1.服务启停
Zookeeper
./zookeeper/bin.zkServer.sh start ./zookeeper/conf/zoo.cfg
./zookeeper/bin.zkServer.sh stop
Hadoop
./hadoop/sbin/start-dfs.sh
./hadoop/sbin/stop-dfs.sh
HBase
./hbase/bin/start-hbase.sh
./hbase/bin/stop-hbase.sh
./hbase/bin/hbase-daemon.sh start master
./hbase/bin/hbase-daemon.sh start regionserver 1
./hbase/bin/hbase-daemon.sh stop master
./hbase/bin/hbase-daemon.sh stop regionserver 1
Alluxio
./alluxio/bin/alluxio local SudoMount
2.HBase配置
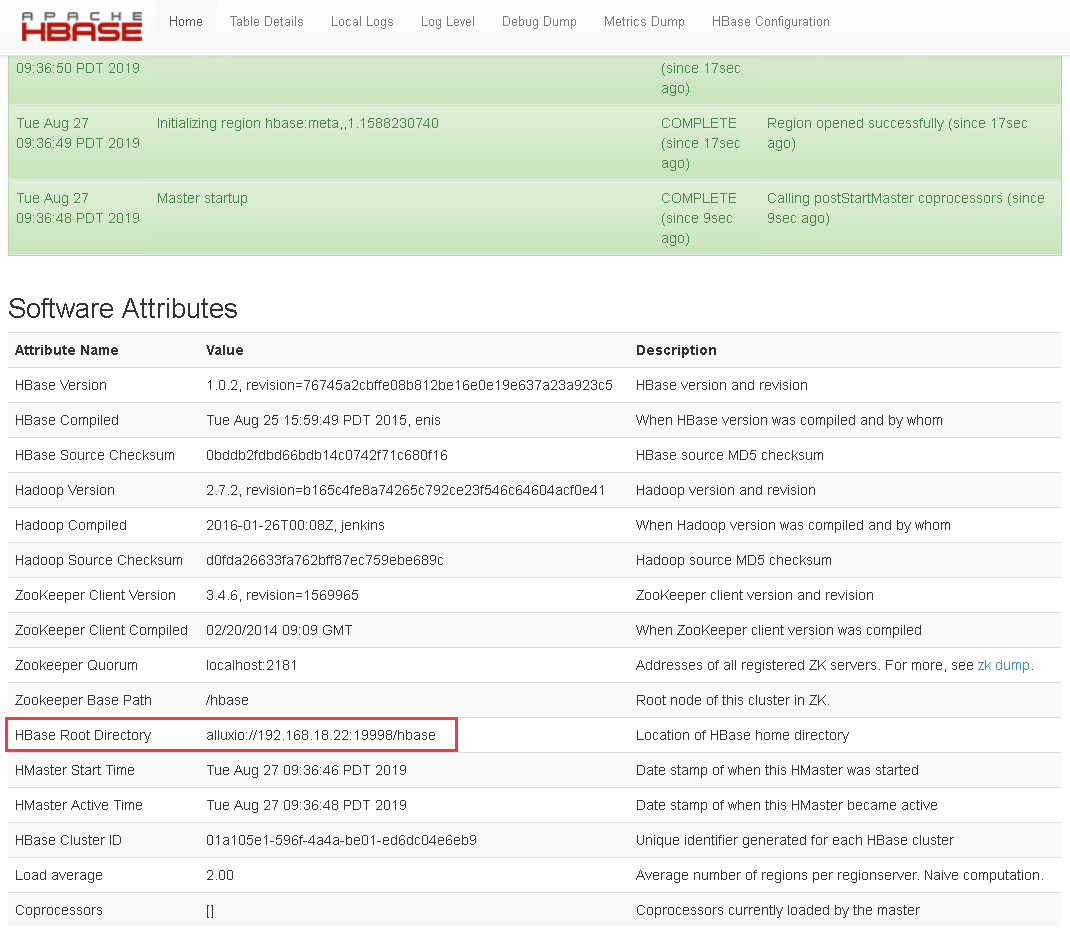
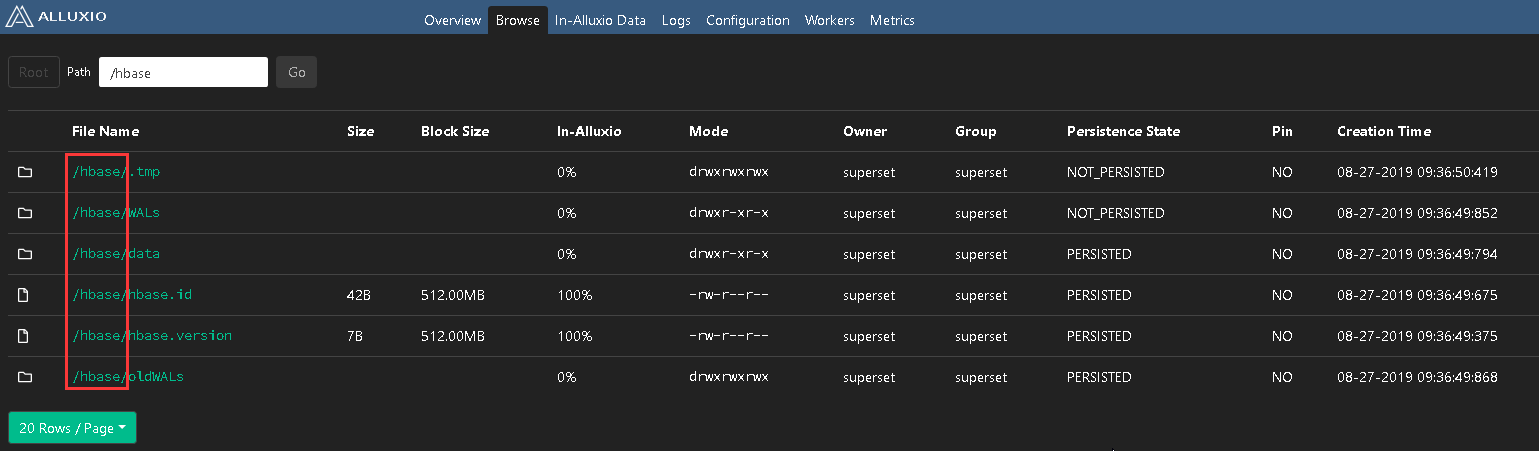
Apache HBase可以通过Hadoop文件系统来使用Alluxio
修改配置vi hbase-site.xml
<!-- 修改hbase.rootdir属性,可通过alluxio访问 -->
<property>
<name>hbase.rootdir</name>
<value>alluxio://master_hostname:19998/hbase</value>
</property>
<!-- 防止HBase以线程不安全的方式刷新Alluxio文件流 -->
<property>
<name>hbase.regionserver.hlog.syncer.count</name>
