PolarDB初赛进展
写这篇是因为PolarDB比赛很重要的一点是控制内存。C++只有2G,Java也只有3G,而6400W的键值对,即使只是Long类型,也需要16 * 64 * 10e6 ≈ 1G的内存,这还不包括其他对象引用的相关开销,所以内存控制在这里是非常重要的,因为稍不小心就会被CGroup无情地kill掉。因此在比赛开始没多久的时候我就研究了一下使用怎样的HashMap可以达到内存最简的状况。在这个过程中,顺便使用了JMH来分析了一下几个侯选库的性能。因为初赛相对来说比较简单,而且HashMap实际上在复赛时候的Range操作上没有发挥余地,所以我决定将这篇写下来分享给大家,希望能帮助更多对比赛有兴趣的同学找到一个比较好的入手点。
之前的初赛简单思路可以看这里。
侯选的集合库
我们能第一时间想到的最朴素最直接的候选者就是Java自带的HashMap了,这是我们平时使用最多也是最熟悉的实现。只不过在这里因为性能和内存消耗的原因,它稍微有点不合适。其实市面上有很多其他优秀的集合库实现的,我在这里大致列一下我这边会测试的几个:
-
FastUtil: 一个意大利的计算机博士开发的集合库。
-
Eclipse Collections: 由高盛开发的集合库,后来捐给了eclipse基金会,成为了eclipse的项目.
-
HPPC: 专门为原始类型设计的集合库。
-
Koloboke: 又一位大神的作品,目标是低内存高性能。
-
Trove: 挂在bitbucket上面的一个开源项目。
因为是为了比赛而接触的这些库,所以我只按照比赛场景给他们做了测试。我们会预生成6400W对8字节的Key,和8字节的长整型Value,之后会将这些key全部写入各自的HashMap中去,然后再从中读取出来,并与暂存的Value作比较,判断正确性。整个的测试过程是交给JMH来做的。下面介绍一下JMH工具。
JMH简介
JMH是由OpenJDK开发的,用来构建、运行和分析Java或其他Jvm语言所写的程序的基准测试框架。它可以帮助我们自动构建和运行基准测试,并且汇总得到结果。现在一般Java世界里面的主流Benchmark就是应用的JMH。
Scala这边,我们所熟悉的Ktoso大佬包了一个sbt-jmh插件,使得我们可以方便地利用SBT来运行JMH测试。要使用sbt-jmh插件,首先,在plugins.sbt文件里面添加插件:
1// project/plugins.sbt
2addSbtPlugin("pl.project13.scala" % "sbt-jmh" % "0.3.4")
之后,在项目中的模块定义中,使用它:
1// build.sbt
2enablePlugins(JmhPlugin)
然后,我们就可以在sbt的console下,执行如下命令,来运行jmh测试了:
1jmh:run -i 3 -wi 3 -f1 -t1 .*FalseSharing.*
上面的参数解释下来,就是要求项目对符合正则表达式.*FalseSharing.*的基准测试,运行3次,运行之前要进行3次预热,只需要跑一遍,使用一个线程。
好,介绍结束,我们接下来看一下我们如何来编写程序测试各种Map。
HashMap测试代码
首先,我们先创建一个类,如下:
1@State(Scope.Benchmark)
2@OutputTimeUnit(TimeUnit.SECONDS)
3@BenchmarkMode(Array(Mode.Throughput))
4class jmh.HashMapBenchmark {
5
6}
JMH使用注解来标记的基准测试。上面三个注解的选项的意思分别是:
-
State表明可以在类里面创建成员变量,供所有测试复用,复用的范围是在Benchmark当中;
-
OutputTimeUnit表示输出Benchmark结果的时候,计时单位是TimeUnit.SECONDS;
-
BenchmarkMode,Benchmark的模式是测试吞吐率。
为了做基准测试,我们首先创建一个6400W大小的列表,列表的元素是一个二元组,都是Long:
1 val random = new Random(42)
2
3 val testSet: List[(Long, Long)] = List.range(0, 64000000).map { _ =>
4 val key = random.nextLong()
5 val value = random.nextLong()
6 key -> value
7 }
这里有个关于比赛的小技巧,由于Key都是8字节的,所以其实每个Key都很容易转化成Long类型的。所以我们在测试里面也只测试对于Long类型的写入性能,以Java的HashMap为例:
1 @Benchmark
2 @OperationsPerInvocation(OperationsPerInvocation)
3 def testHashMap() = {
4 val hashMap = new util.HashMap[Long, Long](64000000)
5 testSet.foreach { case (k, v) =>
6 hashMap.put(k, v)
7 }
8 testSet.foreach { case (k, v) =>
9 val readValue = hashMap.get(k)
10 assert(readValue == v)
11 }
12 }
@Benchmark表示这是一个要运行的基准测试。@OperationsPerInvocation注解会接收一个数值,表示这个测试的方法运行了多少次。在我们这边是OperationPerInvocation次。注意,前面的变量在jmh.HashMapBenchmark的伴生对象中定义:
