研究过设计模式的程序员都知道迪米特法则(Law of Demeter,LoD)也称为最少知识原则(Least Knowledge Principle,LKP):一个对象应该对其他对象有最少的了解。通俗地讲,一个类应该对自己需要耦合或调用的类知道得最少,你的内部是如何复杂都和我没关系,那是你的事情,我就知道你提供的这么多public方法,我就调用这么多,其他的我一概不关心。
这个法则体现的是“高内聚,低耦合”的设计思想。
我们从这个法则出发,谈谈代码(这里的代码特指java、C#等高级程序语言)与数据库的交互。
其实迪米特法则用在代码和数据库交互的时候是有点犯难的——不是一个国家的,语言不通啊:一个是高级逻辑控制语言,一个是结构化查询语言,咋高内聚低耦合呢?
古代(20年前)的程序员很聪明,这种问题岂能难倒IT精英?把SQL语句封装在一个SQLHelp类里面,让这个类调用开放式数据链接协议(ODBC)将SQL语句传给数据库,数据库执行返回数据集。以后要与数据库直接调用SQLHelp类不就可以了么,多大的事啊。
这就是古代程序员的处理方式,这种方式至今还有很多老程序员在使用,让人感概青春。
之后更进一步,ORM出现了。我认为这货出现最大的原因是这样的:码农最熟悉的是和类、方法打交道,最爱的是用诸如 Girl.撩() 来处理数据。而ODBC返回的是以行构成的数据集,并不是码农最爱的类,是没有办法对一个数据集进行诸如
For (Girl girl:Girls){girl.撩()}
这种操作的。当然这也难不倒程序员,数据集中的记录都是可以变成类的么,字段对应类属性,一行记录一个类,一个数据集就是一个List<T>,然后哥不就又能用上心爱的迭代器撩妹了么?
程序员的思路就是代码复用,久而久之,大家干脆就把这一套东西整理出来一套框架,然后在代码复用(偷懒)的道路上一路走下去,什么数据库连接池,什么数据库元数据读取自动生成类,什么自动生成增删改查方法,老夫全给他来个自动的。总之,要像操作类一样操作数据库。这就是ORM的核心思想了。
ORM确实给程序员们带来了便利。想想看,ODBC时代与数据库交互神烦,需要你手工从建立链接再写SQL语句再处理返回结果集再关闭连接,然后拿到的数据集还用用游标读取。。。一大堆操作下来,刚入门的小鸟彻底蒙逼。而ORM呢?几乎是“5分钟入门”,程序员甚至都不用写一条SQL语句,真的很方便啊。
但是不要因为ORM的出现而走向另外一个极端:“一切全靠ORM”。现在网上关于ORM的争论中,甜浆派与咸浆派很大一部分焦点集中在:
“不用操心SQL代码了,太好了”
VS
“丫自动生成的SQL太蠢,没法优化”
这种争论没日没夜,我看是谁也说服不了谁。作为一名又写代码又写SQL的介于码农与DBA之间的老蝙蝠,我不打算参与甜咸战争。我只想问一句:
ORM贯彻了迪米特法则么?
我认为只能说贯彻了一半。代码与数据库始终是两个国家,ORM是一个翻译官,将对数据操作的方法翻译成SQL语句给数据库,又将数据集翻译成类给代码。重点是:对数据库操作的方法还是在代码层中。
有人说这没错啊。ORM把对数据库的操作封装在方法中了啊,有什么不对?
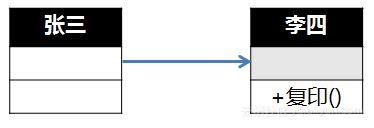
那么请回答我一个问题:张三是领导,要李四去复印资料。正常方式是什么?肯定是张三对李四说:“小李,来把这份资料帮我复印一下。”张三只是告诉李四要复印资料,至于李四怎么找到复印机,复印机什么牌子的,李四怎么打开复印机,复印机是不是缺纸要填纸,是不是还插着电,李四的手指是不是太粗按错按钮……张三需要管么?不需要吧。我们用类图来说:
![e2443cd1d24fcc6dd73470a350aeda12b8bcb266]()
就是这么简单,复印是李四类的方法,张三只管调用就行。
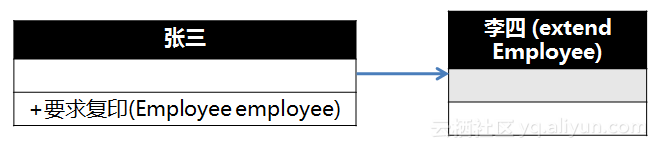
现在如果咱们这么玩:
![8a04eb2fcac84ab6bb99e809d643f9fe91a35dc3]()
请问各位,你拿出这张UML图给你老大看,你会不会给骂死?
在这个玩法中,张三必须替李四规划一切关于复印的行为:先出办公室,往左拐,小心端茶的小妹,走到头,看到复印机了么,来,乖你先检查一下电啊,哦,是不是没纸了啊,没纸你问前台去拿几张……
如果某天李四不小心腿受伤了,你是不是还要在方法中增加一个“记得拄拐杖哦亲”?好一个亲历亲为的张三总!
