概述
最近,Amazon新推出了完全托管的时间序列数据库Timestream,可见,各大厂商对未来时间序列数据库的重视与日俱增。
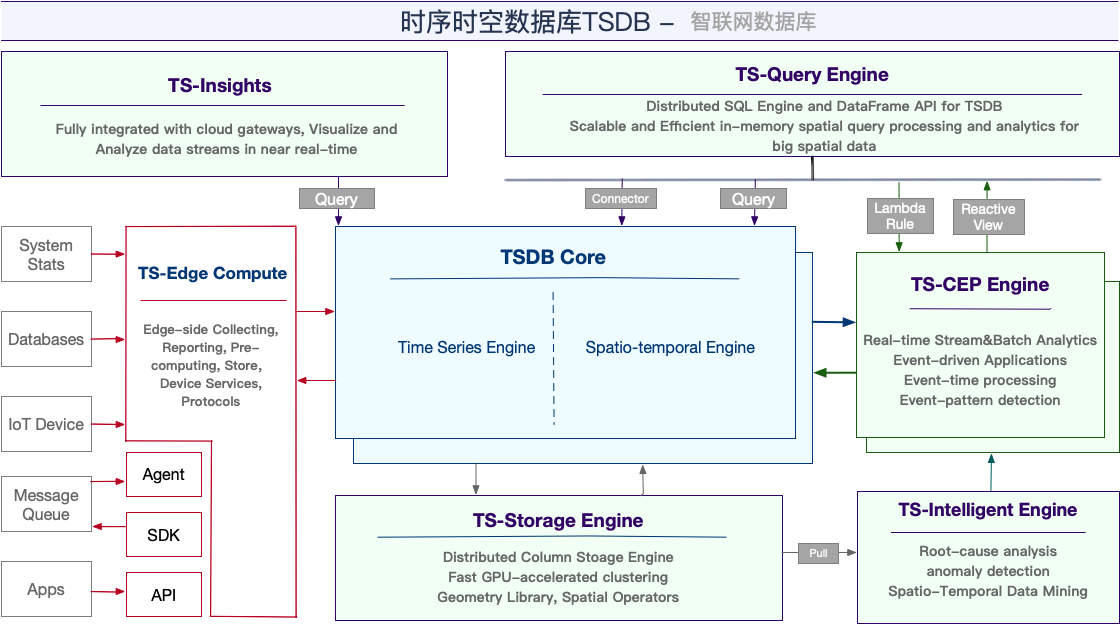
阿里云TSDB是阿里巴巴集团数据库事业部研发的一款高性能分布式时序时空数据库,在即将过去的2018年,我们对TSDB进行了多次的系统架构改进,引入了倒排索引、无限时间线支持、时序数据高压缩比算法、内存缓存、数据预处理、分布式并行聚合、GPU加速等多项核心技术,并且引入了新的计算引擎层和分布式SQL层,使得引擎核心能力有了质的提升,也基本上统一了集团内部的监控存储业务。2018年双11当天,TSDB稳定运行,0故障,支撑双十一核心业务系统,毫秒级采集能力,具备双十一峰值写入不降级,创造了集群TPS 4000万、QPS 2万的新纪录。同时,面向IOT赛道,推出了时空数据库和边缘计算版本,还会引入面向时序时空场景的智能引擎,未来我们的目标是把TSDB打造成一款业内领先的“智联网数据库”。
2018双十一数据
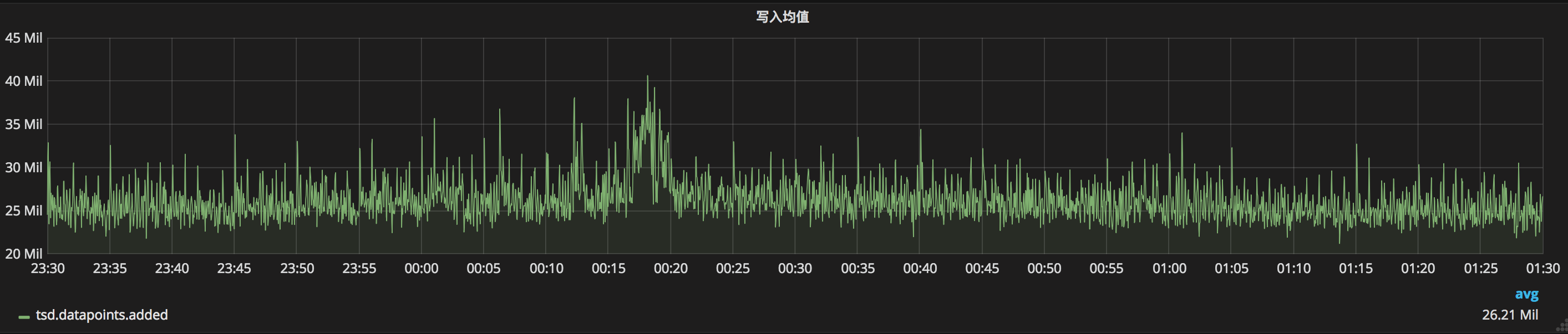
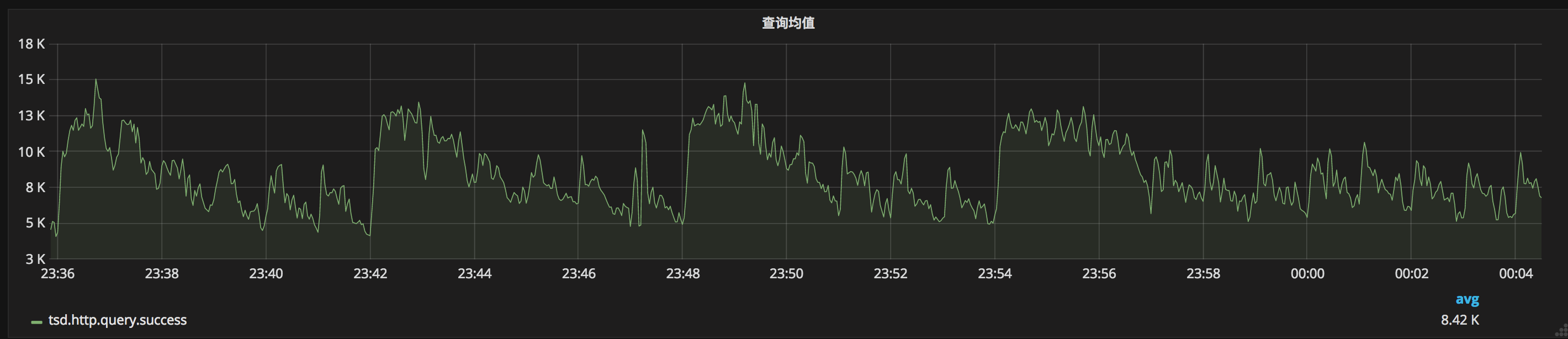
首先,我们来看一下TSDB在2018年双十一的答卷:TSDB承受了4000万/秒的峰值写入,2万/秒的峰值查询,与2017年双十一相比均翻倍增长;而写入均值也达到了2600万/秒,查询均值达到了8000次/秒。
![image.png | left | 746x159]()
![image.png | left | 746x161]()
场景
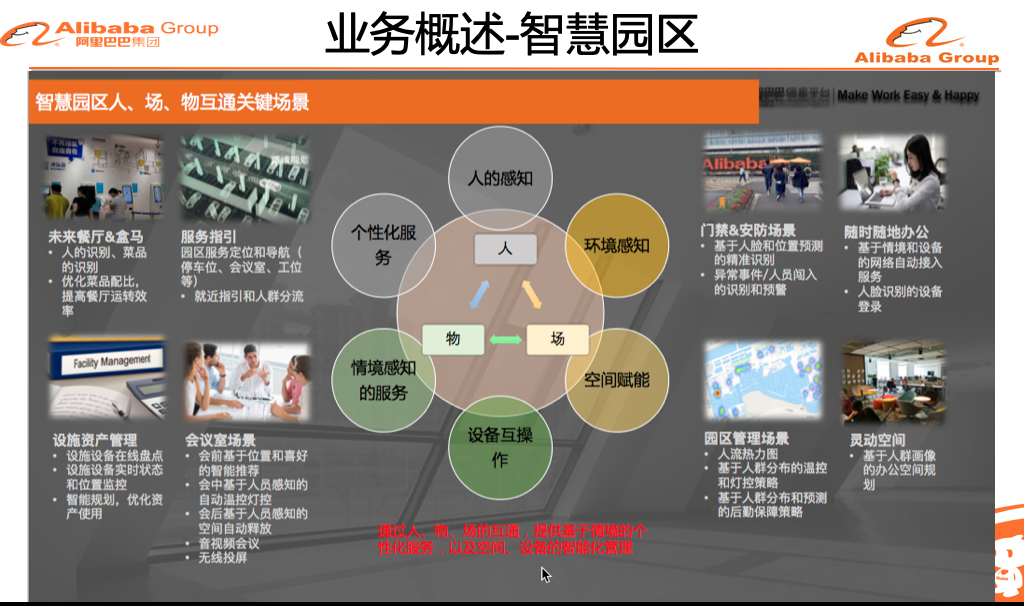
下面几页Slide是我们在外部的一些场景和客户案例:
![image.png | left | 746x442]()
![image.png | left | 746x421]()
![image.png | left | 746x444]()
核心技术解析
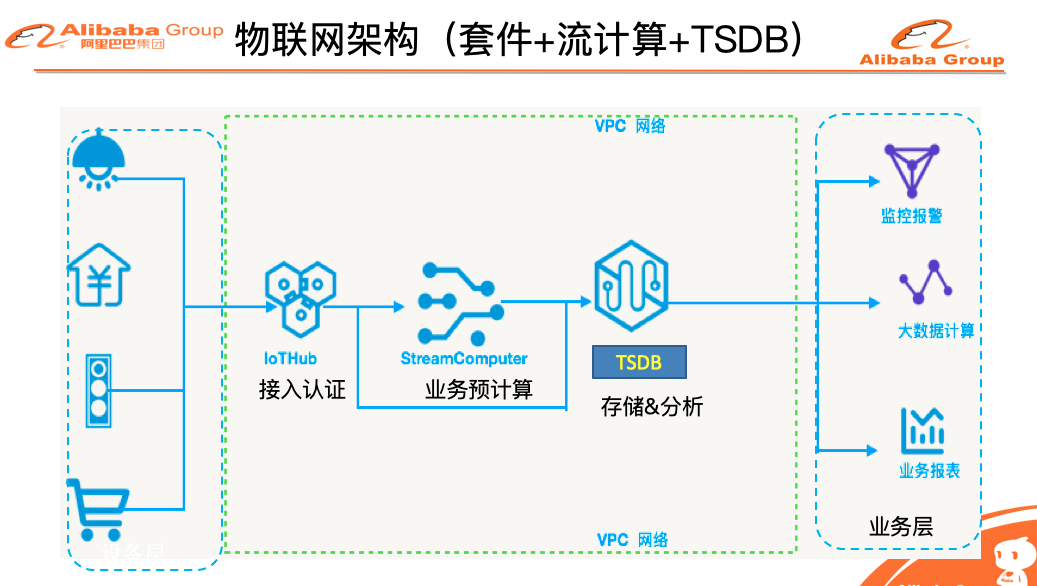