1object jmh.HashMapBenchmark {
2 val OperationsPerInvocation = 64000000 * 2
3}
然后,我们就能够启动sbt,输入前面提到的jmh:run命令了。我们先跑一波看看:
1jmh:run -i 3 -wi 3 -f1 -t1 .*HashMap.*
跑起来以后我感觉我错了,电脑风扇在狂转,而且预热半天都跑不完。jstat看一下gc情况试试先,发现100多秒都是FGC。。
1S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
2931840.0 931840.0 0.0 0.0 932352.0 932352.0 5592576.0 5592545.4 9856.0 9391.3 1408.0 1316.6 12 36.611 9 145.669 182.280
3931840.0 931840.0 0.0 0.0 932352.0 932352.0 5592576.0 5592545.4 9856.0 9391.3 1408.0 1316.6 12 36.611 9 145.669 182.280
果断杀掉,加上jvm参数以后再测试:
1jmh:run -i 3 -wi 3 -f1 -t1 --jvmArgs "-Xmx10g" .*HashMap.*
10G也是慢,跑太久了,不乐意跑了,果断放弃。我们直接来看其他的实现。
这里还要说一下,因为内存有要求,所以我们需要同时打印一下HashMap的内存大小。我所使用的是网上找到的一个应该是从Spark代码中抠出来的一个实现,速度快,估值准。只需要在build.sbt中如下引入即可。
1libraryDependencies += "com.madhukaraphatak" %% "java-sizeof" % "0.1"
主要代码编写
因为其实这里的hashmap的库使用其实大同小异,为了避免重复,所以我利用Scala的一些特性来进行代码编写。首先我定义了一个特质为LongLongOp:
1trait LongLongOp {
2 def put(key:Long, value:Long):Long
3 def get(key:Long):Long
4}
之后,我们写一个遍历testSet的函数:
1 def testSetTraverse(hashMap:LongLongOp) = {
2 testSet.foreach { case (k, v) =>
3 hashMap.put(k, v)
4 }
5 testSet.foreach { case (k, v) =>
6 val readValue = hashMap.get(k)
7 assert(readValue == v)
8 }
9 }
然后,我们利用特质可以混入的特性,在生成HashMap的时候,混入LongLongOp,然后交由testSetTraverse执行。这样我们每次只需要新建HashMap即可了。例如,FastUtil的测试如下:
1 @Benchmark
2 @OperationsPerInvocation(OperationsPerInvocation)
3 def testFastUtil() = {
4 val map = new Long2LongArrayMap(MapSize) with LongLongOp
5 testSetTraverse(map)
6 printlnObjectSize("fastutil Long2LongArrayMap", map)
7 }
其中printLnObjectSize是用来打印map占用内存数量的:
1 def printlnObjectSize(message:String, obj: AnyRef) = {
2 val size = SizeEstimator.estimate(obj)
3 val sizeInGB = size.toDouble / 1024 / 1024 / 1024
4 println(s"$message size is ${sizeInGB}GB")
5 }
之后,依次使用Eclipse Collections, Hppc, Koloboke和Trove,就完成了我们的Benchmark编写:
1import java.util.concurrent.TimeUnit
2
3import com.koloboke.collect.impl.hash.MutableLHashParallelKVLongLongMapGO
4import com.madhukaraphatak.sizeof.SizeEstimator
5import gnu.trove.map.hash.TLongLongHashMap
6import org.openjdk.jmh.annotations._
7
8import scala.util.Random
9
10object HashMapBenchmark {
11 final val OperationsPerInvocation = 64000000 * 2
12}
13
14trait LongLongOp {
15 def put(key: Long, value: Long): Long
16
17 def get(key: Long): Long
18}
19
20@State(Scope.Benchmark)
