
Adaptive Execution如何让Spark SQL更高效更好用?
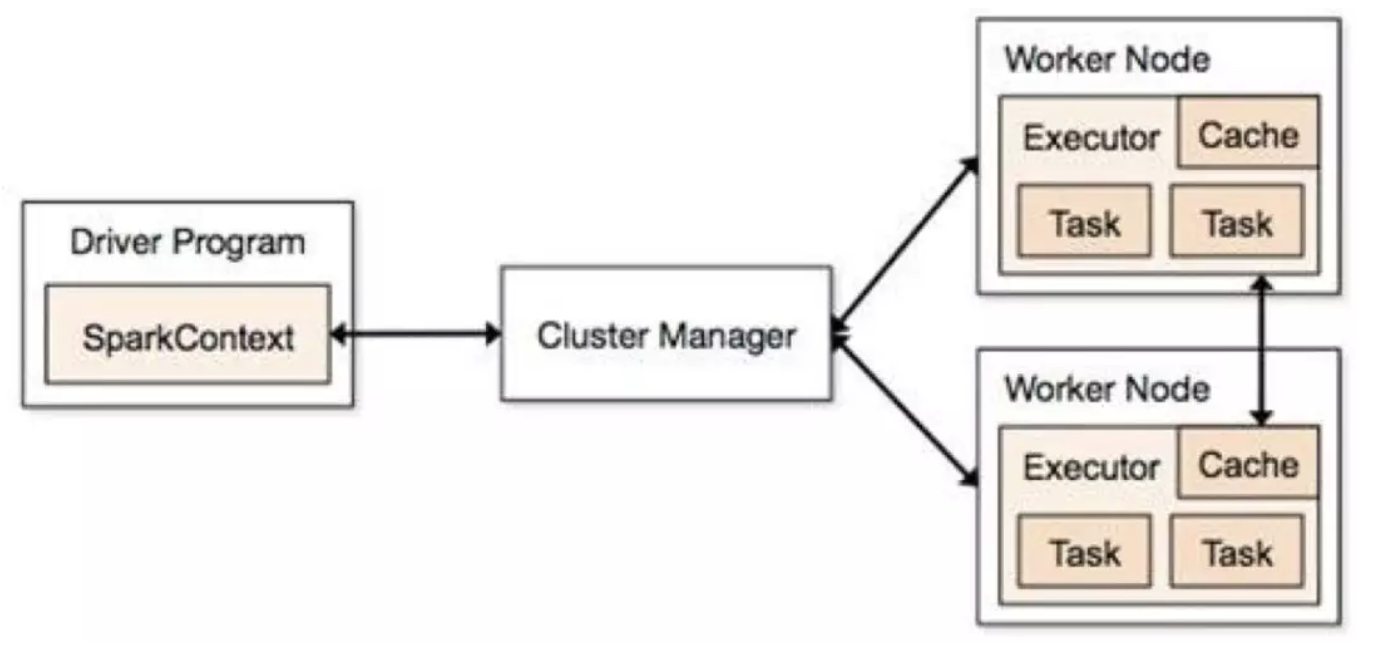
本文转发自技术世界,原文链接 http://www.jasongj.com/spark/adaptive_execution/ 1 背 景 Spark SQL / Catalyst 和 CBO 的优化,从查询本身与目标数据的特点的角度尽可能保证了最终生成的执行计划的高效性。但是 执行计划一旦生成,便不可更改,即使执行过程中发现后续执行计划可以进一步优化,也只能按原计划执行; CBO 基于统计信息生成最优执行计划,需要提前生成统计信息,成本较大,且不适合数据更新频繁的场景; CBO 基于基础表的统计信息与操作对数据的影响推测中间结果的信息,只是估算,不够精确。 本文介绍的 Adaptive Execution 将可以根据执行过程中的中间数据优化后续执行,从而提高整体执行效率。核心在于两点: 执行计划可动态调整 调整的依据是中间结果的精确统计信息 2