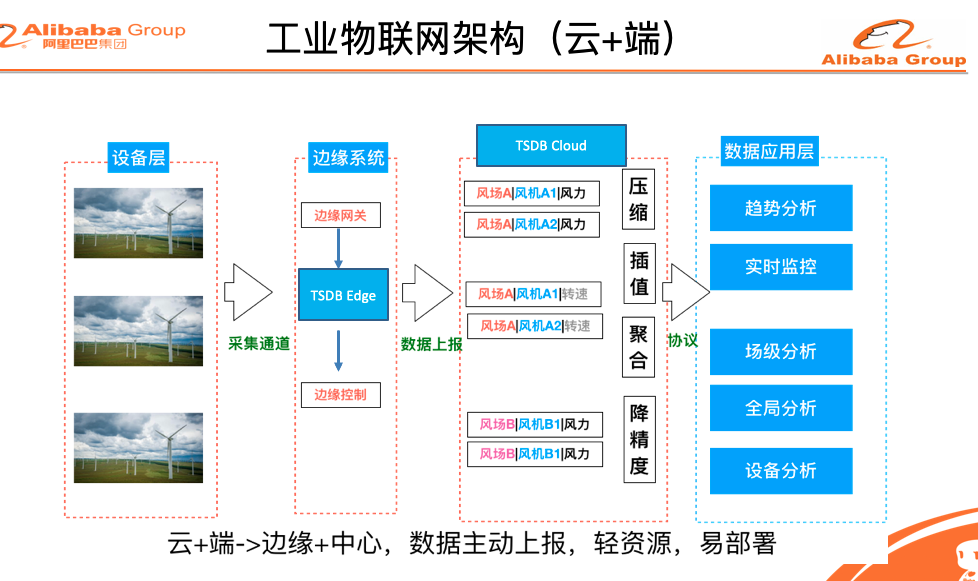
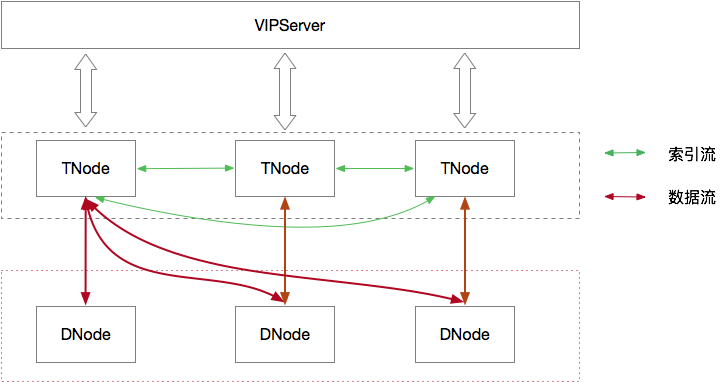
为了更好的支持业务的需求,今年我们在核心引擎层面做了非常多的优化和改进,我们还引入了新的计算引擎层,分布式SQL引擎,时空引擎以及面向IoT市场的边缘计算版本,极大的提高了TSDB的计算能力和场景。下图就是TSDB的主要架构图,接下来的篇章我会分时序引擎,计算引擎,SQL引擎,时空引擎,边缘计算这5大部分来详细的介绍我们的核心技术能力。
![image.png | left | 746x416]()
一、时序引擎
问题挑战
稳定性、流量翻倍、不降级、低延迟、无限时间线
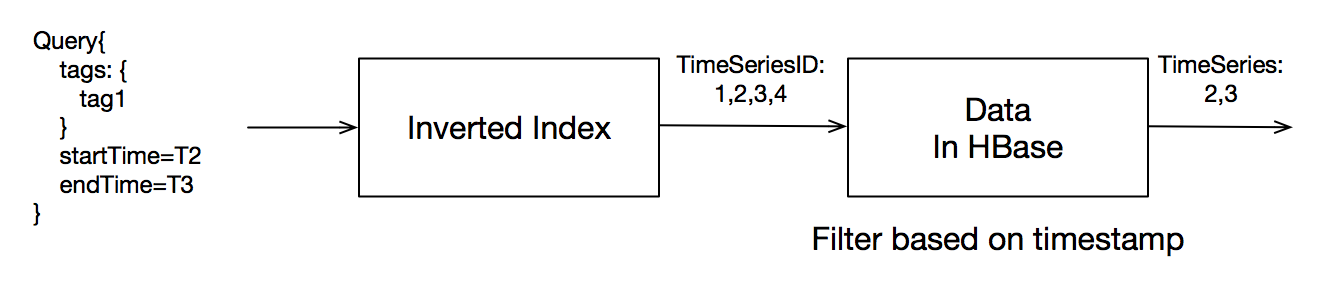
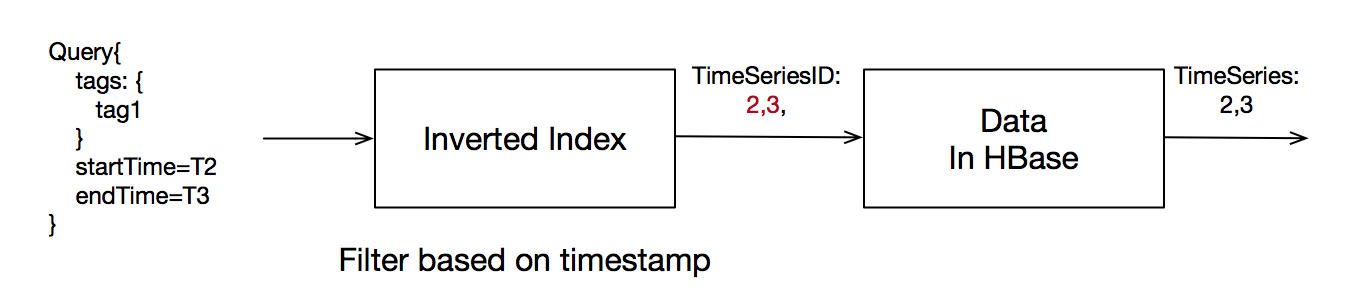
1. 复杂时间线索引、无限制时间线支持:
问题
为了支持多维查询和聚合查询,TSDB使用了倒排索引以快速定位到某条时间线。在TSDB现有的实现里,倒排索引是全部存放在内存中的。该方案的好处是根据某个Tag或者Metric查找时间线时会非常高效,但是缺点也非常明显:受限于内存大小,TSDB无法支持大规模的时间线。随着TSDB的客户越来越多,这个问题也越来越突出:某直播业务要求TSDB能够支撑20亿时间线的规模;某监控业务虽然初始时间线只有上千万,但是每天会新增几十万条时间线,而且时间线规模没有上限。
方案
TSDB在之前全内存倒排索引的基础上,将倒排索引持久化到硬盘,赋予了TSDB支撑无限时间线的能力。同时,通过给予倒排索引时间的概念,我们将查询的时间过滤算子下推到了索引查询阶段,进一步优化了查询性能。而通过创建时间线索引的BloomFilter,TSDB保证了海量时间线规模下的低延迟索引查询。
![image | left]()
![image | left]()
效果
拿集团内业务举例,原来64G内存的机器只能支持到不到500万的时间线,采用了上面的技术方案后,64G内存的机器就可以支持业务将近7000万以上的时间线,而且时间线数量在原有机器的基础上还可以继续增加。
