京东大数据平台部一直致力于优化基础架构,为用户提供稳定、高可靠、高性能、高利用率的超大规模Hadoop集群。本文与大家分享大规模分布式存储集群的基石——本地存储系统优化的点点滴滴。
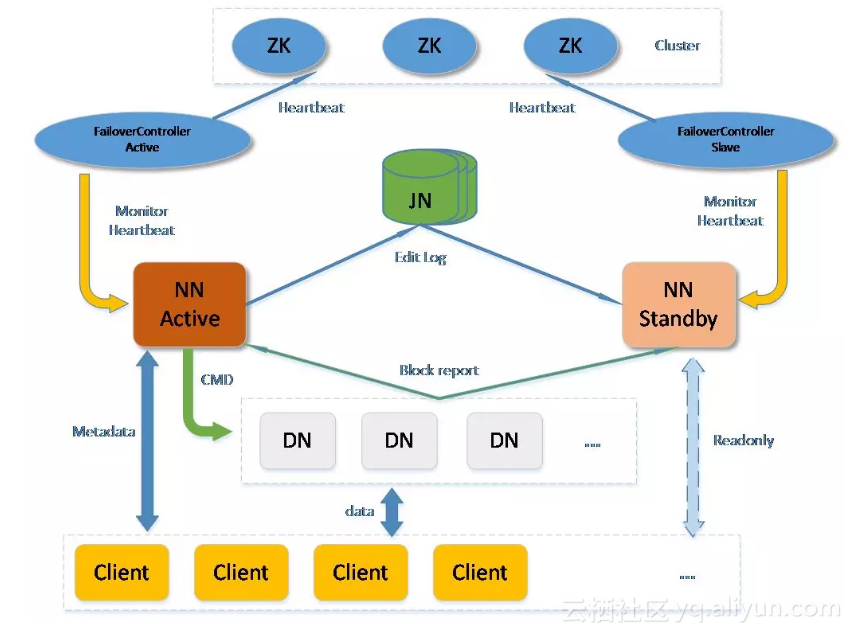
在介绍主要内容前,先熟悉一下高可用Hadoop分布式文件系统HDFS的核心架构,如下图:
![9c76e72355673cb9a4838cb742182b5d4d023006]()
HDFS将大文件切分为多个数据块(
Block
)存储到多个
DataNode
(以下简称DN)。
NameNode
(以下简称NN)主要用于储存分布式文件系统的元数据,元数据包括文件系统目录树、文件与数据块的对应关系、数据块与DN 的对应关系。NN除了存储元数据外,还需要管理大量的DN,同时要对外提供元数据的服务接口。
DN 是用于存储数据块的节点,HDFS上的所有文件的数据都存储在DN上。
HDFS上文件的访问文件数据的流程,简单来说,是
Client
先从NN获取到文件数据所在DN位置,然后与DN通信访问实际的数据。
为了保证NN的高可用,衍生出Active NN和Standby NN,依托
ZooKeeper
(以下简称ZK)实现NN的状态切换。ActiveNN对外提供服务,Standby NN在Active NN发生故障时切换为Active NN继续对外服务。
Active NN响应Client的修改元数据请求,需要记录元数据的操作日志(以下称为
EditLog
),为了提升EditLog的一致性和可靠性,HDFS设计了
JournalNode
(以下简称JN)集群,每一次元数据的修改都要同步保存到JN中。Standby NN是Active NN的后备,他从JN持续拉取EditLog,并将其合并到本地的元数据结构中,随时待命准备接收Active NN的工作。
本地存储系统优化是在分析HDFS的不同核心组件和组件之间的I/O模型的前提下,为达到高吞吐或高ops的需求,而提出针对性的优化方案。共分为四个部分:
● DN本地文件系统元数据与数据的缓存分离
,为大家介绍一种更适合单机海量存储的文件系统缓存方案
● 本地存储优化案例分析
,囊括了我们在实践中遇到的几个经典案例
● 本地存储系统性能实时监控
,工欲善其事必先利其器,只有iostat是不够的
● 磁盘故障监控与自动化运维
DN本地文件系统元数据与数据的缓存分离
本地存储架构
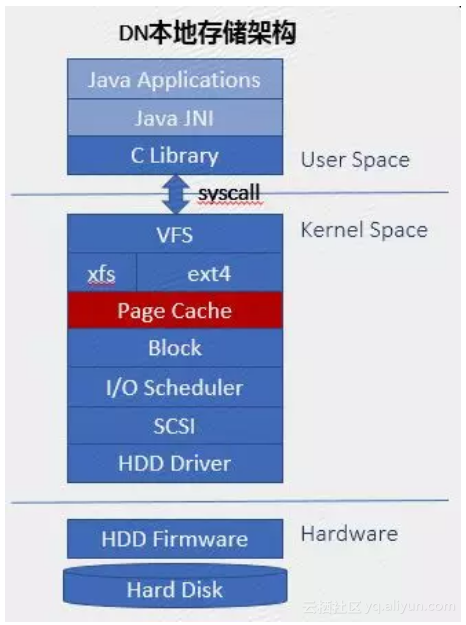
在介绍缓存分离的方案之前,以传统机械硬盘为例,大致介绍本地存储系统的架构,如下图:
![a716bfc1a30f663bf3225bdea0a9cb57a4bc4e91]()
