题目:求微信群覆盖
微信有很多群,现进行如下抽象:
(1) 每个微信群由一个唯一的gid标识;
(2) 微信群内每个用户由一个唯一的uid标识;
(3) 一个用户可以加入多个群;
(4) 群可以抽象成一个由不重复uid组成的集合,例如:
g1{u1, u2, u3}
g2{u1, u4, u5}
可以看到,用户u1加入了g1与g2两个群。
画外音,注意:
gid和uid都是uint64;
集合内没有重复元素;
假设微信有M个群(M为亿级别),每个群内平均有N个用户(N为十级别).
现在要进行如下操作:
(1) 如果两个微信群中有相同的用户,则将两个微信群合并,并生成一个新微信群;
例如,上面的g1和g2就会合并成新的群:
g3{u1, u2, u3, u4, u5};
画外音:集合g1中包含u1,集合g2中包含u1,合并后的微信群g3也只包含一个u1。
(2) 不断的进行上述操作,直到剩下所有的微信群都不含相同的用户为止;
将上述操作称:求群的覆盖。
设计算法,求群的覆盖,并说明算法时间与空间复杂度。
画外音:58同城2013年校招笔试题。
对于一个复杂的问题,思路肯定是“先解决,再优化”,大部分人不是神,很难一步到位。先用一种比较“笨”的方法解决,再看“笨方法”有什么痛点,优化各个痛点,不断升级方案。
拿到这个问题,很容易想到的思路是:
(1) 先初始化M个集合,用集合来表示微信群gid与用户uid的关系;
(2) 找到哪两个(哪些)集合需要合并;
(3) 接着,进行集合的合并;
(4) 迭代步骤二和步骤三,直至所有集合都没有相同元素,算法结束;
第一步,如何初始化集合?
set这种数据结构,大家用得很多,来表示集合:
● 新建
M个set
来表示M个微信群gid
● 每个set插入
N个元素
来表示微信群中的用户uid
set有两种最常见的实现方式,一种是树型set,一种是哈希型set。
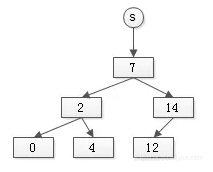
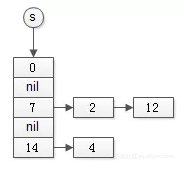
假设有集合:
s={7, 2, 0, 14, 4, 12}
树型set的实现如下:
![f3f33f7e8ee141f940b674b655737dd5de594818]()
其特点是:
● 插入和查找的平均时间复杂度是
O(lg(n))
● 能实现有序查找
● 省空间
哈希型set实现如下:
![905ee15b70c1cae852a9c02cc49c74ca734125a8]()
其特点是:
● 插入和查找的平均时间复杂度是
O(1)
不能实现有序查找
画外音:求群覆盖,哈希型实现的初始化更快,复杂度是O(M*N)。
第二步,如何判断两个(多个)集合要不要合并?
集合对set(i)和set(j),判断里面有没有重复元素,如果有,就需要合并,判重的伪代码是:
// 对set(i)和set(j)进行元素判断并合并
(1) foreach (element in set(i))
(2) if (element in set(j))
merge(set(i), set(j));
第一行(1)遍历第一个集合set(i)中的所有元素element;
画外音:这一步的时间复杂度是O(N)。
第二行(2)判断element是否在第二个集合set(j)中;
画外音:如果使用哈希型set,第二行(2)的平均时间复杂度是O(1)。
这一步的时间复杂度至少是O(N)*O(1)=O(N)。
第三步,如何合并集合?
集合对set(i)和set(j)如果需要合并,只要把一个集合中的元素插入到另一个集合中即可:
// 对set(i)和set(j)进行集合合并
merge(set(i), set(j)){
(1) foreach (element in set(i))
(2) set(j).insert(element);
}
第一行(1)遍历第一个集合set(i)中的所有元素element;
画外音:这一步的时间复杂度是O(N)。
第二行(2)把element插入到集合set(j)中;
画外音:如果使用哈希型set,第二行(2)的平均时间复杂度是O(1)。
这一步的时间复杂度至少是O(N)*O(1)=O(N)。
第四步:迭代第二步与第三步,直至结束
对于M个集合,暴力针对所有集合对,进行重复元素判断并合并,用两个for循环可以暴力解决:
(1)for(i = 1 to M)
(2) for(j= i+1 to M)
//对set(i)和set(j)进行元素判断并合并
foreach (element in set(i))
if (element in set(j))
merge(set(i), set(j));
递归调用,两个for循环,复杂度是O(M*M)。
综上,如果这么解决群覆盖的问题,时间复杂度至少是:
O(M*N) // 集合初始化的过程
+
O(M*M) // 两重for循环递归
*
O(N) // 判重
*
O(N) // 合并
画外音:实际复杂度要高于这个,随着集合的合并,集合元素会越来越多,判重和合并的成本会越来越高。
基于“先解决,再优化”的思想,很多优化方向的问题,自然而然的从脑中蹦出:
(1) 能不能快速通过元素定位集合?
画外音:
通过集合查元素,哈希型set时间复杂度是O(1);
通过元素查集合(句柄),如何来实现呢?
(2) 能不能快速进行集合合并?
(3) 能不能一次合并多个集合?
经典数据结构,分离集合(disjoint set),它有三类操作:
Make-set(a):生成一个只有一个元素a的集合;
Union(X, Y):合并两个集合X和Y;
Find-set(a):查找元素a所在集合,即通过元素找集合;
特别适合用来解决这类集合合并与查找的问题,又称为并查集。
如何利用并查集来解决求“微信群覆盖”问题,是后文将要介绍的内容。
画外音:先介绍“并查集”这一种方案,后续再介绍其他方案。
知道并查集的思路和原理,比知道什么是并查集更重要。
算法,其实还是挺有意思的。
原文发布时间为:2018-11-13
本文作者:58沈剑
本文来自云栖社区合作伙伴“架构师之路”,了解相关信息可以关注“架构师之路”。