2. 高效列式内存缓存、时间线内存分片:
为了加速数据的写入和查询能力,今年我们为TSDB设计了全内存的分布式高效缓存,具体架构图如下:
![image | left]()
效果
最终我们测试效果是:在单个docker下,单机TPS从原来的50W提升到100W+,QPS从原来的1K提升到2K+ ;并且这个改进很好的支持了集团魔兔业务的需求和发展。
3. 工作负载管理:
为了更好的解决数据量大的情况下的负载均衡的问题,我们做了许多工作,主要包括:
- 通过读写分离机制进一步提升写入和查询性能;
- 快慢查询自动分级,让慢查询不再拖累其他查询;
- 自动限流保护,无需业务方降级,无惧双十一洪峰。
效果
双十一结果证明,新的负载管理策略帮助业务方非常平滑的度过了流量洪峰。
4. 时序全新存储引擎——Lindorm:
这里需要提到的另外一点是,TSDB时序最新架构采用了Lindorm作为存储引擎,能够以更少的机器成本提供更高的吞吐、更低的延迟。下图为采用Lindorm存储引擎前后的TSDB写入延迟。
![image.png | left]()
5. 聚合器
丰富的流式聚合算子:15+聚合,10+填充策略,支撑大量的adhoc操作:groupby, in,not_literal_or, topN, limit等等;支持不规则时间序列数据的处理,TSDB提供的填值策略,可以很轻松地将不规则的时间序列转换为常规时间序列进行处理;支持top-bottom等聚合方式。
6. 混合存储记录块
时序数据存储的记录块方式是其查询性能的基石。TSDB既支持基于时间线的存储方式,
同时支持基于窗口的数据记录切分,复用同一套流式聚合,满足不同业务场景性能需求。
7. 服务化
TSDB服务目前已经在阿里云上出售,目前提供小规格版本以及标准规格版本,满足了很多用户的需求,但依然有一些用户希望提供更小规格的TSDB服务。为了更好满足用户的需求,TSDB提供服务化功能。服务化功能是通过多个用户共享一个TSDB集群的方式来提供更小规格的TSDB服务
- 数据安全:HTTPS支持,用户认证
- 并发管理:写入并发管理,查询并发管理
- 性能管理:写入性能管理,查询性能管理
