背景知识
在开始阐述Aries是什么之前,需要先交代几个常识性的概念,作为引出Aries的铺垫。
数据库体系结构
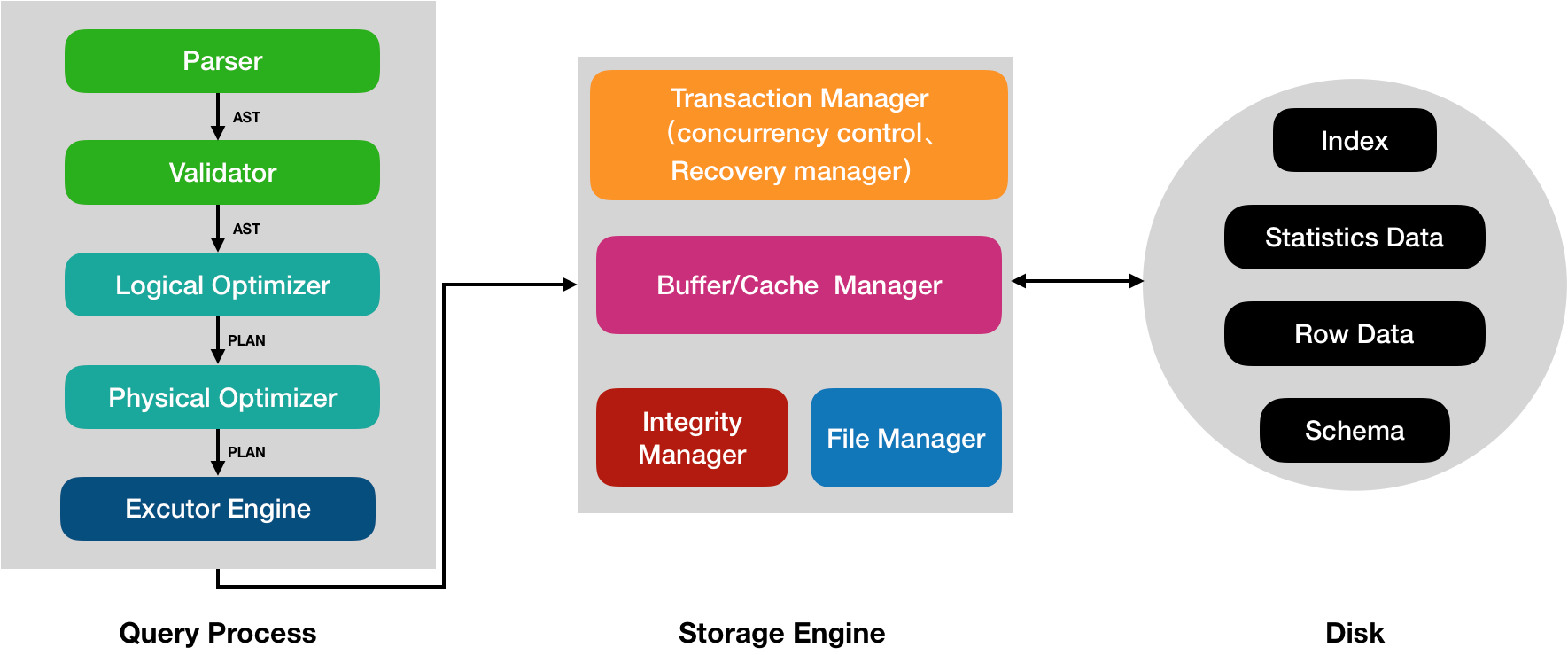
图1大致描述了一个(分布式)数据库应该包含的组件,其中箭头方向大致描述了一个请求被处理的顺序。一个请求(以DML为例),会先经过Query Process层进行解析、优化处理,最终生成物理执行计划(就是用具体的算法替换逻辑计划里的各个算子),交由执行引擎Excutor Engine进行处理。接下来就是数据库最核心的部分了,Storage Engine存储引擎接收Excutor Engine发来的命令,执行实际的数据存取操作,Storage Engine会决定数据的物理组织形式、索引的类型等,Storage Engine中较为重要的几个模块有:Buffer/Cache Manager负责管理从磁盘加载哪些数据、哪些数据应该被缓存在内存中;File Manager用于管理磁盘空间的分配和决定数据在磁盘上存储的物理数据结构(索引的存储结构、行数据的存储结构等);Integrity Manager负责对数据进程完整性检查;Transaction Manager负责事务的管理,主要包含事务的并发控制(Concurrency Control)和故障恢复(Crash Recovery)。最终,存储在磁盘上的数据包含行数据、索引数据、统计数据和schema数据等。
![]()
图1 数据库系统结构
当然,数据库种类、功能繁多,无论是单机的还是分布式的,因此上图只是罗列出一些通用、基本的组件,生产中的数据库会在此基础上添加更多的模块,比如复制、备份、管控等。
事务
介绍完数据库的体系结构,接下来再回顾下数据库事务中常见的一些概念。2PC(两阶段提交)是大家耳熟能详的词汇了,和它类似的还有一个2PL(两阶段锁),那它们是什么关系呢?如果再加上MVCC呢?接下来,本文就对它们做一下简单的对比和介绍。
2PC是一种分布式事务的提交算法 ,其主要目的是为了保证分布式事务的原子性(Atomicity),即在分布式中有多节点参与的情况下,如何保证一个事务要么在所有参与节点中执行成功(事务提交),要么全部执行失败(事务回滚),虽然2PC本身有很多缺点(如协调器单点故障、参与者同步阻塞等),但是现实中它还是分布式事务的主要提交算法(当然有很多2PC的变种版本,如Percolator)。而2PL和MVCC( Snapshot Isolation是其一种实现)都是事务的并发控制算法(手段),用于保证事务的隔离性(Isolation),即所有的并行事务被以何种调度方式进行执行。我们都知道,事务是需要ACID四个属性的,前面我们只讨论了A和I,对C和D都没提及,对于C而言,在我的上一篇文章中已经解释过,本质上它不属于数据库本身的责任(区别于CAP理论中的C),因此本文不再赘述。而对于D而言,其表示持久性(Durability),意思是一个事务一旦提交成功,那么事务产生的影响必须是持久化的、稳定不变的。