生成式句法分析指的是,生成一系列依存句法树,从它们中用特定算法挑出概率最大那一棵。句法分析中,生成模型的构建主要使用三类信息:词性信息、词汇信息和结构信息。前二类很好理解,而结构信息需要特殊语法标记,不做考虑。
本文主要利用了词汇+词性生成联合概率模型,使用最大生成树Prim算法搜索最终结果,得到了一个简单的汉语依存句法分析器。
开源项目
本文代码已集成到HanLP中开源:http://hanlp.dksou.com/
基本思路
统计词语WordA与词语WordB构成依存关系DrC的频次,词语WordA与词性TagB构成依存关系DrD的频次,词性TagA与词语WordB构成依存关系DrE的频次,词性TagA与词词性TagB构成依存关系DrF的频次。为句子中词语i与词语j生成多条依存句法边,其权值为上述四种频次的综合(主要利用词-词频次,其余的作平滑处理用)。取边的权值最大的作为唯一的边,加入有向图中。
在有向图上使用Prim最大生成树算法,计算出最大生成树,格式化输出。
模型训练
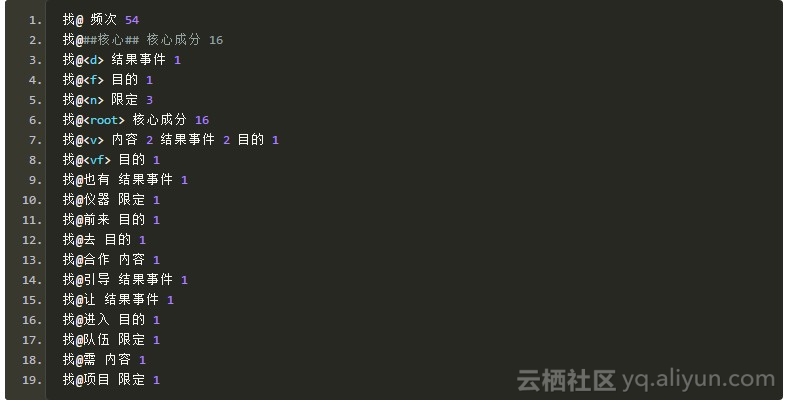
简单地统计一下清华大学语义依存网络语料,得到如下结果:
![a46c46ac5acaa96c6478752328937c191941f49a]()
@符号连接起两个词汇或词性,用<>括起来的表示词性,否则是词汇。如果@后面没有内容,则表示频次,否则表示一些依存关系与其出现的频次。
依存句法分析
分词标注
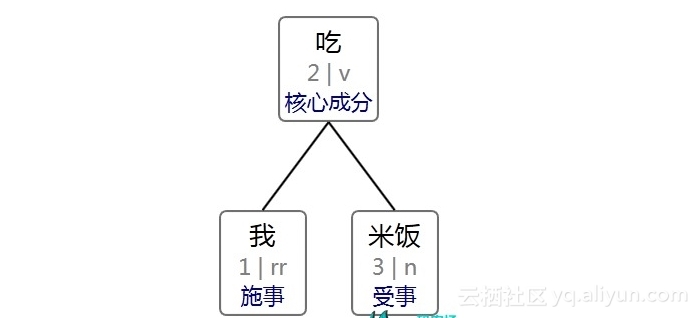
以“我吃米饭”为例,先进行分词与词性标注,结果:
![94cebbb89480803c1a1f9a6ef1265bfc59984f5e]()
生成有向图
由于依存句法树中有虚根的存在,所以为其加入一个虚节点,这样一共有四个节点:
![3a08122d99a8ec80abb5aabbf5d3cd2119f47a40]()
每个节点都与另外三个构成一条有向边,一共4 * 3 = 12 条:
1.Â
##核心##/root 到 我/rr : 未知 10000.0
2.Â
##核心##/root 到 吃/v : 未知 10000.0
3.Â
##核心##/root 到 米饭/n : 未知 10000.0
4.Â
我/rr 到 ##核心##/root : 核心成分 6.410175
5.Â
我/rr 到 吃/v : 施事 21.061098 经验者 28.54827 目标 33.656525 受事 37.021248 限定 43.307335 相伴体 48.00737 关系主体 53.115623 内容 53.115623 来源 64.101746
6.Â