- 使用量管理:数据点管理,时间线管理
![image.png | left | 746x375]()
时序引擎接下来会继续突破核心技术,包括:自驱动索引TPI,多值数据模型,时序算法,内存计算等等。从功能,性能,成本,生态方面进一步发力,打通K8S指标存储体系,具备兼容Prometheus的能力。
二、 时序计算引擎TSCE
业务接入量快速突破的过程中, 也带来了数据存储量级与查询复杂度的快速增长, 单TSDB实例 在存储与计算方面的技术挑战也面临跳跃式提升. 为了避免查询性能逐渐偏离用户设定的目标, TSDB的架构演进过程也引入相关的创新机制, 并最终延伸出时序产品体系中的新成员 - 时序计算引擎(TimeSeries Computing Engine, TSCE).
时序计算引擎(TSCE) 定位为对TSDB中原生数据进行流式计算的独立组件, 在时序产品体系中与时序数据库(TSDB)紧密结合, 提供诸如时序数据降采样(DownSample), 时间维度预聚合, 时间线降维归档 等涵盖时序数据查询与存储相关的核心计算能力.
同时, 针对应用特定的应用型时序计算场景, 时序计算引擎(TSCE) 亦支持自定义计算规则与函数, 满足各类应用自身的特定业务需求. 常见的应用型时序计算场类型: 时序事件告警, 事件模式匹配, 时序异常分析与检测等.
TSCE的产品形态如下:
时序计算引擎(TSCE)作为独立组件进行部署, 用户需要在TSDB实例的基础上根据成本与应用需求选择是否开启TSCE时序计算处理. 在这种产品形态下, 用户可以独立调整TSDB的存储规格 和 TSCE的计算容量, 做到根据应用特点弹性调整各自组件的实例规模. 在满足应用要求的情况下将TSDB/TSCE实例部署成本控制在合理区间.
TSDB与TSCE结合之后, TSDB引擎会在数据入库过程中同时让TSCE引擎感知数据流动, TSCE会基于配置的时序计算能力或业务规则对数据流进行计算与分析, 计算后的结果支持三种反馈形式: 1.直接反馈至TSDB存储层,供TSDB查询. 2.作为视图以API或者SQL方式访问. 3.通过Reactive机制投递给其他事件处理渠道.