显然,现实环境中(特别是分布式、大规模集群环境下),机器硬件发生故障、内核崩溃和业务代码core dump是非常频繁的(后文我们统称为Crash),如何保证在任意时间点发生Crash,机器重启(包括业务进程)后数据库还能恢复到之前的一致状态(已经提交的事务执行redo保证事务的Durability,未提交的事务执行undo回滚保证事务的Atomicity),那么就是数据库中另一个重要的组件:Crash Recovery 来保证了。
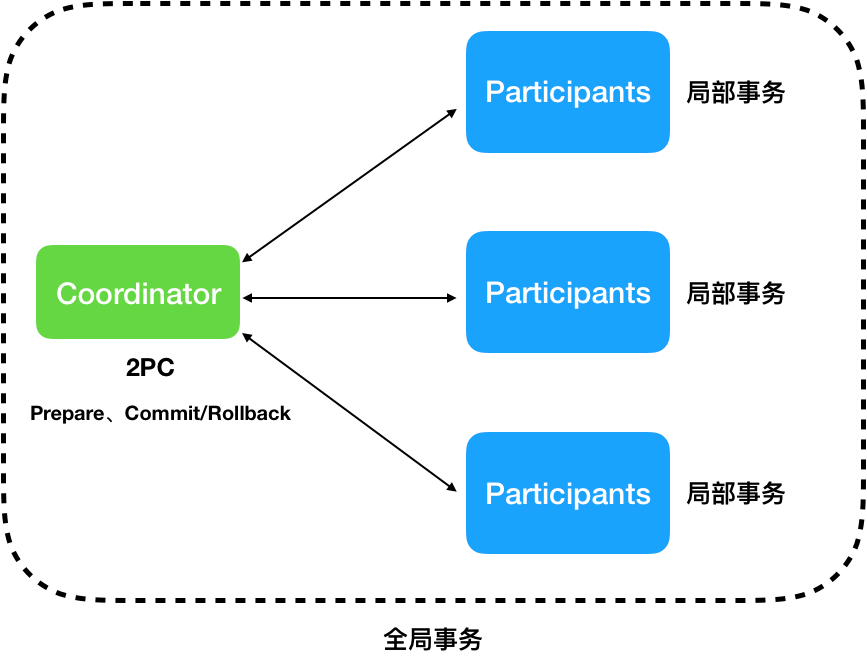
可能有人会有疑问了,既然2PC主要用来保证事务提交的Atomicity,Crash Recovery貌似也可以保证Atomicity,那么它们之间有什么关系呢?其实,2PC更多的应于在分布式事务中,这里就要区分一下了。在分布式事务中,如图2所示,通常把一个分布式事务称之为全局事务(由协调器Coordinator和参与者Participants节点组成),而在每个参与者节点上也会存在本地的事务,通常称之为局部事务。全局事务一定是建立在局部事务的基础上的,因为如果任何一个Participant上的局部事务都无法保证,那何谈全局分布式事务呢?因此,本文讲的Crash Recovery主要是用来保证局部事务的Atomicity和Durability(但是有时候其实没有必要分的非常清楚,因为一旦保证了局部事务,那么自然全局事务也就保证了)。
![]()
图2 全局事务与局部事务
steal、force、redo、undo
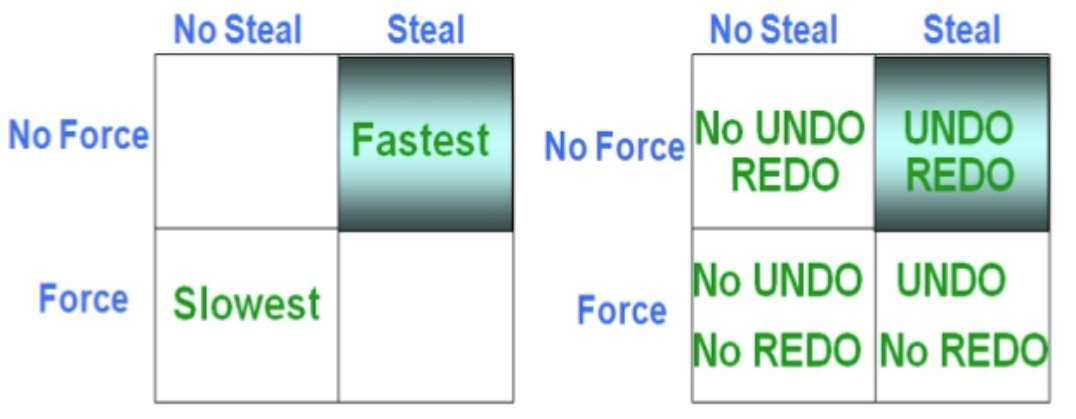
经过前文的论述,数据库中Crash Recovery模块主要用来保证(局部)事务的Atomicity和Durability。那么它是怎么做到的呢?很多人肯定都知道redo log和undo log。但是很少有人能说清楚它们的作用分别是什么?只需要redo log行不行?什么情况下两者都需要呢?其实,要搞清楚这些问题,还需要先介绍下数据库的缓存刷新策略。为了保证数据库的Atomicity和Durability,数据库会先把数据的更新记录在日志中,再写行数据(row data),最后提交。在事务提交时,日志是必须要写入稳定存储的。但是行数据呢?最理想的情况是在事务提交那一刻写入稳定存储中,这种策略称之为force刷新策略,但是这个会严重影响性能(产生很多小的磁盘随机io和写放大),因此现实中的数据库大多使用no-force策略(即事务提交的时候不会强制刷新行数据缓冲page到磁盘)。现在,行数据可以在事务提交前和提交后写入稳定存储,在事务提交前就写入磁盘的情况称之为steal策略(意思是在事务提交前,缓存中的一个行数据page被偷走了写入磁盘),相反,在事务提交前行数据绝不会写入磁盘的称之为no steal策略。明白了force/no-force和steal/no-steal策略后,就很容易理解redo log和undo log了。