Java应用程序,通过文件相关接口调用Java Native Interface(图中简称JNI),再调用C Library暴露的系统调用接口,触发软中断嵌入到Kernel Space,由Kernel代替应用程序进程执行VFS相应的系统调用处理函数;VFS是虚拟文件系统,是不同类型文件系统的抽象,我们常用的文件系统如Ext4、xfs等。为了加速文件系统的性能,Linux提供了Page Cache机制,这也是本部分的主角了。
再之下是block层,我们看到的磁盘比如/dev/sda,就是block层呈现的;大家耳熟能详的电梯调度算法,就是各类I/O Scheduler的鼻祖。我们听说过的硬盘接口比如SATA、SAS等都受SCSI框架的统一管理,不同的厂商向Kernel社区贡献了自有的磁盘驱动。Hardware只需了解一些特性。
言归正传,本节的主角是Page Cache。
PageCache
相信很多人会有这样的经历,在定位紧急问题时打开一个很大的日志文件往往是一个漫长的过程,很是让人着急;但是在第二次打开时基本是秒开。这要归功于Linux kernel提供的Page Cache机制。
Page Cache一般又分为两部分:Buffer缓存文件元数据,Cache缓存文件数据。此处的元数据是一个统称,包括了文件系统的元数据、文件的索引节点inode、目录项Dentry等。inode保存了文件长度、属主、创建日期等关键信息,但不包括文件名。目录是一种特殊的文件,其内容即为Dentry,用来保存目录内的子目录和文件inode与文件名称对应关系。访问一个文件是一个很耗时的过程,涉及到多次从磁盘读取元数据和数据。
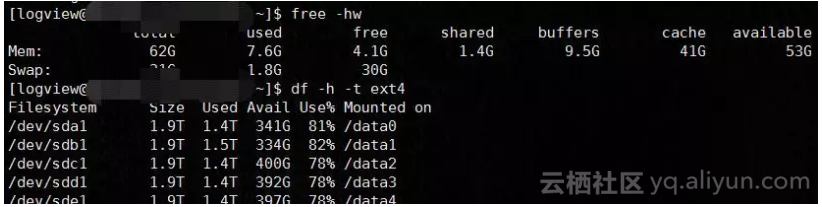
从下图中我们可以看出,Buffer和Cache总共占用约50G内存,正符合Linux的一个设计原则:你用或者不用,它都在那里,不用白不用。在应用需要这部分内存空间时,Page Cache会根据精心设计的内存回收算法释放内存页。
![4a06abdac0bac1674dde632482117bf7184d6b20]()
技术痛点
在超大规模集群中,单个DN多则承担千万个Block,在这样的极端场景下,Buffer和Cache的加速效果越来越差。主要原因是内存太小,磁盘嫌少。从容量比来看,内存几十GB/元数据总量几十GB/数据总量几十TB,内存大小和数据总量对比约为1:1000,在多租户随机读写情况下,数据热度极度分散,Page Cache的命中率比较低。
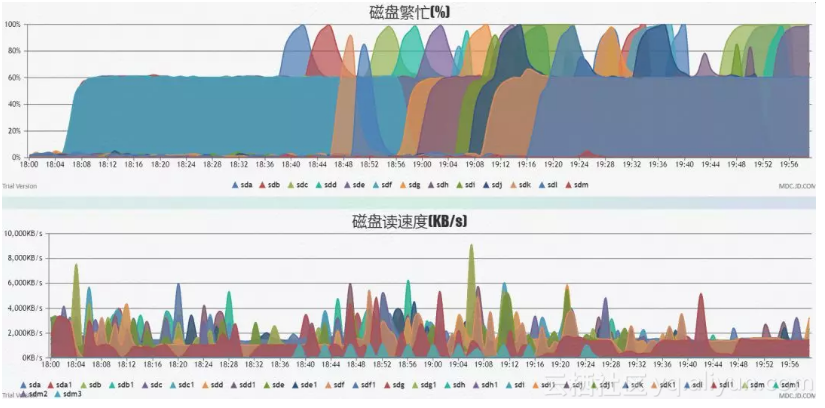
