
高并发架构系列:Redis缓存和MySQL数据一致性方案详解
需求起因
在高并发的业务场景下,数据库大多数情况都是用户并发访问最薄弱的环节。所以,就需要使用redis做一个缓冲操作,让请求先访问到redis,而不是直接访问MySQL等数据库。
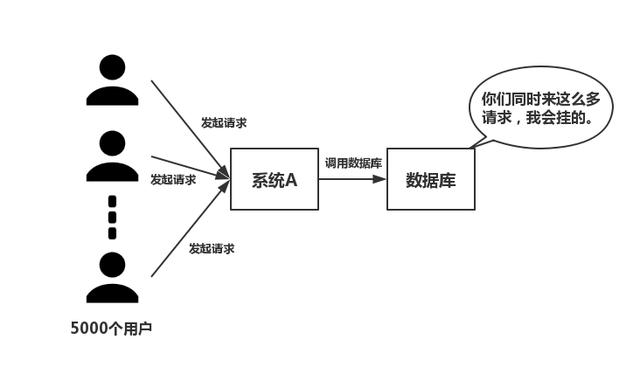
这个业务场景,主要是解决读数据从Redis缓存,一般都是按照下图的流程来进行业务操作。
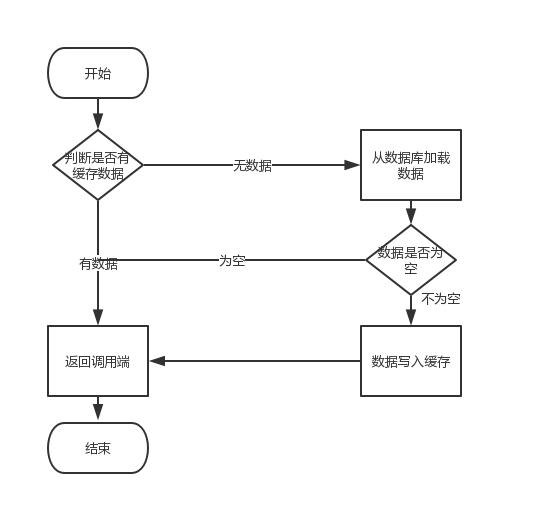
读取缓存步骤一般没有什么问题,但是一旦涉及到数据更新:数据库和缓存更新,就容易出现缓存(Redis)和数据库(MySQL)间的数据一致性问题。
不管是先写MySQL数据库,再删除Redis缓存;还是先删除缓存,再写库,都有可能出现数据不一致的情况。举一个例子:
1.如果删除了缓存Redis,还没有来得及写库MySQL,另一个线程就来读取,发现缓存为空,则去数据库中读取数据写入缓存,此时缓存中为脏数据。
2.如果先写了库,在删除缓存前,写库的线程宕机了,没有删除掉缓存,则也会出现数据不一致情况。
因为写和读是并发的,没法保证顺序,就会出现缓存和数据库的数据不一致的问题。
如来解决?这里给出两个解决方案,先易后难,结合业务和技术代价选择使用。
缓存和数据库一致性解决方案
1.第一种方案:采用延时双删策略
在写库前后都进行redis.del(key)操作,并且设定合理的超时时间。
伪代码如下
public void write(String key,Object data){ redis.delKey(key); db.updateData(data); Thread.sleep(500); redis.delKey(key); } 2.具体的步骤就是:
1)先删除缓存
2)再写数据库
3)休眠500毫秒
4)再次删除缓存
那么,这个500毫秒怎么确定的,具体该休眠多久呢?
需要评估自己的项目的读数据业务逻辑的耗时。这么做的目的,就是确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
当然这种策略还要考虑redis和数据库主从同步的耗时。最后的的写数据的休眠时间:则在读数据业务逻辑的耗时基础上,加几百ms即可。比如:休眠1秒。
3.设置缓存过期时间
从理论上来说,给缓存设置过期时间,是保证最终一致性的解决方案。所有的写操作以数据库为准,只要到达缓存过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存。
4.该方案的弊端
结合双删策略+缓存超时设置,这样最差的情况就是在超时时间内数据存在不一致,而且又增加了写请求的耗时。
2、第二种方案:异步更新缓存(基于订阅binlog的同步机制)
1.技术整体思路:
MySQL binlog增量订阅消费+消息队列+增量数据更新到redis
1)读Redis:热数据基本都在Redis
2)写MySQL:增删改都是操作MySQL
3)更新Redis数据:MySQ的数据操作binlog,来更新到Redis
2.Redis更新
1)数据操作主要分为两大块:
- 一个是全量(将全部数据一次写入到redis)
- 一个是增量(实时更新)
这里说的是增量,指的是mysql的update、insert、delate变更数据。
2)读取binlog后分析 ,利用消息队列,推送更新各台的redis缓存数据。
这样一旦MySQL中产生了新的写入、更新、删除等操作,就可以把binlog相关的消息推送至Redis,Redis再根据binlog中的记录,对Redis进行更新。
其实这种机制,很类似MySQL的主从备份机制,因为MySQL的主备也是通过binlog来实现的数据一致性。
这里可以结合使用canal(阿里的一款开源框架),通过该框架可以对MySQL的binlog进行订阅,而canal正是模仿了mysql的slave数据库的备份请求,使得Redis的数据更新达到了相同的效果。
当然,这里的消息推送工具你也可以采用别的第三方:kafka、rabbitMQ等来实现推送更新Redis。
以上就是Redis和MySQL数据一致性详解,相关的MySQL数据库主从同步一致性可以参考:《高并发架构系列:数据库主从同步的3种一致性方案实现,优劣比较》
觉得不错请点赞支持,欢迎留言或进我的个人群179961551领取【架构资料专题目合集90期】、【BATJTMD大厂JAVA面试真题1000+】,本群专用于学习交流技术、分享面试机会,拒绝广告,我也会在群内不定期答题、探讨。
 关注公众号
关注公众号 低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。
持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
转载内容版权归作者及来源网站所有,本站原创内容转载请注明来源。
- 上一篇