设想,在事务提交之前,如果有些行数据page被steal了,如果最终事务没有执行成功需要进行回滚或着发生Crash,由于事务未提交,但是行数据已经写入了磁盘,就会造成事务出现不一致的状态。那么为了保证事物的Atomicity(即要么全部成功要么全部失败),此时需要记录undo log,以便在进行回滚操作或者Crash Recovery时,可以根据undo log对为提交的事务进行回滚。同样,如果行数据是在事务提交之后的某个时刻才被写入磁盘,那么假设事务提交后就发生了Crash(此时行数据还未写入磁盘),那么数据库的Durability就不满足了(即已提交的事务必须是Durability的,稳定不可丢失的)。因此,为了满足Durability,需要记录redo log,这样在Crash之后重启时,Recovery模块会对所有已提交的事务执行redo log,保证事务的Durability特性。图3概括了这几种情况。
![]()
图3 缓存刷新策略和log
Aries
概念引出
经过前文的论述,本文着重介绍了Crash Recovery模块的功能和原理。虽然用记录redo log个undo log可以基本满足Atomicity和Durability,但是这种机制还是存在一些问题的:
- Crash Recovery过程中需要扫描整个redo log,导致数据库恢复过程耗时太大。同时,redo log/undo log会越积越多,浪费磁盘空间,虽然可以用checkpoint来解决,但是checkpoint时刻会强制刷盘(刷日志和脏页)、禁写,导致数据库的写停顿。
- redo log和undo log都是物理的日志(physical log),这在某些情况下是有问题的。考虑修改索引B+树的例子。一个事务T1向B+树插入了一个key,假设最终这个key被插入到了page1这个叶子节点上(插入过程中加上排他锁),为了保证Atomicity,T1会先把page1上的老数据先记到undo log中。T1插入完成后(但是还未提交),会释放page1上的锁(为了提交性能),假设此时另一个事务T2也插入了一个key到page1中(因为page1上没有锁,所以可以插入成功,当然这个过程中也会记录undo log),并且成功提交事务。然后,T1由于某些原因需要回滚(正常回滚或Crash之后的回滚),因此T1直接用它记录的undo log灰度page1的内容,可以看到,此时page1中已经不包含T1成功提交写入的key了,这显然是不对的。要正确的解决这个问题,只能使用逻辑undo(logical undo),即在T1的undo log中不是记录page1的原始内容,而是记录一条删除key的B+树语句,这样在undo过程中就不会影响其他事物的写入了。
而Aries也是一种基于WAL(write ahead log)的Recovery算法,和一般的传统算法相比,Aries允许更细粒度的锁(比如B+索引中允许行级封锁而不是页级封锁)、更快的Recovery时间、支持物理逻辑日志(Physiological log)和Fuzzy checkpoints(不会停顿事务)等。Aries还拥有很多优点,当然,这也是以它的复杂性为代价的,因此,现实中完全使用Aries算法的数据库不是太多,但是大多都是借鉴了它里面的思想。