时序计算引擎TSCE 支持通过 TS-API 或者 Web控制台 进行时序计算能力/自定义规则的配置.
(1) 时序计算
TSDB与TSCE协作工作时, 针对核心的时序计算能力, TSCE会与TSDB的进行无缝集成. 此时核心的时序计算处理对于TSDB终端用户而言是透明,无感知的执行过程. 用户开启并配置TSCE处理后, 原来的数据查询方式与查询格式不变, 整个计算的处理完全在后台自动执行.
在查询层面上, 通过TSCE提供的时序计算处理, TSDB会在尽可能的情况下将查询经过TSCE处理的计算结果.即使是在海量数据场景下, 也能提供时序数据的秒级分析查询与时间维度钻取查询.
而在数据存储层面上, 随着时间线的流逝, TSCE会对原生历史数据进行降维计算, 将细粒度的时间点逐步转化为粗粒度的时间点归档存储(例如秒级数据点转化为分钟级数据点), 进一步控制TSDB中存储空间与资源的使用量, 使得TSDB的稳定性与性能波动处于可控范围. 通过TSDB与TSCE结合, TSDB中管理的数据体量可以控制在合理水平, 提升资源占用率的同时进一步节省产品使用成本.
- 数据流预聚合
诸如max/min/avg/count/sum等常见的 可累加式 状态值, TSCE可以在数据流动过程中即完成相关数据的统计与计算.
![image.png | left]()
![image.png | left]()
针对时间线(TimeSeries)的窗口粒度,数值分布等特征关系, 对时间线进行特征值转换的计算过程. 例如降采样(Dowmsampling)运算可以将秒级时间线转化为分钟级时间线, 经过转化后的时间线可以在查询流程上支持时间维度上下钻的即席查询; 而在存储流程上, 可以支持时间线归档存储, 将原始细粒度时间线转化为粗粒度时间线后,清除原始的数据点,释放相关资源.
(2) 时序流处理
针对应用特定的应用型时序计算场景, TSCE通过引入自定义计算规则与函数, 来满足各类应用自身的特定业务计算需求. 用户在经过简单的规则配置后, TSCE引擎会负责底层的数据流打通, 流计算拓扑映射, 分布式节点间的Shuffle与结果归并, 计算后结果集的存储与投递等一系列动作细节.
与General-purpose的流计算处理相比, TSCE的时序流处理除了实现降低技术门槛之外,做到底层流计算能力的弹性扩展之外, 也提供几个核心能力:
- 时序数据库的紧密集成: 因为TSCE与TSDB部署在相同的内部环境内,TSCE可以在非常低的成本下做到与TSDB做数据交换,并且可以直接访问到TSDB后端的数据存储层. 与常规应用方案中 需要先经过流处理再写入时序存储产品的架构相比, 引擎间的紧密集成可以做到效率,成本,性能的成倍提升.
- Reactive查询视图: 流处理后的结果集除了写回TSDB中存储之外, TSCE也支持将数据流转储为Reactive查询视图. Reactive查询视图除了可以支持以SQL/API方式查询结果之外, 也可以通过指定Subscriber订阅相关数据流更新, 当结果集在视图中产生变动时, TSCE会投递数据变更事件至相关Subscriber指定的渠道中(适合监控告警以及自动化处理等业务).
时序流处理规则
定义一个流处理规则包含了3个元素: 1.数据源(TSDB中的时间线), 2.自定义计算规则, 3.计算结果的输出源;其中数据源来自于TSDB数据库, 业务方可以通过规则匹配1条或多条时间线作为数据输入源. 而计算结果的输出源可以是写会TSDB, 或者转储为Reactive视图.
此外用户也可以通过lambda自定义与业务逻辑处理相关的函数, 加入到整体的规则处理链中.
(3) 时序分析与智能引擎
除了配置TSCE的 时序计算能力 与 自定义时序流处理之外, TSCE也提供一些常见的时序分析与智能处理能力:
时序分析
简单的时序流复杂事件处理(CEP): 提供时间线上数据点之间的关系侦测,模式匹配等.