<value>1</value>
</property>
将alluxio的客户端jar复制到hbase的lib中
cp ./alluxio/client/alluxio-2.0.0.client.jar ./hbase/lib
验证
验证HBase
HBase Master URL: http://hbase_master_hostname:16010
![]()
验证Alluxio
Alluxio Master URL: http://alluxio_master_hostname:19999
![]()
3.测试
测试数据
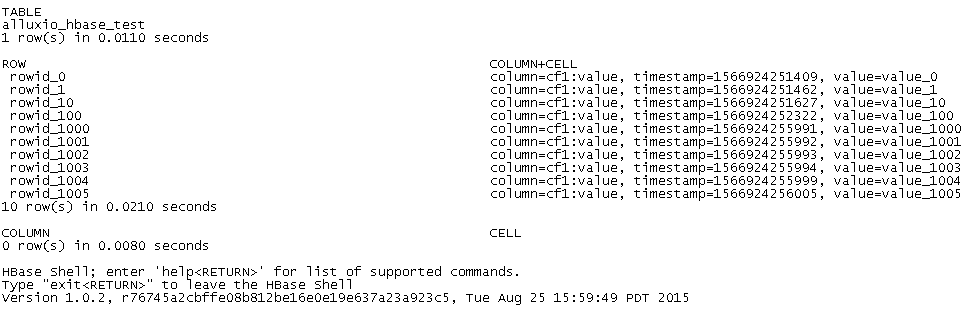
创建HBase表,并模拟插入10000行数据;然后查询展示10行
编辑: vi alluxio_hbase_test.txt
create 'alluxio_hbase_test', 'cf1'
for i in Array(0..9999)
put 'alluxio_hbase_test', 'rowid_'+i.to_s , 'cf1:value', 'value_'+i.to_s
end
list 'alluxio_hbase_test'
scan 'alluxio_hbase_test', {LIMIT => 10, STARTROW => 'row1'}
get 'alluxio_hbase_test', 'row1'
执行命令
./hbase/bin/hbase shell alluxio_hbase_test.txt
测试结果
![]()
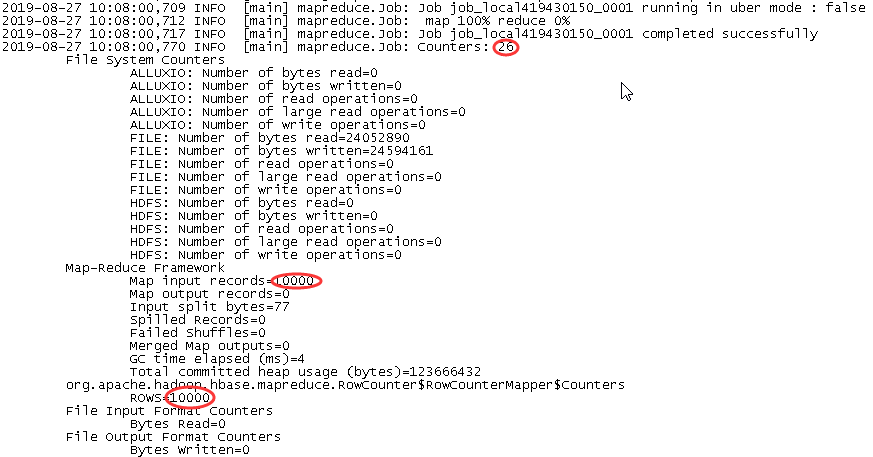
使用Hadoop统计行数
./hbase/bin/hbase org.apache.hadoop.hbase.mapreduce.RowCounter alluxio_hbase_test.txt
![]()