ORM就是这位亲历亲为的张三,看似让程序员“不需要考虑数据库”,但事实上依赖ORM操作数据库,则任何操作细节都需要在代码中直接体现。同时,ORM实现底层对数据库元数据的耦合度非常高,一个字段的改名、数据类型变换都会引起元数据失效,需要重新同步,甚至重新代码编译。
类之间依赖,A类中内部变量修改,竟然要B类一起修改。大家都认为这很不好,违背设计模式。
那么请问为什么ORM里面这么玩你们就觉得没问题?!
并且,各位要明白,经过翻译过的SQL语句,如同普通话配音后的好莱坞大片,失去了原先的味道。而各种土味翻译咖喱英语有时候也会闹出一些事(Mybatis中手写的Map文件算是对ORM自动SQL语句狂热的一种反思)。比如,某个ORM框架会将字符串的“whitespace”默认解释成为null;某个ORM会将string默认为 NVARCHAR,引起数据库中隐式字段转换……
当然了,程序员会说,利大于弊么,毕竟ORM降低了代码量,有一些程序员还会举出ODBC时代需要自己写SQL的痛苦例子。
但是…我想问一句:你还记得当年大明湖畔的夏…存储过程否?
![c328ae7fc446db900c082a3dea64f03e0b34e9a8]()
如果一个方法放在本类中,既不增加类间关系,也对本类不产生负面影响,那就放置在本类中。如果各位能够认可这句话,那么我们就继续聊存储过程的问题。如果不认可,接下去就别看了,浪费时间。
撇开写Java和写SQL两帮人之间的恩怨,不要讨论谁不懂谁的技术,程序是数据结构+算法。本质上,数据体现业务,程序(算法)实现业务。
不管是搞数据库的还是堆码的,本质上都要为业务服务。当程序员实现业务的时候,第一个想法应该是划分业务模块,根据模块开始画UML图,没有一个程序员傻到一堆代码写在一起。大家都会用“类”来体现模块,以类之间的交互(方法调用)实现模块间交互操作。
好比程序员写大段零碎代码会被同行鄙视,只有懂得将代码封装为类、方法才算入了门一样。在搞数据库的眼中,ORM代码翻译出来的大量零碎的SQL语句,也是要被鄙视的。
在数据库层,正确的将零碎语句包装成模块/类的方法就是存储过程。存储过程实现了代码层与数据库层之间的迪米特法则。
存储过程什么好处?代码封装什么好处,存储过程就什么好处;接口定义带来什么好处存储过程就带来什么好处——只要接口契约不变,数据库内部修改就不影响代码层调用。一个存储过程与调用方规定好传参、出参后,就算原始数据类型变更,甚至名字变了,存储过程的与调用方的契约也不会改变。为什么?很简单啊,内部做类型转换与字段别名啊,表换名字都不怕。
软件开发中讲究一个代码修改成本。假设你现在还是“亲历亲为的张三总”,数据库中有一张表,原有6列,突然有一天要增加1列,而且这一列数据要跨N张表,处理M个逻辑才能展现出来。这样的变化是比较恐怖的,请问你代码中要写多少改多久?
ORM狂热爱好者认为“ORM能让程序员专注于逻辑实现,而不用考虑数据库如何实现”。“不用考虑”说起来很美好,但是就如不懂设计模式的码农总要写出垃圾代码一样,在实际业务项目中,是要等着交补课费的,而且往往这个补课费是后人来交。那么按照ORM爱好者的说法延伸,如果能直接在数据库中实现数据逻辑,提供接口(存储过程、函数等形式)给到代码层,是否将“不用考虑”体现的更淋漓尽致,更能体现面向“接口”编程的思想?
在写码的时候有“接口”的概念,为何与数据库打交道就失去了这个概念?为什么数据库修改影响到代码你们就认为理所应该?ODBC时代抱怨要手写SQL,ORM时代欢呼不用和数据库打交道(你真的不用和数据库打交道?),只能说从当年的ODBC到现在的ORM,这些人就都没有领会到“封装”的意义,没有思考,没有明白什么是高内聚,低耦合 。
实现迪米特法则,在数据库中封装好数据操作,数据库内部修改不需连带要代码层一起修改。 把数据层的存储过程、视图、函数等封装好的代码看作是类、接口,再与代码层打交道,才是正确的打开方式。
ORM之争不会结束,但是对于我们,关键看疗效。作为一个半码农半DBA半运维的老蝙蝠,我不排斥用ORM工具处理简单单表逻辑,因为确实写起来方便。 但是如果上帝的归上帝,凯撒的归凯撒。业务逻辑由代码实现,数据逻辑由数据系统实现,是不是更好?
当然,屁大点事都要在数据库中写个“类”(存储过程),那也太折腾人。所以,ORM还是我们的小伙伴。简单单表操作用ORM,复杂数据逻辑实现用存储过程。不否定ORM,也不全部依赖ORM,遵循高内聚低耦合法则,这就是我的方式。