智能引擎
TSCE支持与时序智能引擎进行联通,让用户具备针对时序数据流进行时序异常探测,故障root-cause分析,流式模型训练等相关高级能力. 技术实现上TSCE以Function,DSL等形式进行智能引擎的规则定义与转换, TSCE在数据流的计算过程中会基于内存间数据共享/RPC等方式完成与智能引擎的联动与交互
4. 应用场景
双十一期间, TSCE时序计算引擎支撑的几个典型业务场景:
- 海量数据下的时间线降维度,预聚合查询
- 基于阈值的简单事件告警
- 时序数据的降维归档存储
- 验证初期的时序分析能力(与智能引擎结合)
三、分布式MPP SQL引擎:
1. 需求
今年我们决定在TSDB上设计开发一个分布式的SQL查询引擎,为什么要这么做呢?主要有以下几个原因:
- 从简单时序监控到复杂时序分析
TSDB引擎所支持的查询主要是简单的降采样和分组聚合,随着越来越多业务把时序数据存储到TSDB,我们需要提供一个基于SQL的分布式查询引擎,支持更复杂的时序计算(聚合,时序Join, SQL Window function, UDF), 从而推广TSDB到更广泛的业务中。
- 扩展时序数据库的生态系统
生态系统是一个产品是否成功的关键因素。通过时序SQL查询引擎,TSDB数据库可以和现有的BI tool实现无缝对接。在集团内部,我们正在和阿里云的QuickBI和IDB等团队合作,把TSDB演进成一个支撑重要BI数据分析的数据库产品。未来,通过时序SQL查询引擎,可以对接市场上常见的BI tool, 比如Tableau, Qlik, Power BI等众多工具。
- 支持多种异构数据源的联合分析
通常,业务把时序相关的数据存储在TSDB,非时序数据存储在其他系统中,比如维度信息存储在MySQL等。业务需要在多种数据中进行Join。时序SQL查询引擎支持业务在多种数据源之间直接进行查询分析,避免业务方复制异构数据源再进行联合分析。
- 对标业界主要竞争产品
时序数据库在国外最主要的竞争产品包括TimeScaleDB, InfluxDB, KDB+,Prometheus。TimeScaleDB作为Postgres的一个扩展,提供了标准SQL的支持,而InfluxDB/KDB+提供了类似于SQL (SQL-like)的查询支持。我们TSDB系统通过时序SQL查询引擎,更好地对标国外主要时序竞争产品。
2. SQL引擎的挑战
除了海量时序数据带来的挑战外,时序SQL查询引擎还面临和时序场景相关的挑战:
-
数据table Schema的管理
- 时序metric数目海量:Sunfire等集团内部业务有上亿规模的时间线,而盒马业务中将tag编码进metric, 时间线数目巨大,这和一般数据库中数千或数万的table是巨大的区别;
- 时序metric schema动态变化:业务方随着应用的变化,经常需要增加或减少一个tag。这意味着metric所对应的schema也在不断变化之中。海量时间线+动态变化对查询引擎获取metric的schema 是一个挑战。
- 数据schema-on-write对查询引擎的影响
大多数的数据库在用户写入数据或查询之前,必须先通过DDL创建table schema,这些table schema等元数据又被存放在一个catalog或meta data store, 供数据写入或查询时使用。而时序数据库的业务中,大部分的数据源来自于监控设备的一个agent, 或者IOT物联网的一个sensor, 要求先定义DDL再写入数据会严重影响可用性; 同时,时序metric所对应的tag集合在应用演进过程中,变化很常见。针对这一的应用特点,时序数据库TSDB,InfluxDB, Prometheus都采用了一种'Schema-on-write'的机制,应用直接写入数据,table schema是隐含在数据中。在'Schema-on-write'的机制下,需要解决没有DDL的情况下SQL查询引擎如何从海量时间线中获取table schema等元数据的问题。
在现有以关系运算为基础的SQL查询引擎中。为支持时序功能扩展,我们需要一个易于扩展功能的架构,能支持开发时序相关的功能,比如时序Join, 时序相关的用户自定义函数(UDF)。