Aries使用WAL预写日志来保证事务的Atomicity和Durability,WAL的刷新策略如下(steal/no-force):
- 所有的日志记录必须在它对应的行数据页被写入磁盘之前写入稳定存储(保证Atomicity)。
- 所有的日志记录必须在其所属的事务提交(commit)之前写入稳定存储(保证Durability)。
Aries用到的数据结构
在介绍Aries算法之前,先系统性的介绍下Aries用到的几个数据结构。
LOG:
-
LSN: Log Sequence Number,一个本地单调递增的序号,唯一的标识一条log record
-
PreLSN: 属于同一个事务的log record,和面的log record会使用PreLSN指向前一条log record,组成逻辑上的单链表
-
XID: 事务的id
-
Type: log record的类型,目前主要有Update、Commit、Abort、End (signifies end of commit or abort)、Compensation Log Records (CLRs)、CheckPoint(begin_checkpoint、end_checkpoint)。
-
PageID: 唯一的表示一个Page
-
Length: Page的长度
-
Offset: Page在磁盘的位置、偏移
-
BeforeImage:修改前的值,等价于undo log
-
AfterImage:修改后的值,等价于redo log
-
undoNextLSN:只有CLR类型的log会使用这个字段,用于防止重复undo
Transaction Table :
- XID: 事务的id
- Statius:事务的状态,主要有running、commited、aborted
- LastLSN:该事务的最后一条log record序号
Dirty Page Table :
- PageID: 唯一的表示一个Page
- RecLSN:第一个导致该Page变脏(Dirty)的log record序号
Checkpoint:
Aries的checkpoint log record主要包含以下内容:
- Transaction Table:执行Checkpoint时刻对应的Transaction Table
- Dirty Page Table:执行Checkpoint时刻对应的Transaction Table
Aries的checkpoint和传统意义上的checkpoint不太一样。Aries使用fuzzy checkpoint,也就是在执行checkpoint的时刻,他并不要求将buffer中的脏页(Dirty Page)刷新到Disk,因此也就不会造成其它事务的停顿,提升性能明显。因此它就需要记录此时的Transaction Table和Dirty Page Table,以便在执行Recovery时可以获取当时的事务运行状态,并加速Recovery。因此,通常数据库中都会有一个后台任务周期性的对脏页进行flush,这样可以缩短Recovery的时间。
