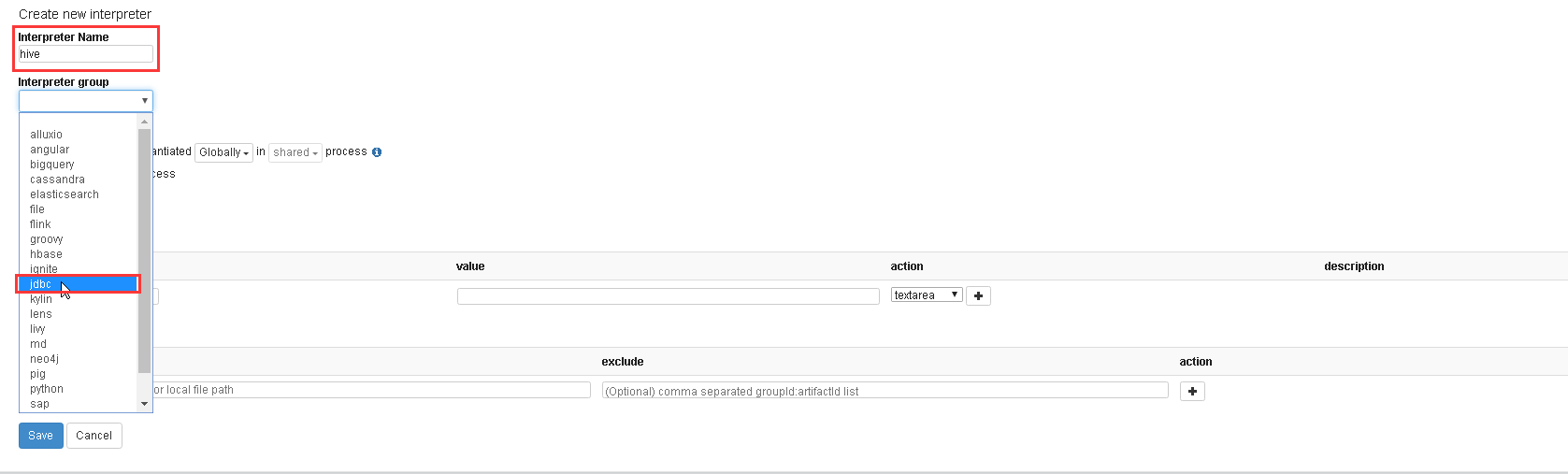
a).创建Hive Interpreter
Interpreter Name: hive
Interpreter Group: jdbc
![]()
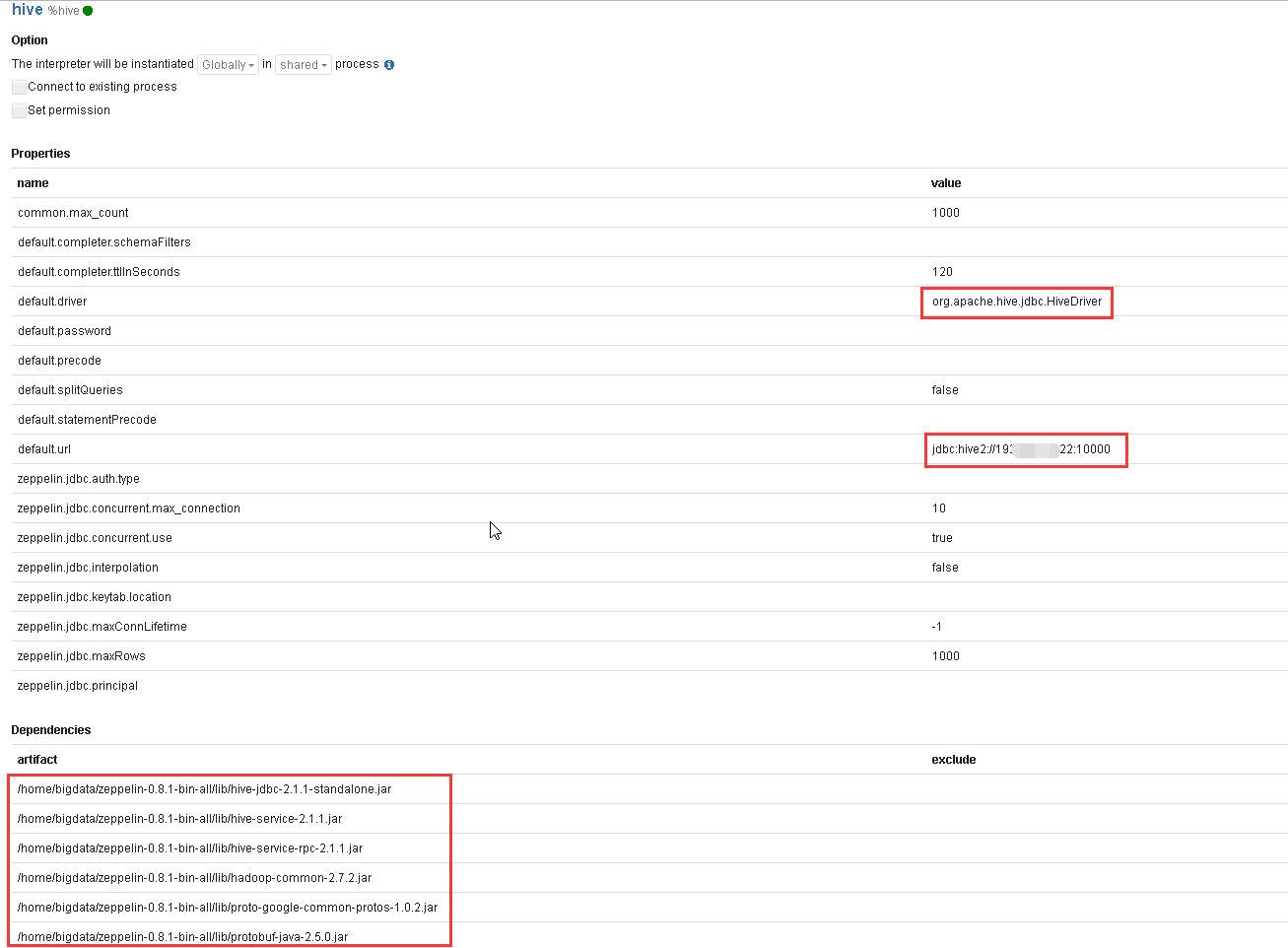
b).配置Hive Interpreter
hive.driver: org.apache.hive.jdbc.HiveDriver
hive.url: jdbc:hive2://hostname:10000