一个SQL查询引擎,优化器是性能优劣的关键。需要在通用的SQL查询引擎中,引入时序数据统计信息,作为输入提供给优化器;同时,在优化器中,引入时序相关的优化Rule, 比如FilterPushDown/ProjectPushDown规则,这些都是时序SQL查询引擎需要解决的问题。
3. SQL引擎
SQL查询引擎是一个分布式的系统,其特点:
- 每个计算节点在系统中是对等的,并没有主从关系,
- 任何一个节点都可以成为Foreman, 负责SQL查询计划的生成,而其他节点成为worker nodes
- 无状态,一个节点失效后,可以快速启动备用节点。
4. 应用场景
- 盒马零售业绩时序数据查询: 业务方需要通过SQL查询TSDB的时序数据,接入业务方的分析图表大屏。此外,业务方需要支持简单的SQL简单查询外,还包括异构多种数据源的join的支持。![image]
- 云监控:通过提高SQL查询支持,业务方能统一数据访问方式![image]
四、 时空数据库
1. 需求
随着TSDB的业务发展,时序数据库TSDB渐渐走出APM与监控领域,在IoT领域也获得广泛应用。 而由于IoT领域的特性,其中采集到的很多数据不光有时间信息,还有空间信息与之关联。因此时序数据库也需要能够识别和处理空间信息,以便于更好地服务IoT场景。
对于传统的时间序列数据库,比如说OpenTSDB,如果用户想要存储和查询地理坐标信息,往往需要将经度和纬度分开存储,生成独立的时间线。但是使用时想要将两者重新关联起来需要用户做额外处理。另外一种方式则是需要用户自己将地理位置信息进行编码,常见有的GeoHash或者Google S2。然后将编码信息作为时间线信息进行存储。即使这样,用户依旧需要开发时空过滤功能等等。
2. 方案
在IoT场景中,对于地理坐标信息的采集十分普遍。因此在时序数据库的基础上,我们添加了对空间信息的存储和处理能力,使之成为时序时空数据库。TSDB的时空引擎让地理位置信息和时序信息完美结合起来,力争解决着一切关于时序和时空相关的查询分析。
3. 时空处理能力
最新版本的阿里云TSDB支持地理坐标位置信息的直接写入。用户只需要通过新版本的SDK以及Http Restful APIs可以将地理空间信息(地理经纬度)写入,并且可以对经纬度信息进行读取。下面两个通过Http Restful API接口TSDB多值写入和单纯的轨迹查询示例:(注意:Coordinate是一个关键字,表示地理坐标点写入,不可用于其他监控指标名称(metric)。)
说完TSDB对于地理坐标信息最基本的存储和查询功能,我们来看一下TSDB所提供的常用时空分析功能。
对于写入的地理坐标数据点,TSDB将自动生成时空索引提高查询和分析效率。TSDB的时空索引基于传统空间索引(Google S2和GeoHash都是支持)结合时序数据特征创建的时空索引格式。同时为了提高,用户可以根据自己需求在开始使用时空功能之前提前配置时空索引按照时间分片。偏实时的业务,可以将按照小时或者半小时对时空索引进行分片。对于偏分析的场景,可以按照天进行分片。
时空索引为TSDB提供时空过滤分析功能提供了便捷和提高效率,现在最新版本的TSDB支持一些常用的时空过滤功能,比如BBOX查询和DISTANCE_WITHIN查询。
目前TSDB时空功能已经在云上推出了公测版本,大家在官网就可以看到我们时空功能。
4. 下一代时空数据库核心技术全力研发中
针对万亿级,EB级别的时空数据,全团队在全力研发下一代时空数据库,包括新型分布式列式存储引擎,GPU加速,智能压缩,冷热分离,高效时空索引,分布式时空计算等等;
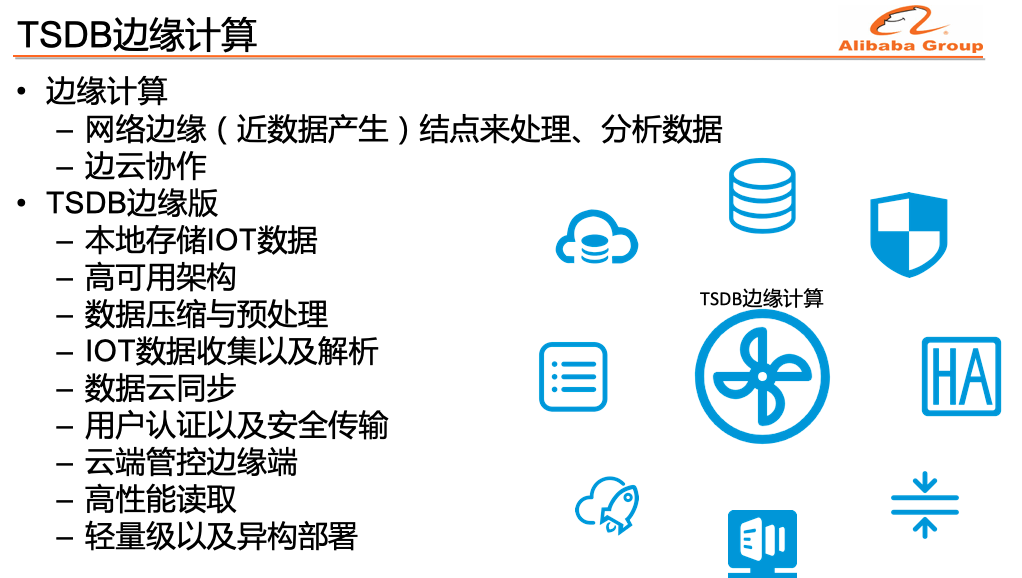
五、边缘计算
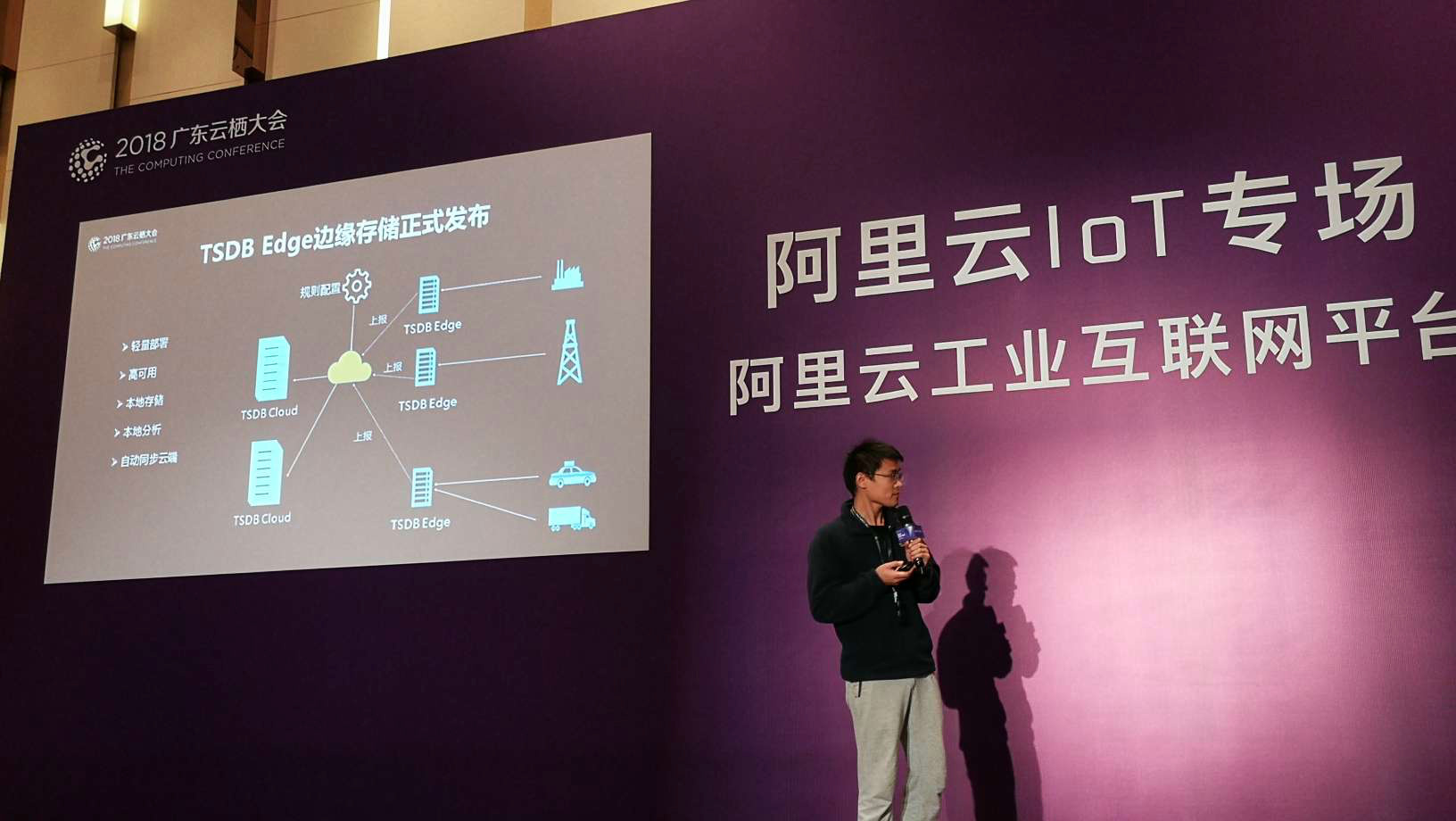
今年,为了进一步支持外部IoT市场的需求,我们在TSDB云版的基础上,开发了边缘计算版本(在广州云栖大会工业物联网专场,正式发布阿里云工业物联网边缘计算平台存储类产品 TSDB Edge,TSDB Edge 主要提供物联网边缘端设备相关数据的本地存储,本地分析,数据清洗和云端数据同步能力。);