我/rr 到 米饭/n : 限定 22.2052 施事 48.00737 受事 57.170277 目标 57.170277 经验者 64.101746 连接依存 64.101746
7.Â
吃/v 到 ##核心##/root : 核心成分 1.7917595
8.Â
吃/v 到 我/rr : 连接依存 96.688614 介词依存 107.67474 施事 107.67474
9.Â
吃/v 到 米饭/n : 限定 24.849068
10.Â
米饭/n 到 ##核心##/root : 核心成分 37.077995
11.Â
米饭/n 到 我/rr : 连接依存 113.2556
12.Â
米饭/n 到 吃/v : 受事 0.6931472
其中“未知”表示边不存在,“受事”“施事”表示依存关系,后面的小数表示权值。我对概率取了负对数,所以接下来用加法求最小生成树即可。
最小生成树
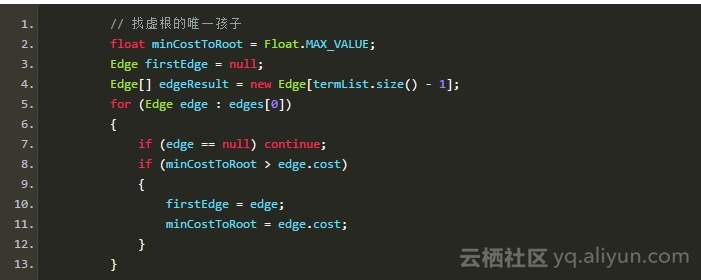
关于最小生成树的Prim算法请参考《最小生成树算法初步》,这里必须有所改动,由于虚根有且只能有一个孩子,所以虚根必须单独计算:
![2efeb51400240cf67d665707f1f7bc963a109725]()
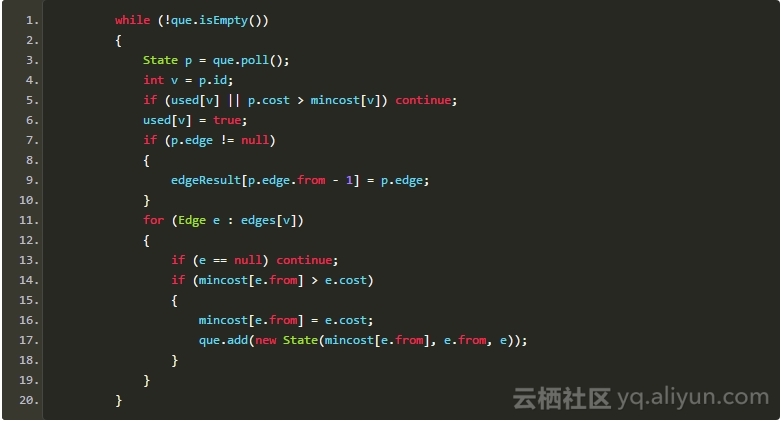
然后就是中规中矩的Prim算法:
![586b6aeb8e81bf90aa5a0f659884e9b92141fb76]()
得出最小生成树:
![0096462288e3f57a1819cb46687e99419169ec5a]()
格式化输出
将其转为CoNLL格式输出:
![584e8016ad42b12520c2ee2b2b0c58c283305680]()
可视化
使用可视化工具展现出来:
![52ff09c7dfae080ec1cd615f8f910941d992f5e3]()
结果评测
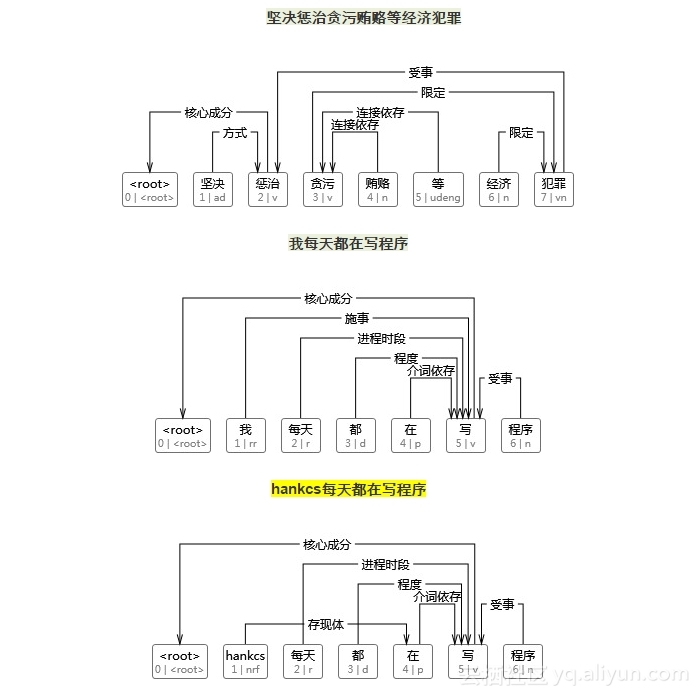
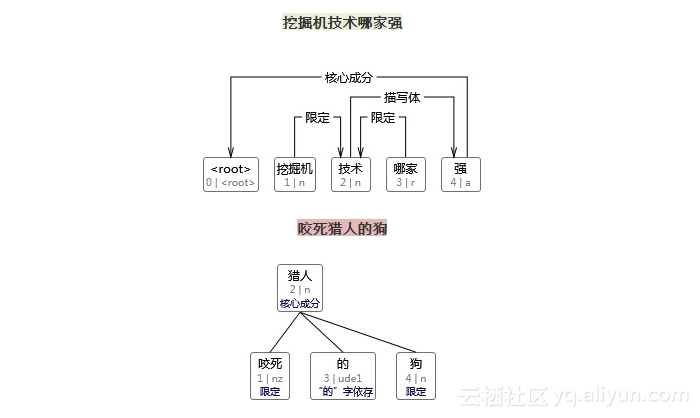
我没有进行严格的测试,这只是一个玩具级别的汉语依存句法分析器。先来看几个good case与bad case——
![1c17aefc07d93723df4002f6a69158bb295c70f3]()
![1ae3bf4d5407e17be8a1b629920e46c2ce5fc69e]()
效果比较马虎,为何这么说,这是因为分词的训练语料和句法分析语料不同,且我自知此方法严重依赖词汇共现,主要是这种二元词汇生成模型无法充分利用上下文。
短一点的搜索语句可能还是有微量的利用价值。
TODO
应当采用判别式模型,导入SVM或最大熵作为权值的计算工具,然后使用最大生成树算法获取全局最优解。
文章转载自hankcs 的博客