记一次找因redis使用不当导致应用卡死bug的过程
首先说下问题现象:内网sandbox环境API持续1周出现应用卡死,所有api无响应现象 刚开始当测试抱怨环境响应慢的时候 ,我们重启一下应用,应用恢复正常,于是没做处理。但是后来问题出现频率越来越频繁,越来越多的同事开始抱怨,于是感觉代码可能有问题,开始排查。 首先发现开发的本地ide没有发现问题,应用卡死时候数据库,redis都正常,并且无特殊错误日志。开始怀疑是sandbox环境机器问题(测试环境本身就很脆!_!) 于是ssh上了服务器 执行以下命令 top 这时发现 机器还算正常,但是内心还是?,于是打算看下jvm 堆栈信息 先看下问题应用比较耗资源的线程 执行 top -H -p 12798 找到前3个相对比较耗资源的线程 jstack 查看堆内存 jstack 12798 |grep 12799的16进制 31ff 没看出什么问题,上下10行也看看 于是执行 看到一些线程都是处于lock状态。但没有出现业务相关的代码,忽略了。这时候没有什么头绪。思考一番。决定放弃这次卡死状态的机器 为了保护事故现场 先 dump了问题进程所有堆内存,然后debug模式重启测试环境应用,打...
- 下一篇
零距离接触阿里云时序时空数据库TSDB
概述 最近,Amazon新推出了完全托管的时间序列数据库Timestream,可见,各大厂商对未来时间序列数据库的重视与日俱增。 阿里云TSDB是阿里巴巴集团数据库事业部研发的一款高性能分布式时序时空数据库,在即将过去的2018年,我们对TSDB进行了多次的系统架构改进,引入了倒排索引、无限时间线支持、时序数据高压缩比算法、内存缓存、数据预处理、分布式并行聚合、GPU加速等多项核心技术,并且引入了新的计算引擎层和分布式SQL层,使得引擎核心能力有了质的提升,也基本上统一了集团内部的监控存储业务。2018年双11当天,TSDB稳定运行,0故障,支撑双十一核心业务系统,毫秒级采集能力,具备双十一峰值写入不降级,创造了集群TPS 4000万、QPS 2万的新纪录。同时,面向IOT赛道,推出了时空数据库和边缘计算版本,还会引入面向时序时空场景的智能引擎,未来我们的目标是把TSDB打造成一款业内领先的“智联网数据库”。 2018双十一数据 首先,我们来看一下TSDB在2018年双十一的答卷:TSDB承受了4000万/秒的峰值写入,2万/秒的峰值查询,与2017年双十一相比均翻倍增长;而写入均值也...
相关文章
文章评论
共有0条评论来说两句吧...
文章二维码
点击排行

推荐阅读






最新文章
- CentOS关闭SELinux安全模块
- CentOS7设置SWAP分区,小内存服务器的救世主
- Docker安装Oracle12C,快速搭建Oracle学习环境
- Docker快速安装Oracle11G,搭建oracle11g学习环境
- CentOS7编译安装Gcc9.2.0,解决mysql等软件编译问题
- Docker使用Oracle官方镜像安装(12C,18C,19C)
- CentOS8安装MyCat,轻松搞定数据库的读写分离、垂直分库、水平分库
- CentOS8编译安装MySQL8.0.19
- Springboot2将连接池hikari替换为druid,体验最强大的数据库连接池
- CentOS8安装Docker,最新的服务器搭配容器使用
 微信收款码
微信收款码 支付宝收款码
支付宝收款码