21@OutputTimeUnit(TimeUnit.SECONDS)
22@BenchmarkMode(Array(Mode.Throughput))
23class HashMapBenchmark {
24
25 import HashMapBenchmark._
26
27 val random = new Random(42)
28 val MapSize = 64000000
29
30 val testSet: List[(Long, Long)] = List.range(0, MapSize).map { _ =>
31 val key = random.nextLong()
32 val value = random.nextLong()
33 key -> value
34 }
35
36 def testSetTraverse(hashMap: LongLongOp) = {
37 testSet.foreach { case (k, v) =>
38 hashMap.put(k, v)
39 }
40 testSet.foreach { case (k, v) =>
41 val readValue = hashMap.get(k)
42 assert(readValue == v)
43 }
44 }
45
46 def printlnObjectSize(message: String, obj: AnyRef) = {
47 val size = SizeEstimator.estimate(obj)
48 val sizeInGB = size.toDouble / 1024 / 1024 / 1024
49 println(s"$message size is ${sizeInGB}GB")
50 }
51
52 @Benchmark
53 @OperationsPerInvocation(OperationsPerInvocation)
54 def testEclipseCollection() = {
55
56 import org.eclipse.collections.impl.map.mutable.primitive.LongLongHashMap
57
58 val map = new LongLongHashMap(MapSize)
59 testSet.foreach { case (k, v) =>
60 map.put(k, v)
61 }
62 testSet.foreach { case (k, v) =>
63 val readValue = map.get(k)
64 assert(readValue == v)
65 }
66 printlnObjectSize("Eclipse LongLongHashMap", map)
67 }
68
69 @Benchmark
70 @OperationsPerInvocation(OperationsPerInvocation)
71 def testHppc() = {
72
73 import com.carrotsearch.hppc.LongLongHashMap
74
75 val map = new LongLongHashMap(MapSize, 0.99) with LongLongOp
76 testSetTraverse(map)
77 printlnObjectSize("hppc LongLongHashMap", map)
78 }
79
80 @Benchmark
81 @OperationsPerInvocation(OperationsPerInvocation)
82 def testKoloboke() = {
83 val map = new MutableLHashParallelKVLongLongMapGO() with LongLongOp
84 testSetTraverse(map)
85 printlnObjectSize("Koloboke", map)
86 }
87
88 @Benchmark
89 @OperationsPerInvocation(OperationsPerInvocation)
90 def testTrove() = {
91 val map = new TLongLongHashMap(MapSize, 1.0f) with LongLongOp
92 testSetTraverse(map)
93 printlnObjectSize("Trove LongLongMap", map)
94 }
95}
其中Eclipse collection的put方法的返回值是void,与其他集合不一样,所以只能单独为它写一个测试方法。
结果
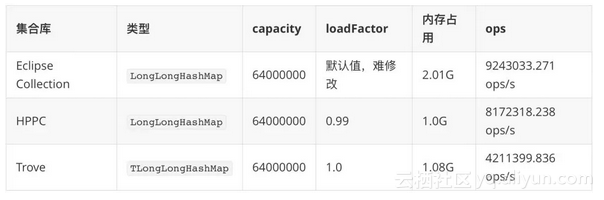
运行的过程中,Koloboke报一个诡异的空指针错误,所以没有通过测试;FastUtils在这个量级好像有点慢,不乐意等所以最终没有把它加入测试。最终我们得到如下的结果列表:
![5d361c29ca0cc06caf49bb861cc5cef0fe34fe68]()
综合内存使用以及性能,我个人觉得在此次比赛初赛中,也许HPPC是个比较好的选择。
所以,初赛使用Java的HashMap实现的小伙伴,是不是应该赶紧思考一下换一下内存索引的结构,来避免OOM呢?
原文发布时间为: 2018-11-07
本文作者:Kirito的技术分享
本文来自云栖社区合作伙伴“Kirito的技术分享”,了解相关信息可以关注“Kirito的技术分享”。