![]()
DB:
- PageID: 唯一的表示一个Page
- pageLSN:该page上对应的最后一条被flush到stable storage上的log record序号
Matser record:
为了更直观的表达它们之间的关系,我特意按照它们的存储位置不同画了图4。
![]()
图4 Aries算法数据结构关系图
Aries Recovery算法
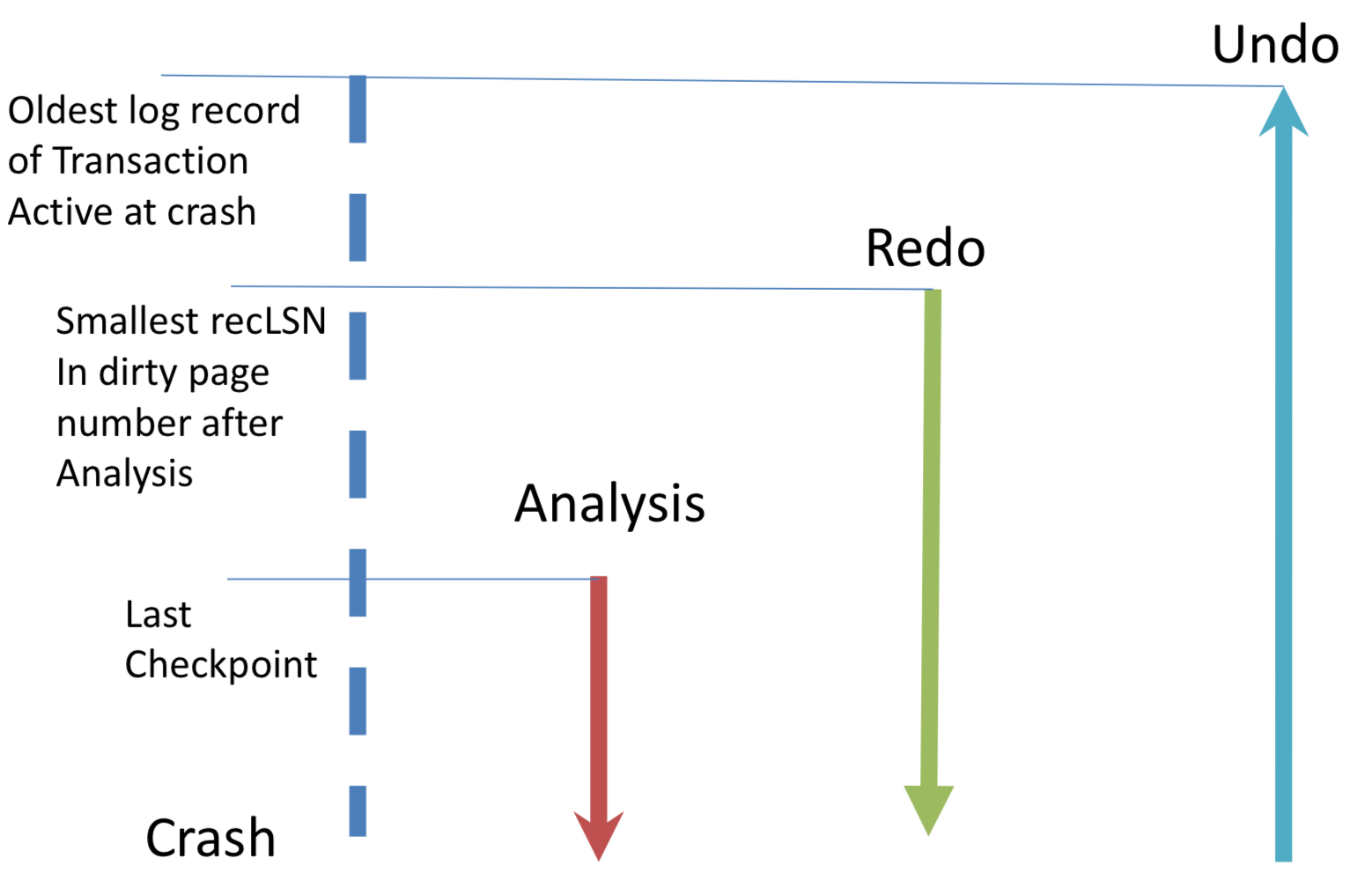
Aries的Recovery主要会分为三个阶段进行:
- Analysis阶段:该阶段会先使用最后一次的checkpoint(更确切的说是用end_checkpoint record log,可以通过master record找到)来恢复状态(就是恢复Transaction Table和Dirty Page Table)。从begin_checkpoint log record开始,正向(forward)扫描,如果遇到end log record,那么就把改log record对应的事务从Transaction Table中删除。对于其他类型的log record,就把该log record对应的事务加入到Transaction Table中,并把LastLSN设置为改log record的LSN,status设置为U(表示update),如果是commit log record,则把改为C(表示commit)。同时,如果这是一个update log record,并且该log record更新的Page没有在Dirty Page Table中,就把该Page加入到Dirty Page Table,并将RecLSN设置为该log record的LSN。在Analysis阶段结束时,Transaction Table中包含了在Crash发生那一刻所有正在运行(active)的事务。Dirty Page Table中包含了一些可能还没有被flush到磁盘的脏页(dirty page)。
- Redo阶段:该阶段会使用Analysis阶段产生的信息来重演历史(repeat History),以求可以将数据库恢复到Crash时的一致性状态。根据Analysis阶段恢复的Dirty Page Table信息,找出最小的recLSN,并从该recLSN对应的log record开始正向(forward)扫描,对每一个update和CLR类型的log record,重做(redo)该log record的动作(Action),即使这个事务之前已经abort了 。以下有两种情况会导致一个log record不会被redo,一是被该log record影响的Page不在Dirty Page Table中,二是被影响的Page对应的pageLSN(可以从磁盘读取)已经大于等于该log record的的LSN。