再加上DataNode的扫盘/错误检查/du等操作需要访问千万级文件和目录的元数据,元数据多数为小块I/O,常见的是4KiB,大部分元数据因无法命中Buffer而需要从磁盘读取,抢占磁盘IOPS,严重影响DN对外服务。再加上文件系统元数据和数据一般非连续存储,因此元数据读写加剧了磁头的抖动,破坏了数据读写的连续性,最终导致磁盘吞吐远低于预期。从下图中,可以看出磁盘繁忙度持续在100%,本来有100+MB/s带宽的硬盘实际上只发挥出不足4MB/S。
![f49fe2edb0c22bf572cb5853ca4d53dd323aa180]()
那如何来缓解这样的问题呢,我们最初想到将元数据和数据从物理上分离开,即把元数据放到更快更强的非易失闪存,但是业界还没有足够成熟稳定的开源文件系统,因为文件系统是数据的根基,要十分谨慎小心。后来我们注意到内存容量和元数据总量旗鼓相当,那么我们能不能用Page Cache尽可能多的缓存元数据,这样我们不会触及文件系统的任何修改,应用也无感知。
Linux Kernel并不提供机制让系统管理员来控制Buffer和Cache的比例,而且前面的示例中也体现出Buffer和Cache的差距,那么想要达到尽可能多的缓存元数据的目的,只能从Page Cache的原理入手,修改Buffer和Cache的机制。
Cache与Buffer实际上共用File LRU链表,使用相同的内存回收策略。这也是为什么Buffer总是比Cache小很多的原因,因为抢不过嘛。
优化方案
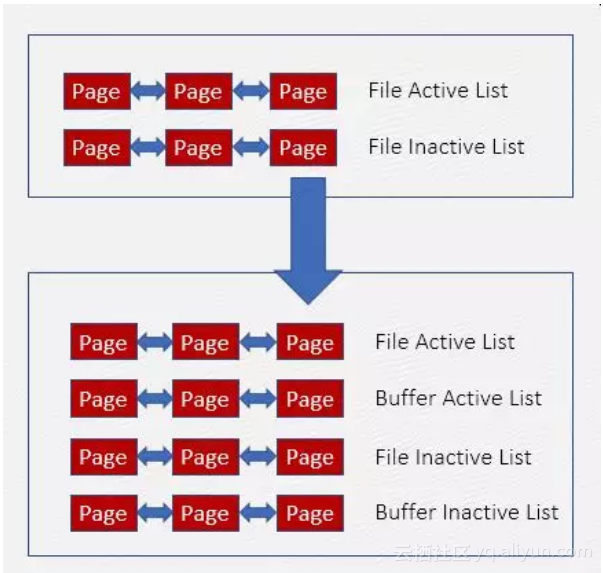
要单独控制Buffer,需要将Buffer从File LRU链表中独立,新建Buffer LRU链表及回收策略:
![3a7c43631c38294fc31b13d6d90ca1aff34a633a]()
1、优先回收Cache
2、按比例回收Cache和Buffer
如果Cache不满足回收条件,则按比例同时强制回收Buffer和Cache,可以配置100%回收Cache,不回收Buffer。
3、限制Buffer的内存占比
不回收Buffer易造成其内存占用量的持续增加,影响内存分配效率,因此需限制Buffer占总内存的比例,需要合理规划应用程序和Buffer的占比,防止OOM。如果Buffer超出阈值,则强制回收一部分。
优化效果
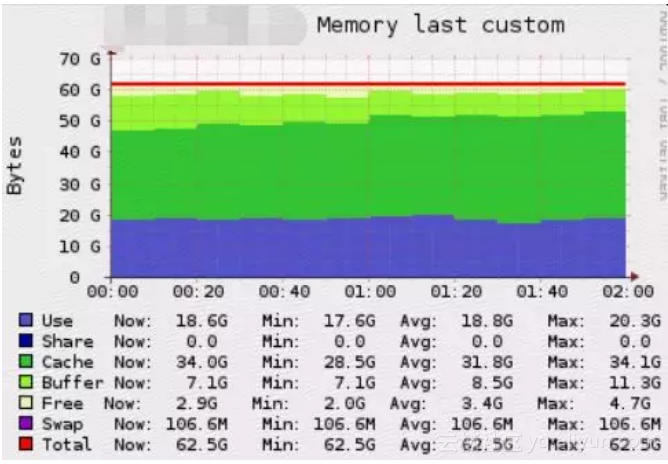
优化前,Cache平均占用32G,Buffer平均占用8G,总占用约41G;
![a1fcf6e698e4ad31c4153344e31a16d8e10d78dc]()
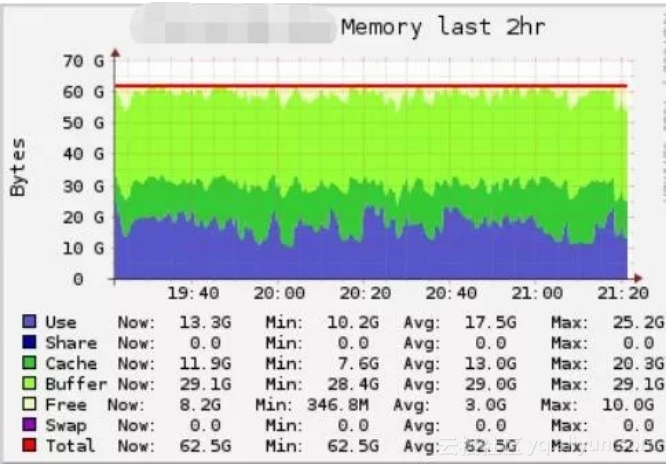
优化后,Cache平均占用13G,Buffer平均占用29G,总占用约42G;
![65b9121e87527db431df890684d9ff35cae5d356]()