dependencies: hive-jdbc-.jar,hive-service-.jar,hadoop-common-.jar,protobuf-java-.jar
![]()
4.查询
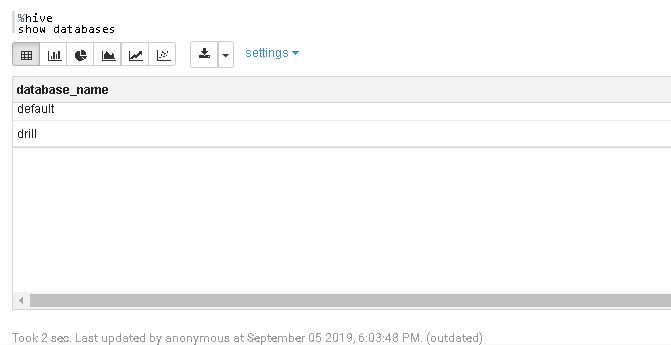
show databases
![]()
use database
![]()
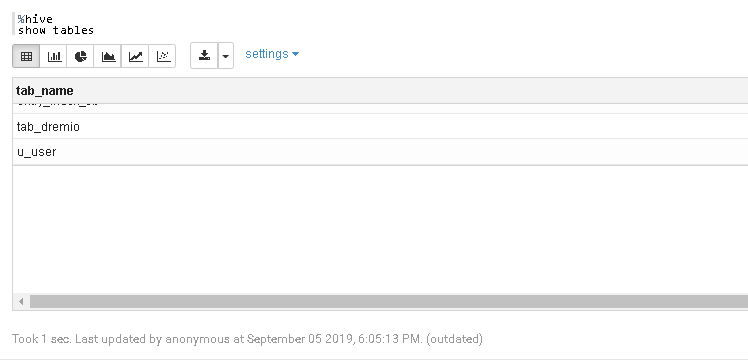
show tables
![]()
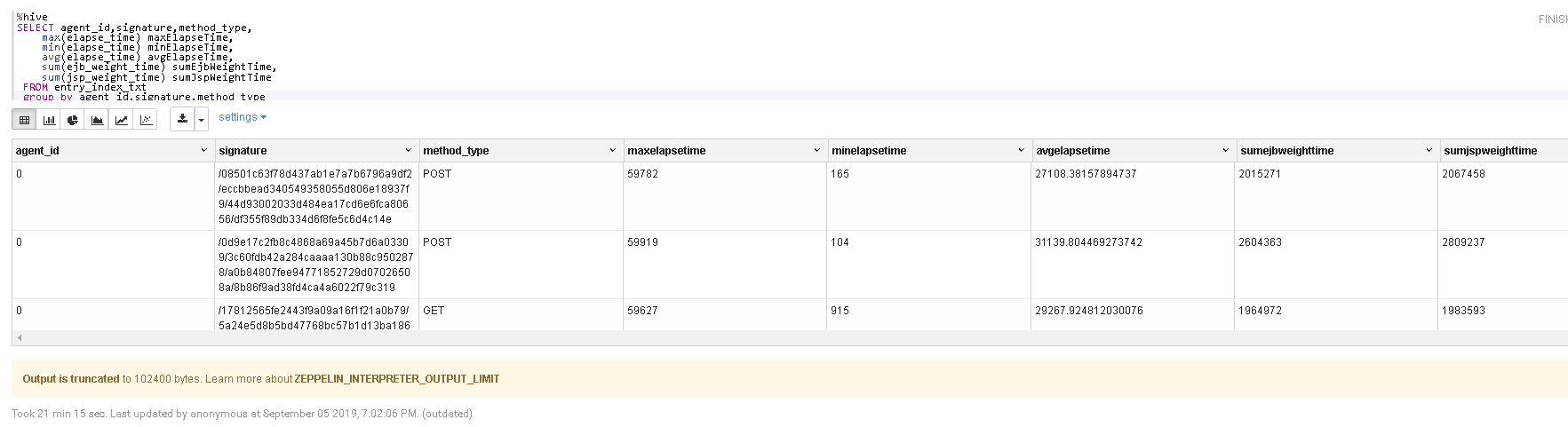
agg query
![]()