这里还有一个可以优化的地方,就是如果此时该Page对应的RecLSN大于该log record的LSN,那么该log也不用执行redo操作。每当成功将一个log record应用到磁盘上的Page后,就更新Page的pageLSN更新为这条log record的LSN。注意,这个阶段的redo操作仍然是不要求force flush磁盘的。在redo的最后阶段,会为status为C的事务写一个end log record,并将其从Transaction Table中删除。
- Undo阶段:经过Analysis和Redo阶段处理后,所有需要Undo的事务都被记录在了Transaction Table中(包括了Crash时正在运行或者回滚的事务,将此类事务称为loser)。假设ToUndo是一个集合,里面包含了此时Transaction Table中所有事务的lastLSN,接下来会将进入一个循环,该循环里,首先会从ToUndo里面取出最大的那个lastLSN(并将其从ToUndo中移除),如果这个LSN对应的log record是CLR并且undonextLSN==NULL,就为这个事务写一个end log record。否则,如果是一个CLR log record并且undonextLSN!=NULL,那么就将undonextLSN加入到ToUndo中。如果log record不是CLR,而是一个update,就对这个update执行undo操作,并写一个CLR log record,同时会将该update log record的prevLSN加入ToUndo中。至此,如果ToUndo不为空,就返回到循环的开始。直到ToUndo为空,循环结束。这路需要注意,CLR类似的log是绝不对不会重复执行Undo的,通过这种方式可以保证Undo只执行一次(幂等性保证),因此即使在undo过程中即使再次发生Crash,系统也可以正常Recovery。
整个过程如图5所示。
![]()
图5 Recovery的三个阶段
Aries 核心思想
- WAL(write ahead log)采用steal/no-force缓冲管理策略
-
fuzzy checkpoints,不需要force flush dirty page,不会停顿事务,相当于持有checkpoint时事务状态的一个快照
-
可以从最早的dirty page进行redo任何log。对loser事务进行undo,Aries会有机制保持redo和undo的幂等性
-
CLR的加入是为了防止在undo的过程中再次发生Crash,用来保证undo的幂等性
-
采用Physiological redo log和Logical undo log,支持嵌套的顶层动作。这里的Physical log表示Log记录的是Bit的变化,而Logical log记录的是触发变化的operation和arguments。它们之间的其他区别本文不再赘述。
Aries Example
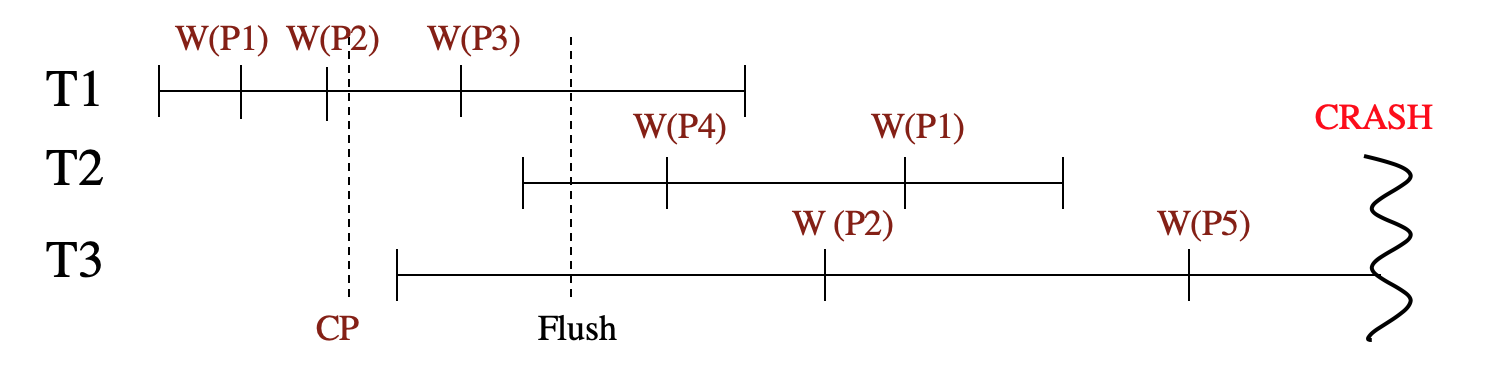