对比优化前后,说明在不挤压应用程序可用内存的情况下,Page Cache总体实现了我们的优化目标–更多的缓存元数据。
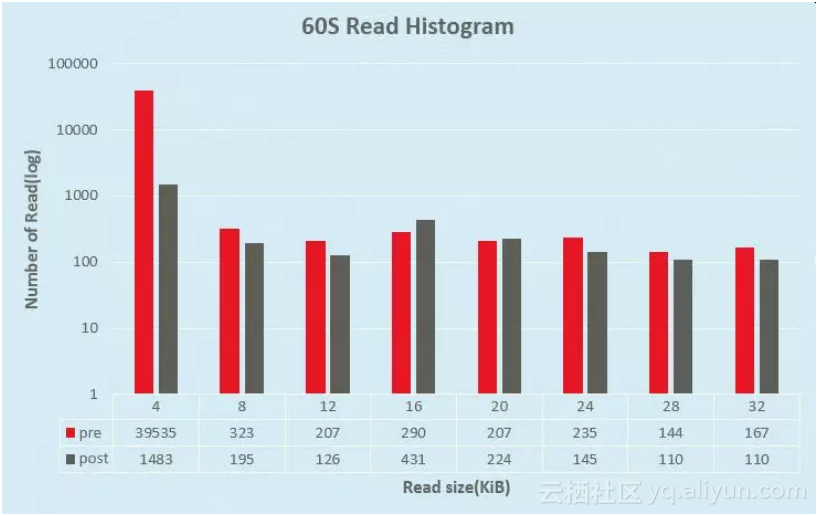
下图横坐标代表读请求的大小,单位为KB,纵坐标为读次数。在1分钟统计时间内,4KB小块读的次数下降了27倍。
![15a73c0a6ca90061bcaefd945a96dd6e39955e0e]()
优化后,在DataNode的扫盘/错误检查/du等操作期间,磁盘繁忙度未出现突出变化,磁盘读吞吐保持平稳,在磁盘不繁忙的情况下,保持在10MB/s。
本地存储优化案例分析
优化Edit log同步
如有必要,请先回顾文章开始对HDFS架构的描述,此处不再赘述。
1、问题描述
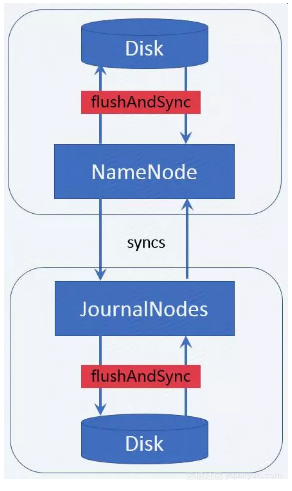
NameNode在响应Client修改文件元数据的请求时,为保证元数据的原子性,需同步地向JournalNodes传输Editlog(小文件),JournalNode在接收到Editlog后同步地写入本地文件系统,同时NameNode也需要将Editlog写入本地文件系统。为了保证每一条Editlog写入磁盘,NameNode和JournalNode在写入Editlog时调用flushAndSync(),如下图所示,此过程消耗了大部分时间。虽然EditLog可以批量传输、批量写入文件系统,但是如果这个过程耗时过长,还是会严重影响NameNode的OPS。
![bb918af014f936057e0f47346abd6be64352604f]()
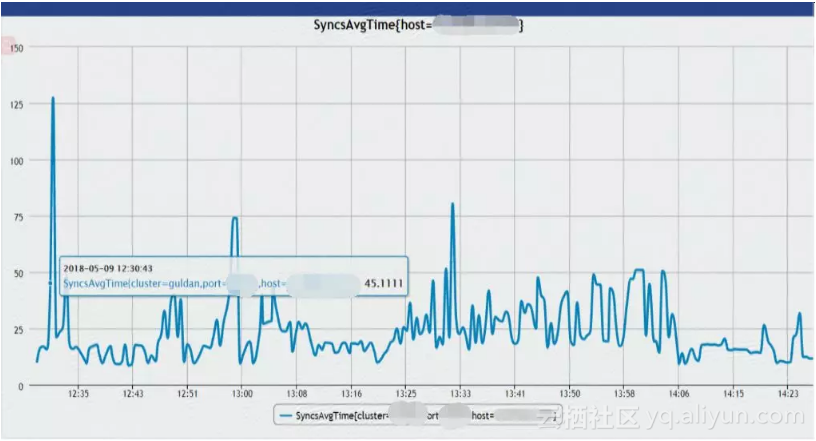
NameNode有相应的指标来衡量同步EditLog的平均延迟时间,下图是优化前的记录,Syncs时间普遍大于20ms,而且波动很大,对QoS会产生严重的影响。
![86db2fbba73fe7fdb1534c5d460cdab03b5a3091]()
2、问题分析
从时延预估角度来看,在不考虑网络延迟的情况下,文件系统一次写请求的延迟时间大于20ms,是不符合预期的。从Java到kernel一步步来追踪问题的根本原因,我们发现是fdatasync系统调用耗费了大部分时间。
![e3fc49e64eeeb5c769abcf014408683856b45f9c]()
-
# strace -f -p <pid> -T -e trace=fdatasync
-
[pid 18493] fdatasync(267) = 0 <0.043851>
-
[pid 18495] fdatasync(267) = 0 <0.036754>
-