![image.png | left | 746x421]()
![image.png | left | 746x421]()
![image.png | left | 746x423]()
1. 两节点HA
- 两节点HA通过两个TSDB节点实现HA。两个TSDB节点没有主从的区别,二者都可以接受读写请求,也都可以响应读写服务(不需要转发读写请求)。两个TSDB节点能够同时接受写请求,两个TSDB通过同步WAL日志的方式实现数据同步,保障数据的最终一致性。同时,两节点HA通过WAL与云端同步数据。
- 两节点HA提供了在边缘设备端TSDB的高可用性,当一个节点发生宕机,另外一个节点能够继续提供服务,宕机节点恢复以后,通过数据同步功能,数据能够在两个节点上迅速实现同步,不会引起非硬盘故障下的数据丢失。
2. WAL日志管理器
- 实现本地的WAL日志管理,通过WAL日志保证写入的数据不丢失。同时WAL日志管理器,自动判断并删除过期日志文件,减少硬盘空间占用,减轻运维工作。
3. 内存管理器
- 管理大对象的内存使用情况,通过监控实时内存使用情况,自动判断是否将内存中的数据写入文件系统以减少内存使用。内存管理器根据内存使用情况,自动设置保留的chunks数量,可以减少/杜绝OutOfMemoryError错误的发生。
4. HAServer/HAClient数据同步器
- HAClient通过自有的协议,采用PUSH的方式传输WAL。HAServer收到WAL以后,直接通过WAL replay数据插入操作,从而实现数据同步。HAServer/HAClient通过保存读取偏移量的方式,实现断点续传。
- CloudSynchronizer云同步器
- 通过读取WAL,并调用TSDB云版客户端实现向云端同步数据的功能。该同步器对云端透明,同时实现了断点续传。
5. 新型压缩算法
- 边缘计算提出自研的新型压缩算法,该压缩算法,采用流式压缩方式,支持数据通过append的方式加入,同时在内部采用整字节的方式进行编码,提高压缩/解压性能。
经测试,该新型压缩算法的压缩率为3-40倍。与Facebook Gorilla算法相比,该算法压缩率提高约20%-50%,压缩性能提高3-5倍,解压性能提高4-6倍。
6. GPU硬件加速
- 边缘计算还在探索与GPU等新型硬件集成。TSDB边缘版使用GPU进行解压,降采样以及聚合操作;
通过测试,使用GPU以后,查询性能可以达到原来的50倍。
六、智能引擎
背景
TSDB 提供了强大的数据存储、处理和查询能力。在这个坚实的基础之上,越来越多的业务场景需要通过挖掘海量数据驱动业务价值的提升,TSDB 智能引擎就是在这个大趋势之下应运而生的。
能力
TSDB智能引擎专注于时序时空数据的分析、检测、挖掘、预测能力,着力打造从数据到知识再到商业价值的高效引擎,争取达到价值链与数据能力的两个全覆盖。
市场上现有的商业智能与数据科学工具往往只利用数据库的存储查询功能,进行数据挖掘和分析之前需要从数据库中提数,之后的流程也脱离数据库环境进行。TSDB 智能引擎从架构上与数据库存储查询引擎进行深度整合,高效的利用数据库现有关系代数能力,并适当引入线性代数计算能力,自然的形成数据闭环,提供一站式的数据科学能力。相信随着不断地努力打造与突破,智能引擎也会逐步沉淀行业数据模型与智能定制算法,并最终形成端到端的行业智能分析解决方案。
限于篇幅,这里就不详细描述了。
八、其他
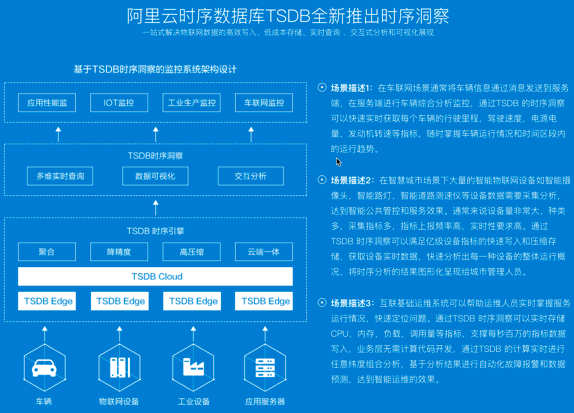
时序洞察
![image.png | left | 574x413]()
时序标准
我们在今年8月份也是参与国家的时间序列标准的制定,并且在与其他厂商的竞争中取得优异的成绩。
![image.png | left | 386x540]()
结束语
2018年,是阿里云TSDB产品成长最快的一年;上文中提到的需要技术和能力目前只是应用在阿里巴巴集团内部的场景;未来,我们会逐步把这些能力开发给外部用户,让外部客户也能享受到阿里巴巴强大的技术实力带来的价值。
最终,我们的目标是把TSDB打造成业内领先的“智联网数据库”!
作者: 焦先
原文链接
本文为云栖社区原创内容,未经允许不得转载。