图6为例,一共三个事务T1、T2、T3同时运行,W(PX)表示事务对页PX进行写操作(具体写入了什么值此处可以不用考虑)。CP表示checkpoint,图1中可以看到,在T1对P2执行了写操作之后,系统执行了一次CP。在T1的W(P3)和T2的W(P4)之间,有一次脏页的flush。最后,在T3执行完W(P5)之后,系统Crash。
![]()
图6 实例中的事务运行图
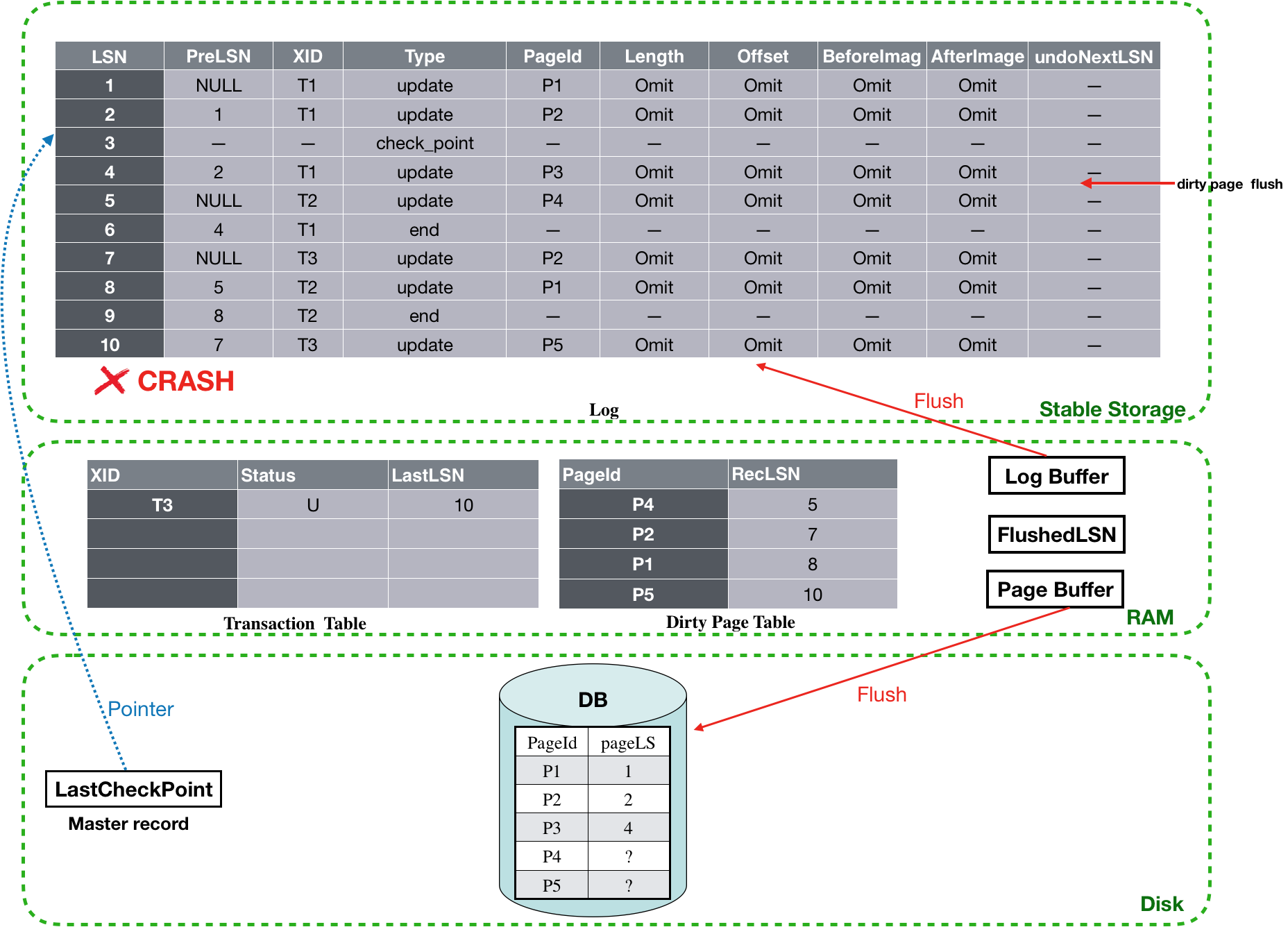
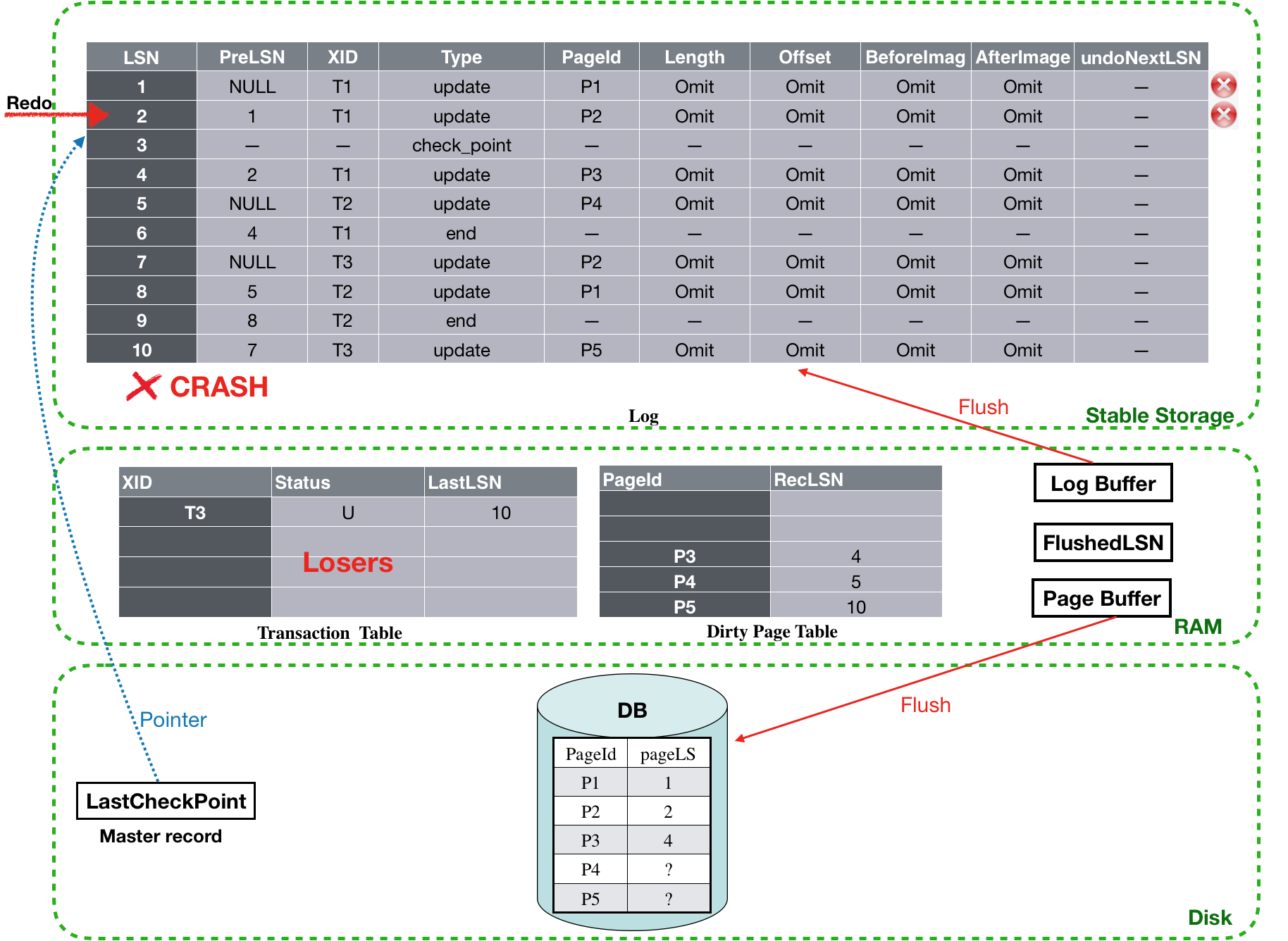
Crash时刻,Aries的数据结构的视图如图7所示。
![]()
图7 Crash时刻视图
假设系统稍后restart,会进入Aries的三个阶段。
Analysis阶段:
首先,根据存储在磁盘上的master record找到最近的checkpoint位置,此处就是LSN为3的log record。然后从LSN为4开始,forword扫描。(注意,此时的Transaction table和Dirty table是从checkpoint拿到的初始状态)
![]()
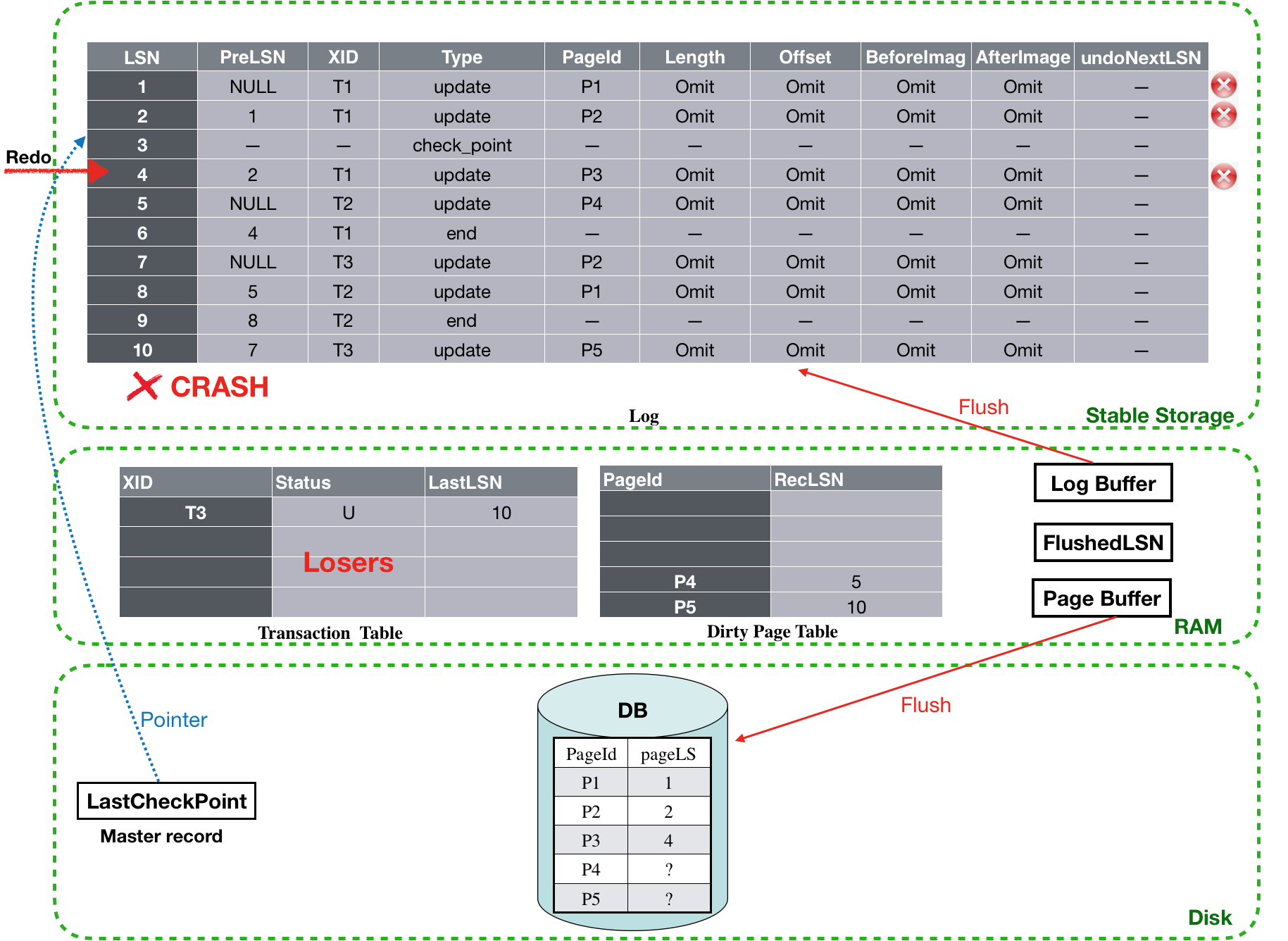
LSN为4的log是T1的update日志,将T1记录到Transaction table中。同时,由于该log是第一次更新P3,因此还需要将P3加入到Dirty table中。接下来扫描LSN为5的日志。该日志是T2的一个update记录,并且首次更新了P4。
![]()
对LSN为5的日志进行分析后,会将T2加入到Tansaction table中,并将P4加入到Dirty table中,如下图所示。接下来准备扫描LSN为6的日志,其原理和前面论述的一致。
![]()
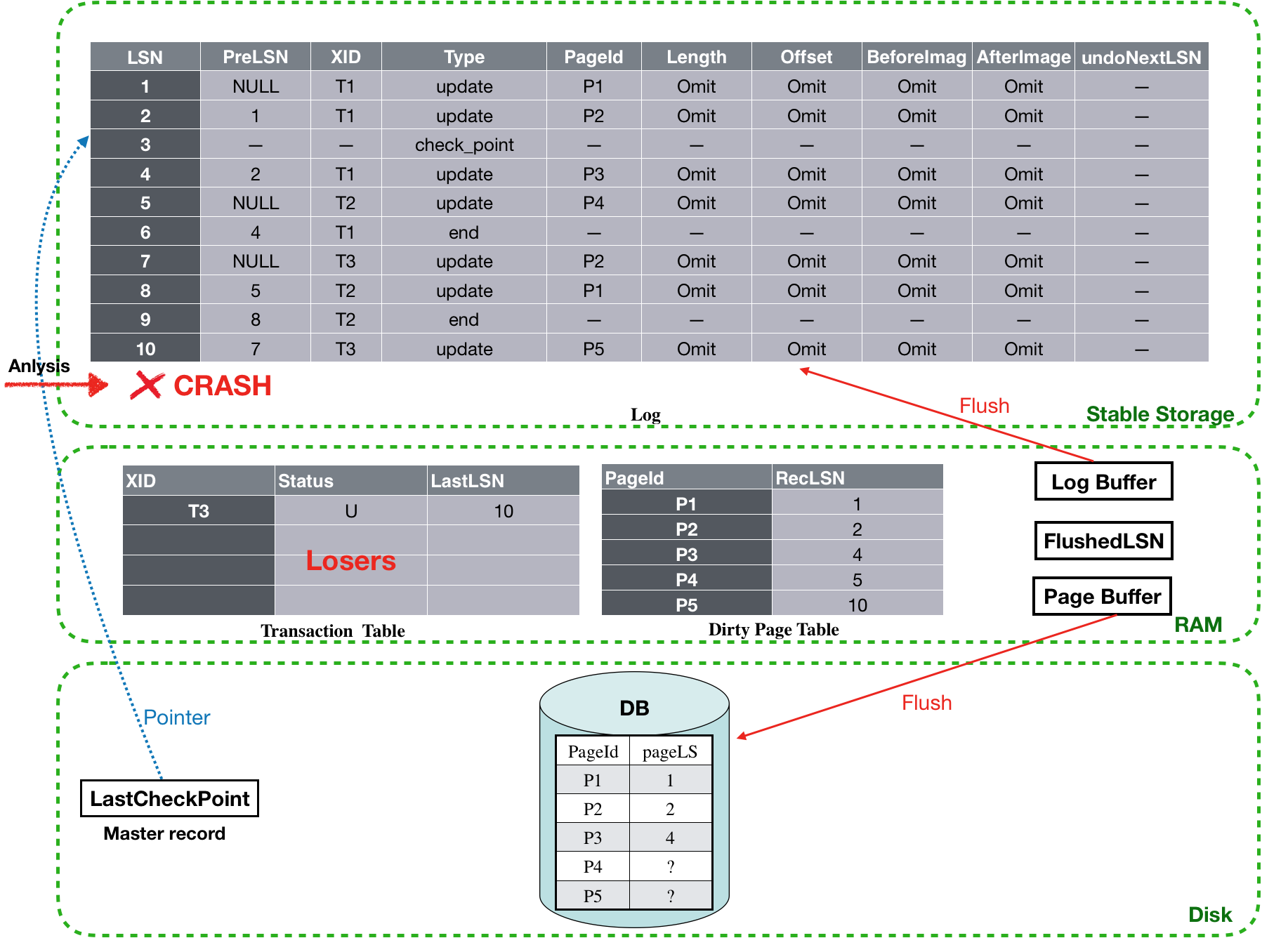
为了加快描述,本文假设分析阶段完成(已经分析完了LSN为10的日志),此时的整个系统视图如下所示。Transantion table中只剩下T3是loser,Dirty page table中有P1、P2、P3、P4和P5脏页,并分别包含了它们的recLSN(第一个导致它们变dirty的LSN)。至此,Analysis阶段完成,接下来进入redo阶段。
![]()
REDO阶段:
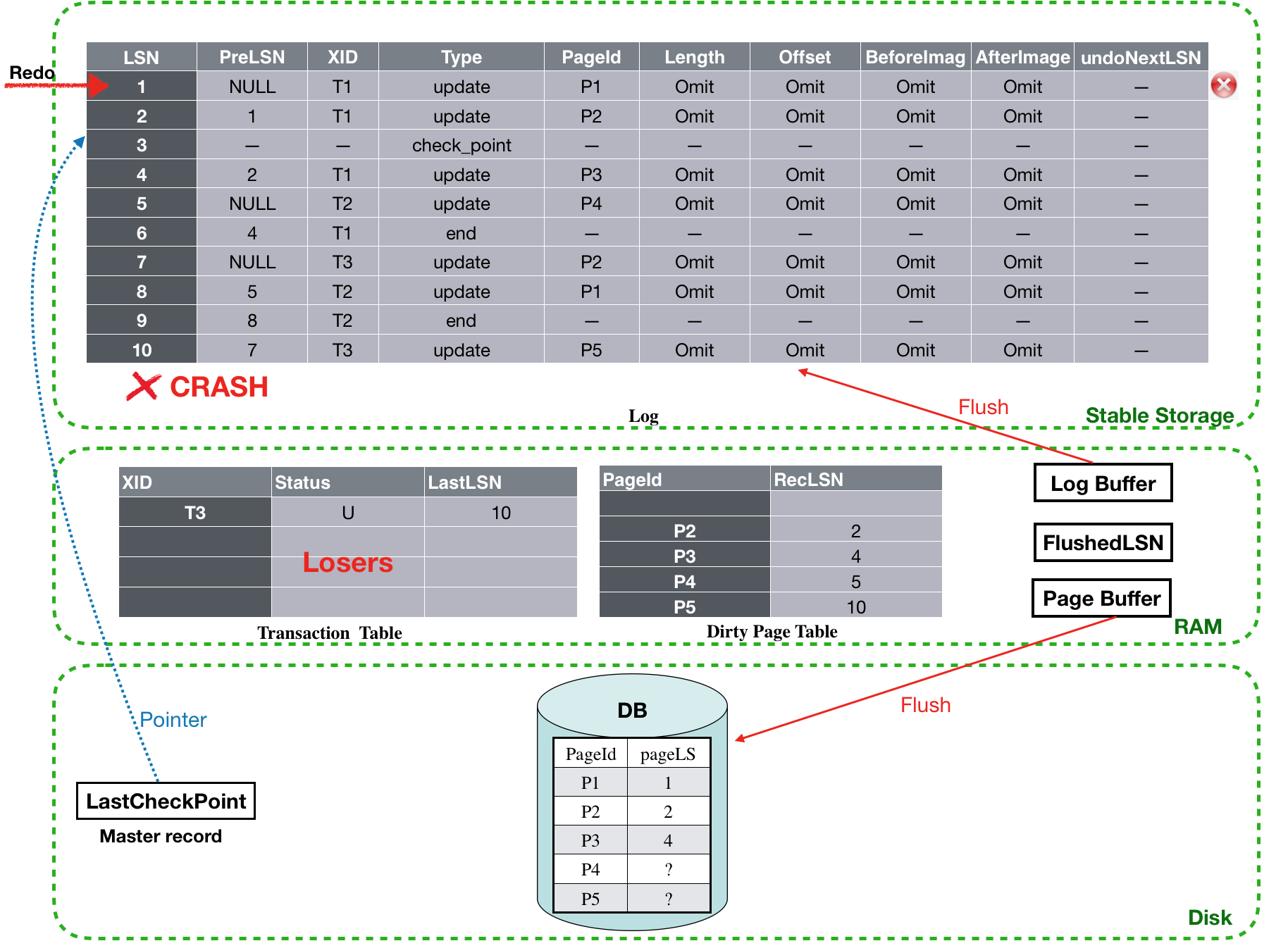
该阶段,首先会从Dirty page table中找出最小的recLSN,也就是1开始进行forword扫描。首先会对LSN为1的log进行redo action操作。由于磁盘上,P1的PageLSN为1,因此这条log之前已经被flush过了,所以该条log不用执行redo操作。
![]()
接下来要redo LSN为2的log,同样,磁盘上P2的PageLSN为2,因此该条log也不需要执行redo操作。
![]()
接下来要redo LSN为4的log(提过LSN为3的checkpoint),同样,磁盘上P3的PageLSN为2,因此该条log也不需要执行redo操作。