[pid 18496] fdatasync(267) = 0 <0.043374>
3、文件系统性能测试
为了验证文件系统的IOPS,通过fio测试文件系统4k sync write的性能,IOPS=25,换算为平均延迟时间约为40ms。
-
file1: (g=0): rw=randwrite, bs=(R) 4096B-4096B, (W)4096B-4096B, (T) 4096B-4096B, ioengine=sync, iodepth=1
-
fio-3.1
-
Jobs: 1 (f=1): [w(1)][9.3%][r=0KiB/s,w=100KiB/s][r=0,w=25IOPS][eta 01h:07m:36s]
4、分析IO流程
通过blktrace分析I/O具体流程,某次flush请求执行时间约42ms,与fdatasync的时延吻合。
-
8,160 29 531 1.052751598 1156 AFWFS 5859838192 + 8 <- (8,161) 5859836144
-
8,161 29 532 1.052751978 1156 QFWFS 5859838192 + 8 [jbd2/sdk1-8]
-
8,161 29 533 1.052752704 1156 GFWFS 5859838192 + 8 [jbd2/sdk1-8]
-
8,161 29 534 1.052753334 1156 IFWFS 5859838192 + 8 [jbd2/sdk1-8]
-
8,161 29 535 1.052754684 1156 DFWFS 5859838192 + 8 [jbd2/sdk1-8]
-
8,161 28 422 1.094201746 1156 CFWFS 5859838192 + 8 [0]
FWFS类型的I/O操作一般由Flush引发,Flush一般由文件系统的barrier功能触发,检查文件系统挂载参数,未指定关闭barrier,也就是说barrier默认是开启的。
-
/dev/sdk1 on /data10 type ext4(rw,relatime,data=ordered
5、barrier为何物
文件系统为了在内核崩溃、异常断电等异常情况下保证完整性,必须保证写数据时将数据、元数据、日志写入磁盘介质。然而一般情况下,即使是同步写,数据也不会立即写入到磁盘中,而是先写入到磁盘自身的缓存中。barrier是保护文件系统完整性的安全特性。
barrier会触发flush操作,将磁盘缓存内的脏数据刷回磁盘介质。在flush操作完成前,磁盘无法处理后来的I/O请求;同时现代磁盘缓存越来越大,导致flush变成一个漫长的过程。总之,barrier以牺牲文件系统性能为代价,换取文件系统完整性。
6、barrier可以关闭吗?
