1.导入carbondata依赖的jar包
将apache-carbondata-1.5.3-bin-spark2.3.2-hadoop2.7.2.jar导入$SPARKHOME/jars;或将apache-carbondata-1.5.3-bin-spark2.3.2-hadoop2.7.2.jar导入在$SPARKHOME创建的carbondlib目录
2.导入kafka依赖的jar包
接入kafka数据需要依赖kafka的jars,将以下jars导入$SPARKHOME/jars
kafka-clients-0.10.0.1.jar
spark-sql-kafka-0-10_2.11-2.3.2.jar
3.spark-shell启动服务
./bin/spark-shell --master spark://hostname:7077 --jars apache-carbondata-1.5.3-bin-spark2.3.2-hadoop2.7.2.jar
a).导入依赖
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.CarbonSession._
b).创建session
启动第一个目录是数据存储目录,第二个目录是元数据目录;都可以是hdfs目录
val carbon = SparkSession.builder().config(sc.getConf).getOrCreateCarbonSession("/home/bigdata/carbondata/data","/home/bigdata/carbondata/carbon.metastore")
c).创建source表
carbon.sql(
s"""
| CREATE TABLE IF NOT EXISTS kafka_json_source(
| id STRING,
| name STRING,
| age INT,
| brithday TIMESTAMP)
| STORED AS carbondata
| TBLPROPERTIES(
| 'streaming'='source',
| 'format'='kafka',
| 'kafka.bootstrap.servers'='hostname:9092',
| 'subscribe'='kafka_json',
| 'record_format'='json',
| 'comment'='get kafka data')
""".stripMargin).show()
d).创建sink表
carbon.sql(
s"""
| CREATE TABLE IF NOT EXISTS kafka_json_sink(
| id STRING,
| name STRING,
| age INT,
| brithday TIMESTAMP)
| STORED AS carbondata
| TBLPROPERTIES(
| 'streaming'='sink')
""".stripMargin).show()
e).创建job任务
carbon.sql(
s"""
| CREATE STREAM kafka_json_job ON TABLE kafka_json_sink(
| STMPROPERTIES(
| 'trigger'='ProcessingTime',
| 'interval'='10 seconds')
| AS SELECT * FROM kafka_json_source
""".stripMargin).show()
f).创建DATAMAP
carbon.sql(
s"""
| CREATE DATAMAP agg_kafka_json_sink
| ON TABLE kafka_json_sink(
| USING "preaggregate"
| AS
| SELECT id,name,sum(age),max(age),min(age),avg(age)
| FROM kafka_json_sink
| GRPUP BY id,name
""".stripMargin).show()
4.常用SQL命令
a).导入本地数据
carbon.sql("LOAD DATA INPATH '/home/bigdata/carbondata/sample.csv' INTO TABLE kafka_json_source").show()
b).查看表结构
carbon.sql("DESC kafka_json_source").show()
c).查看表数据
carbon.sql("SELECT * FROM kafka_json_source WHERE id=1").show()
d).清理表数据
carbon.sql("TRUNCATE TABLE kafka_json_sink").show()
e).删除表
carbon.sql("DROP TABLE IF EXISTS kafka_json_source").show()
f).查看job任务状态
carbon.sql("SHOW STREAMS ON TABLE kafka_json_sink").show()
g).删除job任务
carbon.sql("DROP STREAM kafka_json_job").show()
h).查询DATAMAP表信息
carbon.sql("DESC agg_kafka_json_sink_kafka_json_sink").show()
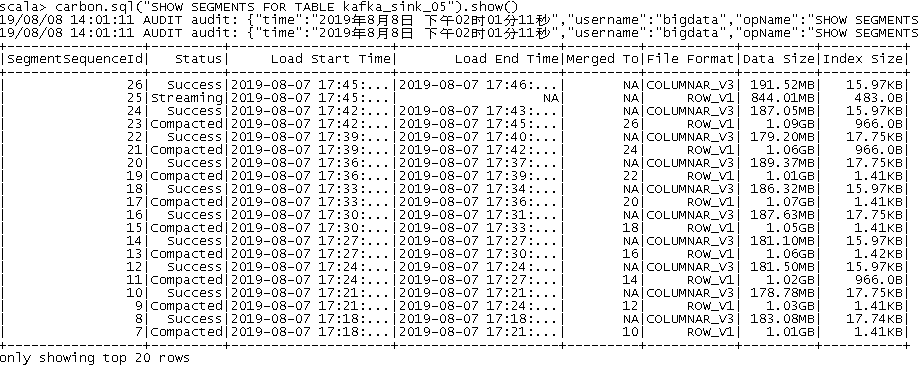
i).查询表Segments信息
carbon.sql("SHOW SEGMENTS FOR TABLE kafka_json_sink").show()
![]()
j).条件查询
carbon.sql("SELECT * FROM kafka_json_sink WHERE agent_id=499 AND signature=''").show()
![]()
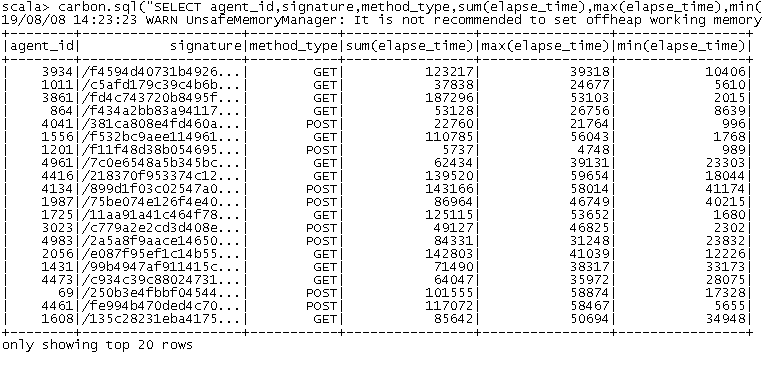
k).聚合查询
carbon.sql("SELECT agent_id,signature,method_type,sum(elapse_time),max(elapse_time),min(elapse_time) FROM kafka_json_sink GROUP BY agent_id,signature,method_type").show()
![]()
5.注意事项
a).kafka使用配置
由于Carbondata的kafka-consumer反序列化配置如下,所以在kafka-producer应该使用对于配置,否则无法解析数据
key.deserializer = org.apache.kafka.common.serialization.ByteArrayDeserializer
value.deserializer = org.apache.kafka.common.serialization.ByteArrayDeserializer