![]()
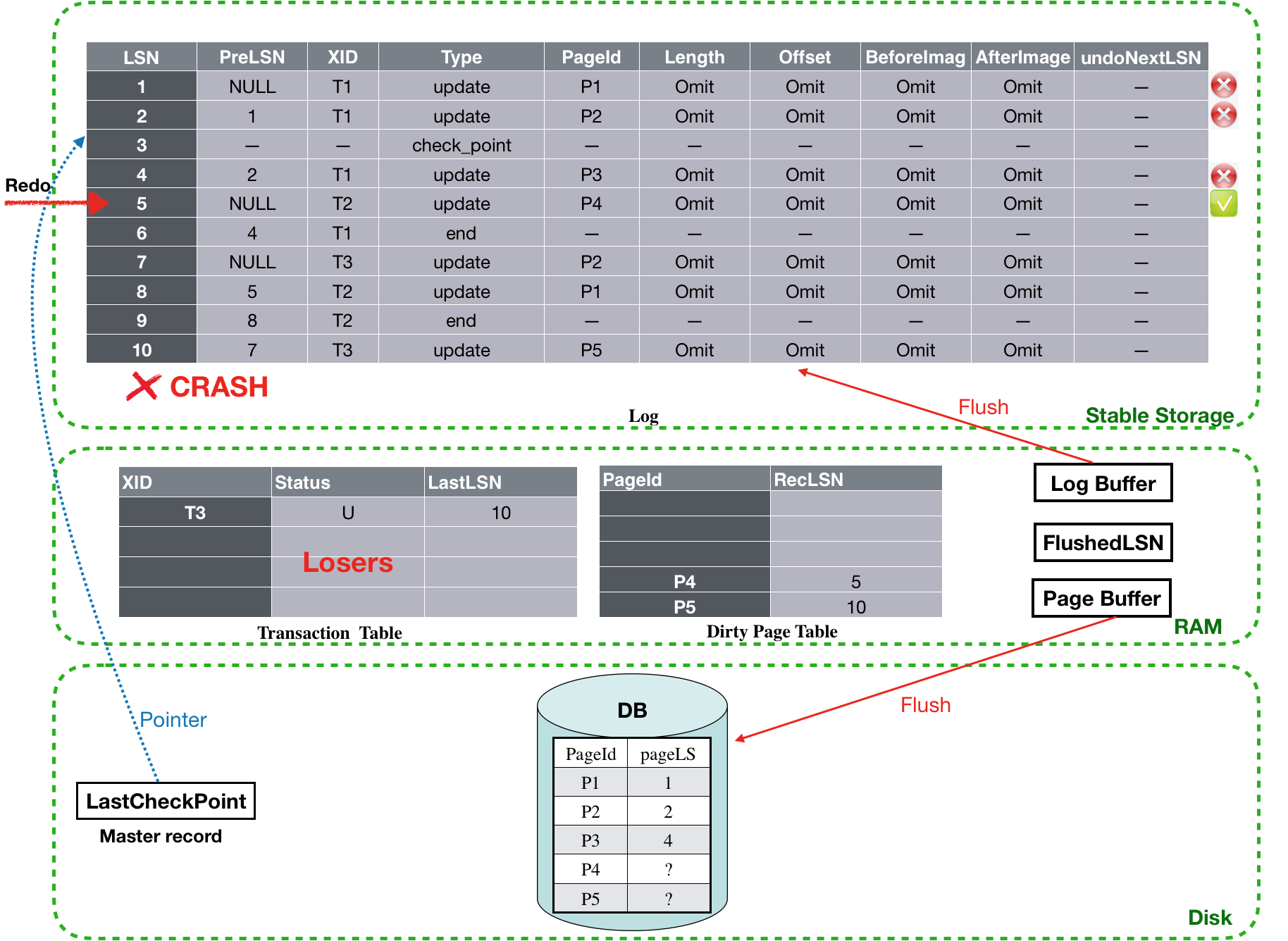
接下来要redo LSN为5的log,同样,磁盘上P4的PageLSN为NULL,因此该条log需要执行redo操作。
![]()
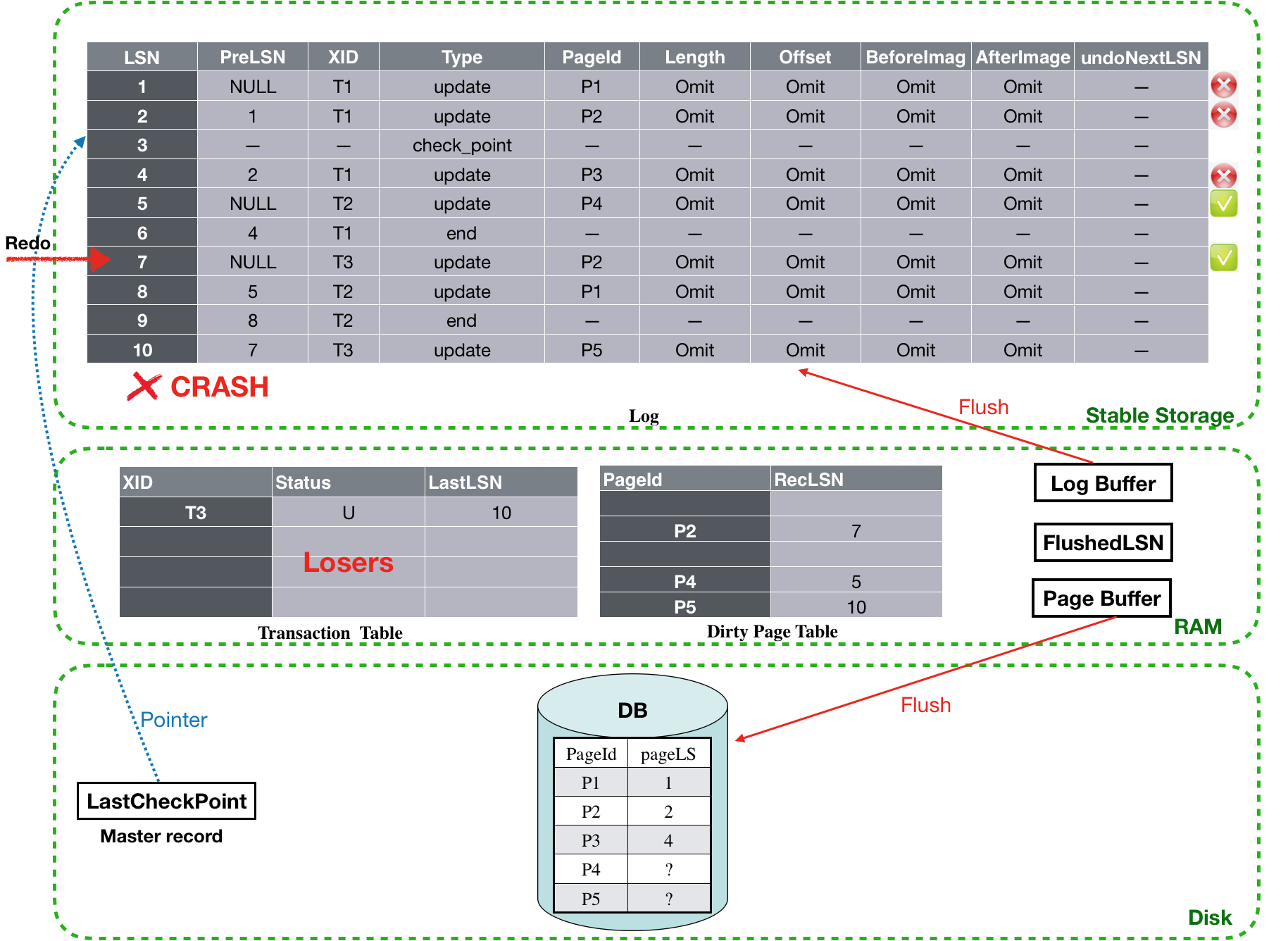
跳过T1的end log,继续redo LSN为7的log,由于磁盘上P2的PageLSN为2,因此该条log需要执行redo,同时,执行完成之后需要将P2加入到Dirty page table中,并将其recLSN设置为7。
![]()
继续redo LSN为8的log,由于磁盘上P1的PageLSN为1,因此该条log需要执行redo,同时,执行完成之后需要将P1加入到Dirty page table中,并将其recLSN设置为8。
![]()
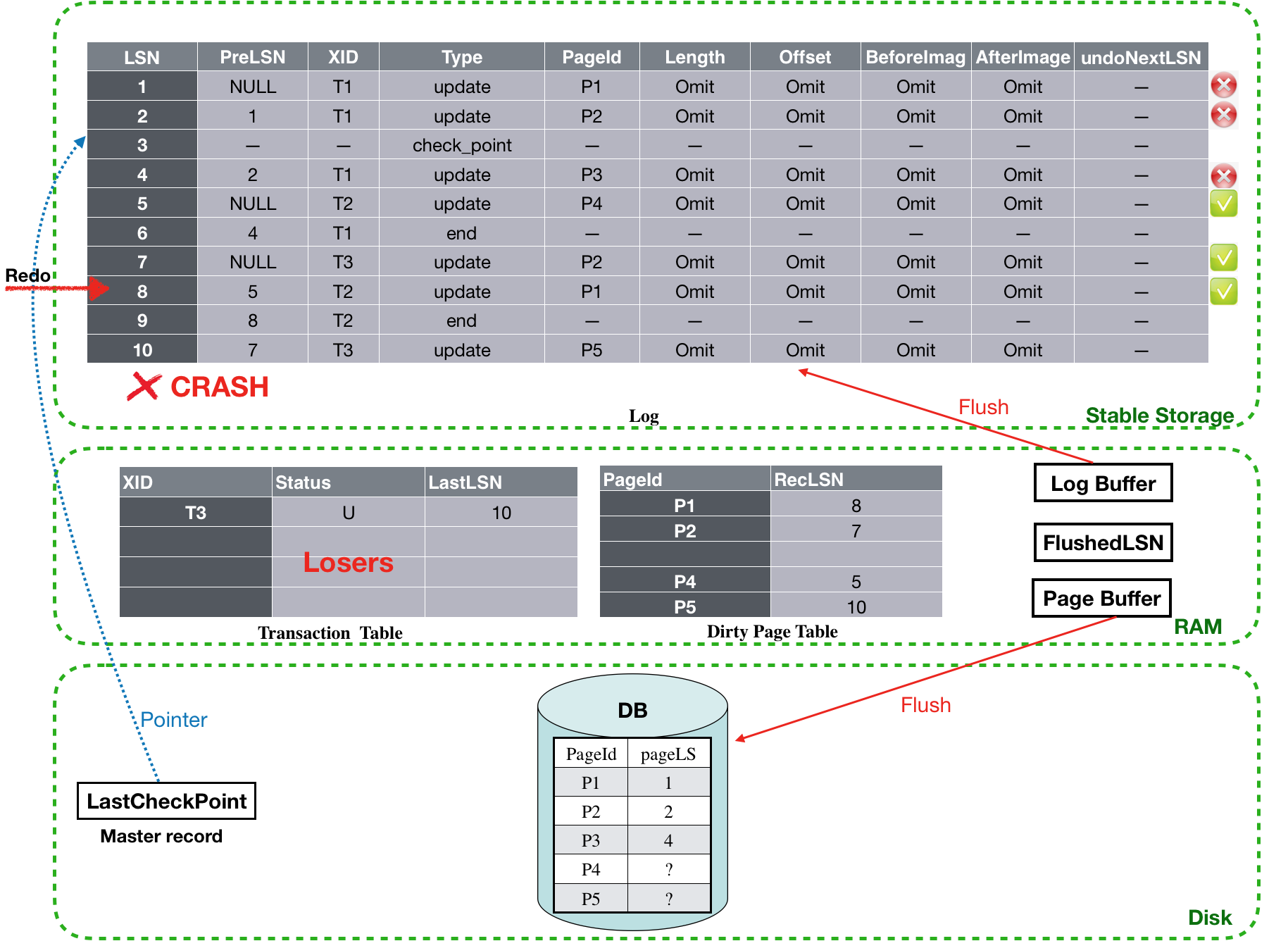
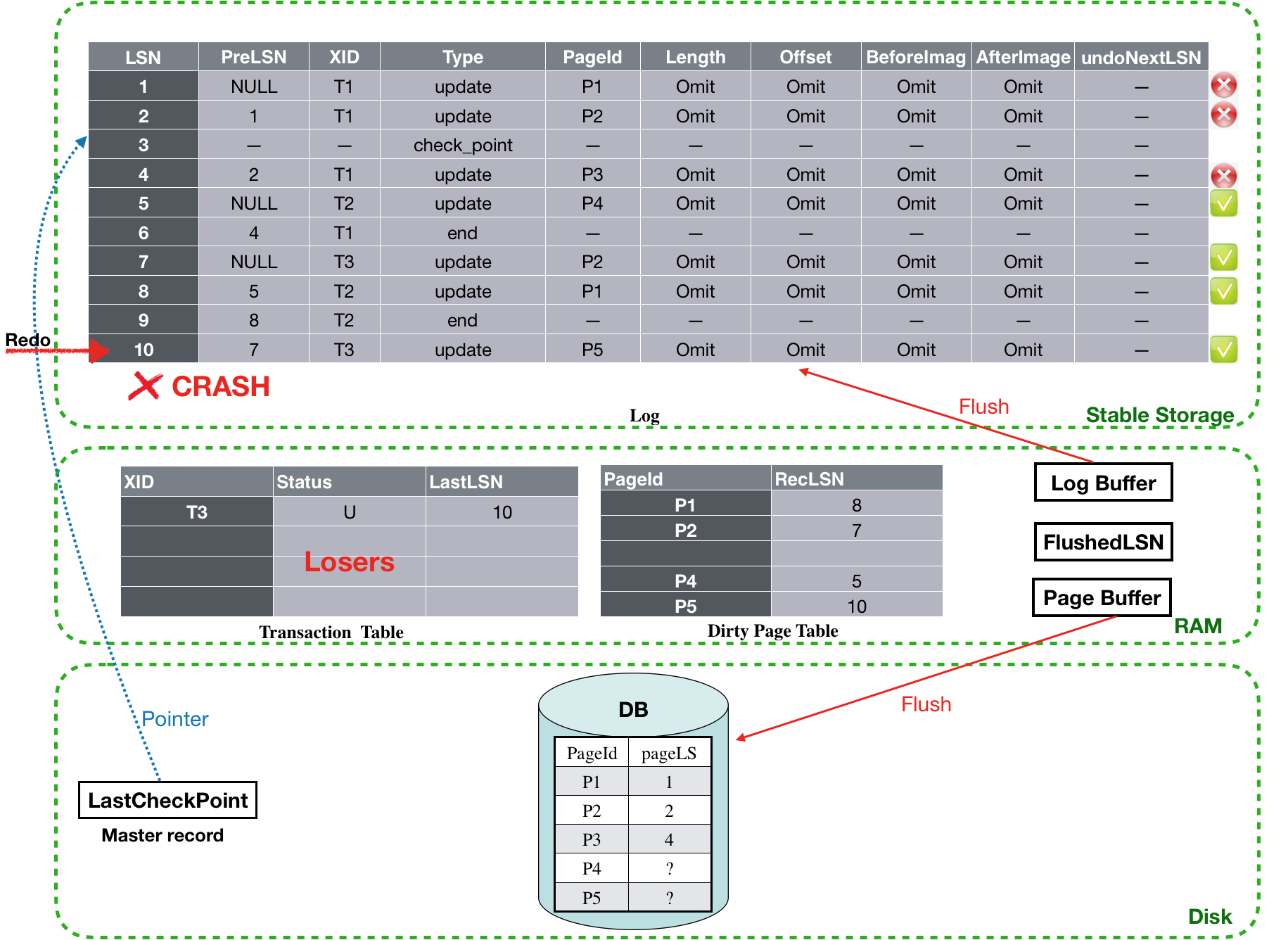
跳过LSN为9的end log,LSN为10的log是T3的update,其更新的P5此时对应的PageLSN为NULL,因此这条log需要执行redo。至此,最后一条log也redo完毕。接下来将进入undo 阶段。
![]()
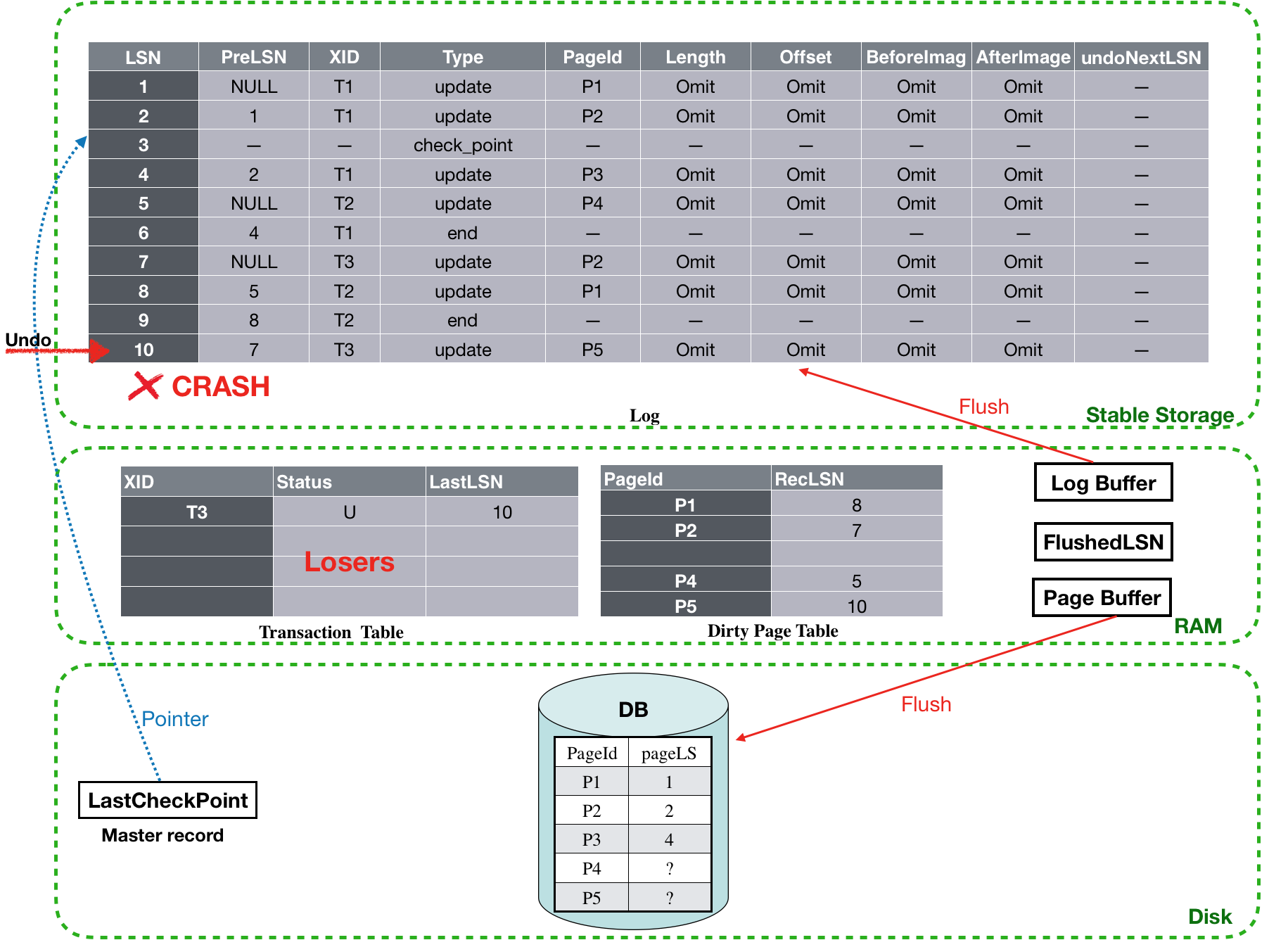
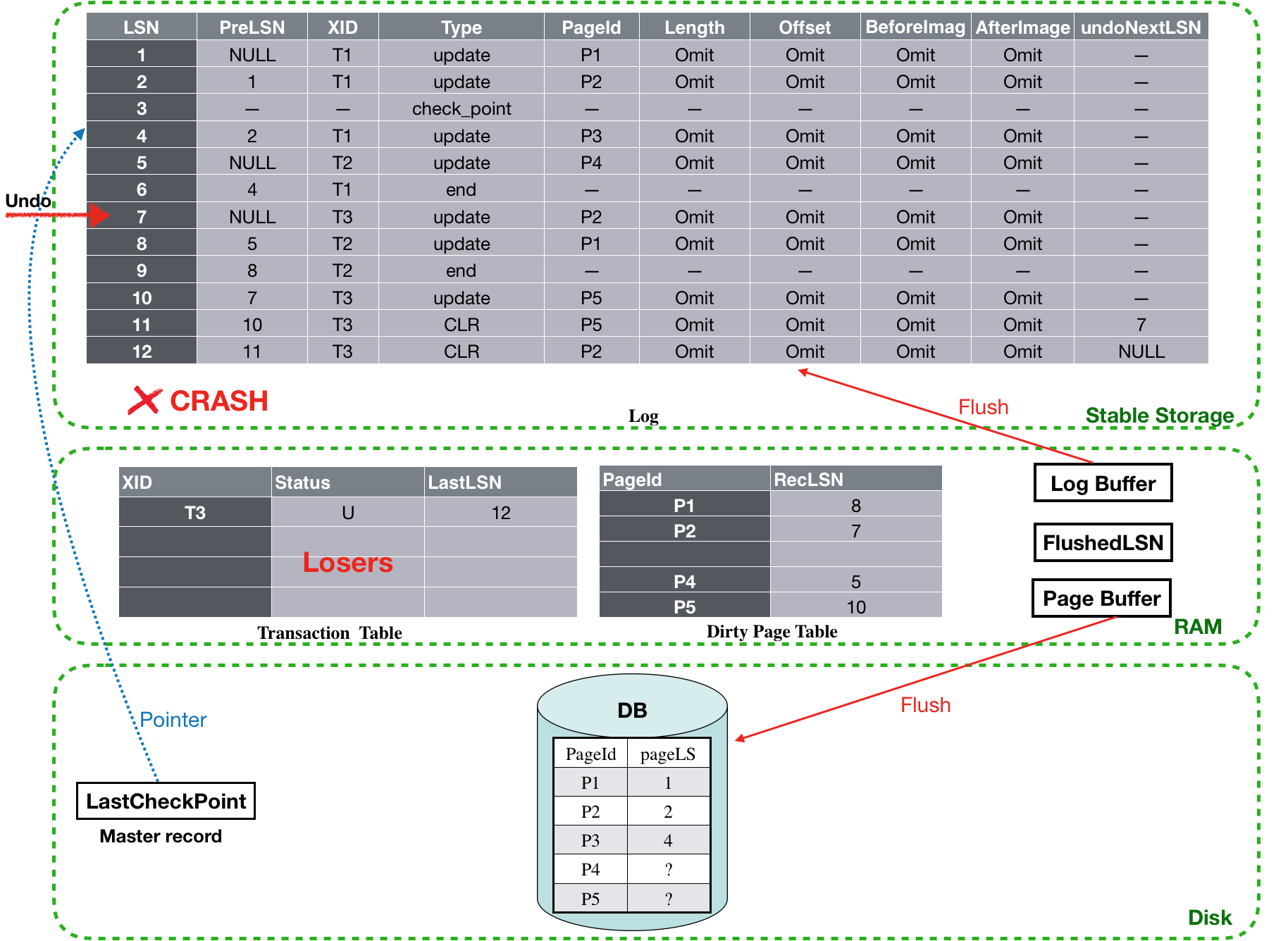
Undo阶段:
经过Analysis和Redo阶段后,现在Transaction table里面还剩T3这个loser事务,对应的LastLSN为10,根据算法,设置toUndo={10}。
![]()
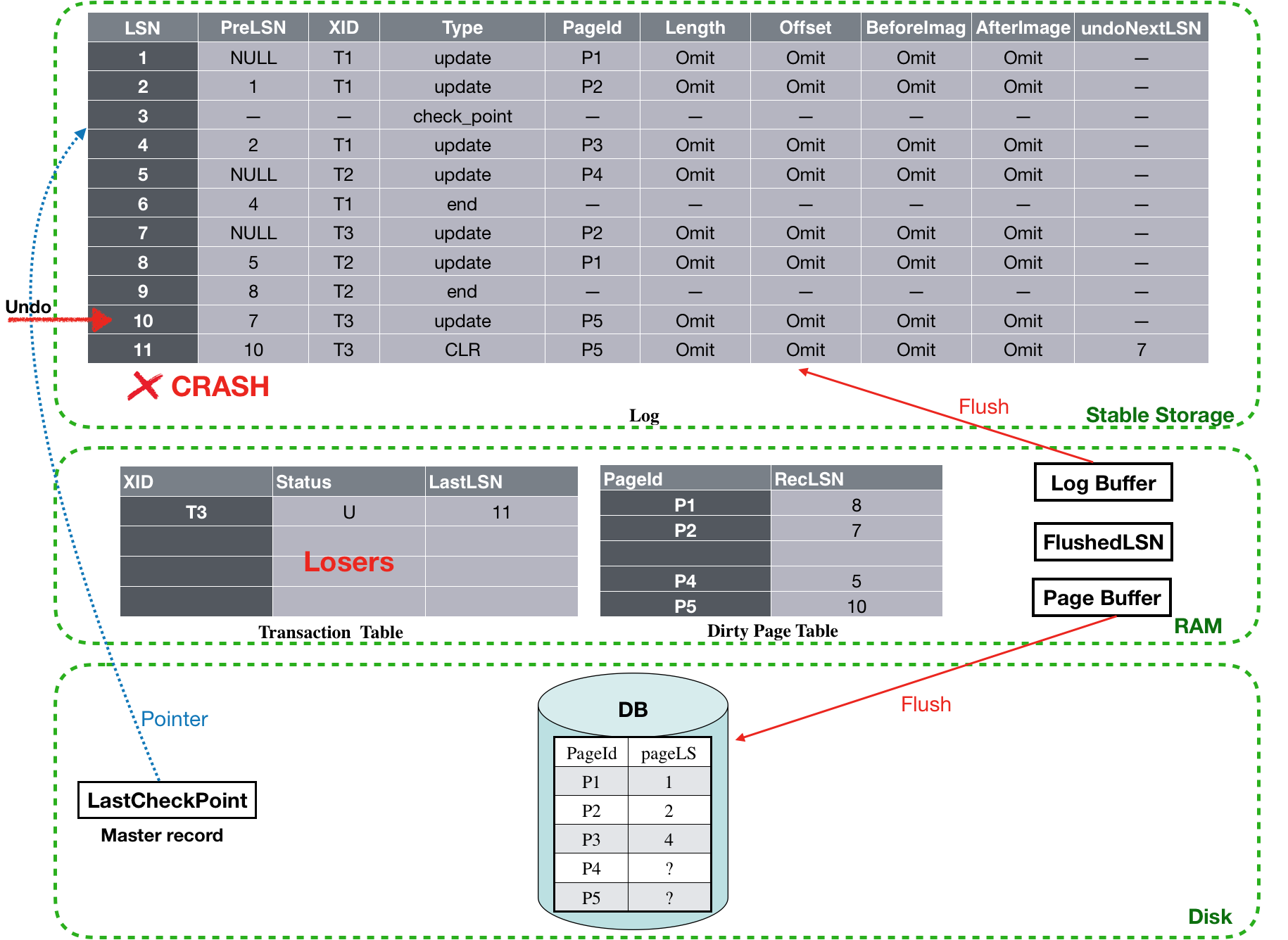
从toUndo中取出最大的那个LastLSN,也就是10, 开始对LSN为10的log执行undo,undo完成之后,还需要新写一个CLR log record(LSN为11),并将其undoNextLSN设置为7(也就是LSN为10的log对应的PreLSN)。最后再把该log的PreLSN加入到toUndo中,因此此时toUndo={7} 。然后进行下一次循环。
![]()
由于toUndo不为空,因此,依然从toUndo取出最大的LastLSN,为7, 对LSN为7的log进行undo操作,之后也会为其新写一个CLR log record。不同的是,由于LSN为7的log是事务T3的第一条log,因此它的PreLSN为NULL,因此它对应的undoNextLSN也为NULL。PreLSN为NULL,因此也就不需要再加入toUndo里了,而此时toUndo={} ,集合为空。循环结束。
![]()
对于CLR的undoNextLSN为NULL的情况 ,还会为其对应的事务写一个end log record,表示该事务已经结束。这样在下次revovery的时候就无需再次undo了。
![]()