若RAID卡或磁盘本身支持掉电保护,则可关闭barrier功能;
若RAID卡和磁盘不支持或关闭写缓存,也可关闭barrier功能
7、优化方案
文件系统禁用barrier,挂载参数添加nobarrier
-
/dev/sdl1 on /data11 type ext4 (rw,relatime,nobarrier,data=ordered)
关闭磁盘写缓存
hdparm -W 0 /dev/sdX
关闭RAID卡写缓存
通过RAID卡管理工具关闭写缓存
8、优化效果
通过fio测试文件系统4k sync write的性能, IOPS提升至180左右
-
file1: (g=0): rw=randwrite, bs=(R) 4096B-4096B, (W)4096B-4096B, (T) 4096B-4096B, ioengine=sync, iodepth=1
-
fio-3.1
-
bs: 1 (f=1): [w(1)][11.2%][r=0KiB/s,w=748KiB/s][r=0,w=187IOPS][eta 02m:39s]
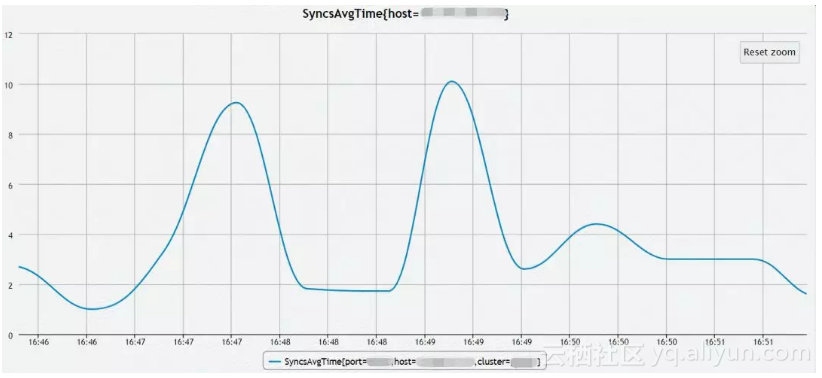
NameNode的Syncs指标下降到10ms以下。
![d20f9b1b9c962474bff7ed5cfecce0563eadfd9e]()
DataNode目录结构优化
1、庞大的目录规模
HDFS Block保存在DataNode,由Block id计算出最终block保存在哪个子目录。
![05b69c49a68aa02e5285e56277031def13ef8ad0]()
单个DataNode的目录数估算:256 x 256 x NS个数 x Disk个数
以10个Namespace,12个磁盘为例,目录总个数约为:
256 x 256x 10 x 12 = 7864320 ≈786万
2、易导致I/O瓶颈
DataNode的Block report、DU、DirectoryScanner等过程会扫描所有subdir目录,因目录数量庞大,操作系统的Buffer Cache不足以缓存所有目录项及索引节点,因此需要从磁盘读取。因扫描过程持续时间较长,磁盘压力过大,严重影响DataNode响应Client的IO请求。
3、优化方案
目录结构从256 x 256升级为32 x 32
以10个Namespace,12个磁盘为例,目录总个数约为:
32x 32 x 10 x 12 = 122880 ≈12万
4、优化效果
以DataNode全量汇报Block时间为例,时间由接近1小时,下降为78秒。
| NS*Disk |
10*12 |
10*12 |
| 目录结构 |
256x256 |
32x32 |
| 总目录数 |
7864320 |
122880 |
| report耗时 |
0:57:54 |
0:01:18 |
本地存储系统性能实时监控
我们在遇到很多案例之后发现Linux kernel没有很好地提供我们想要的工具或者接口来实时的监控存储系统的性能,这使我们在分析I/O问题时感觉非常麻烦。
为了更方便、直观、实时地监控存储系统的I/O行为和性能表现,需要在kernel中开发相应的功能接口,暴露给用户。
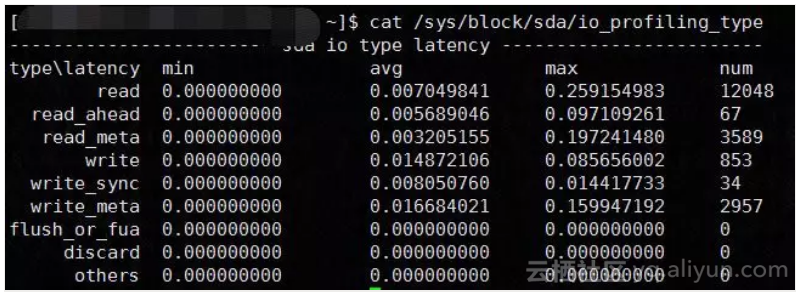
不同类型的I/O size实时统计:
![b172bfc81058d4c8187ea77c2fab0d0568b6f190]()
不同类型的I/O Latency实时统计:
![8595b7e998effe4641ac7fd42a4c2eba425ff789]()
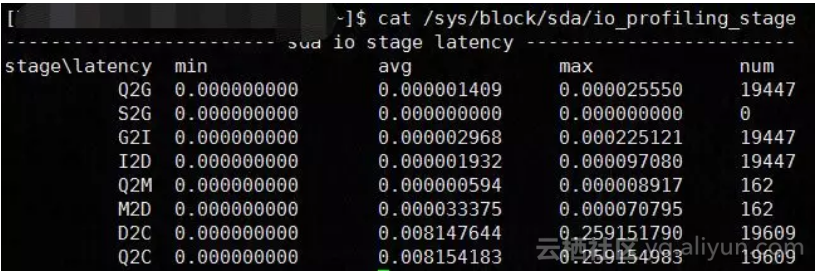
I/O Stage Latency实时统计:
![d28cf103d746604d5c718134d9bcc35f0beaf3d1]()
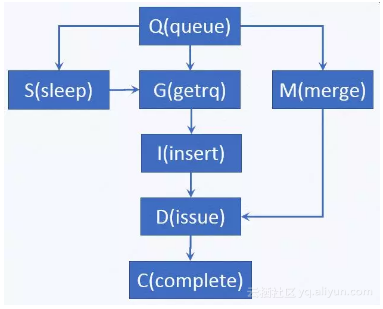
queue: I/O 到达block层
getrq:I/O分配到request
sleep:request不足,I/O需等待
merge:I/O合并到已分配的request
insert:request插入到request队列
issue:request发送到设备驱动
complete:request完成
![a1e5f31954bcaed80bab4b9bece77187c285d0db]()
S2G:如果出现多次,说明请求队列过小或并发度过高
Q2M:多次I/O合并为一次,有益于提升磁盘性能
D2C:设备驱动及以下协议栈处理I/O的效率
Q2C:整个I/O协议栈的处理效率
磁盘故障监控与自动化运维
在超大规模集群中,磁盘和raid卡的硬件故障是很频繁的,会严重的影响QoS,因此需要及时发现、及时报警、及时报修。Kernel层及驱动层是感知磁盘故障的第一线。
故障类型与自动化运维策略:
| 故障类型 |
自动踢盘 |
自动报警 |
自动报修 |
| 磁盘介质损坏 |
|
|
|
| 磁盘链接错误 |
|
|
|
| 磁盘IO响应慢 |
|
|
|
| 磁盘reset超时 |
|
|
|
| raid卡IO响应慢 |
|
|
|
| raid卡频繁reset |
|
|
|
| raid卡故障 |
|
|
|
原文发布时间为:2018-10-16
本文作者:刘洪通