开发环境:
1. InteliJ IDEA COMMUNITY
2. 阿里云 MaxCompute Studio
3. 阿里云 DataWorks
4. apache-maven-3.5.4
MaxCompute Studio 是阿里云 MaxCompute 平台提供的安装在开发者客户端的大数据集成开发环境工具,是一套基于流行的集成开发平台
IntelliJ IDEA 的开发插件,可以帮助您方便地进行数据开发。
依赖包:
lombok.Data: 自动填充 getter, setter 方法
com.alibaba.fastjson.JSONObject: JSON 对象解析
实验:
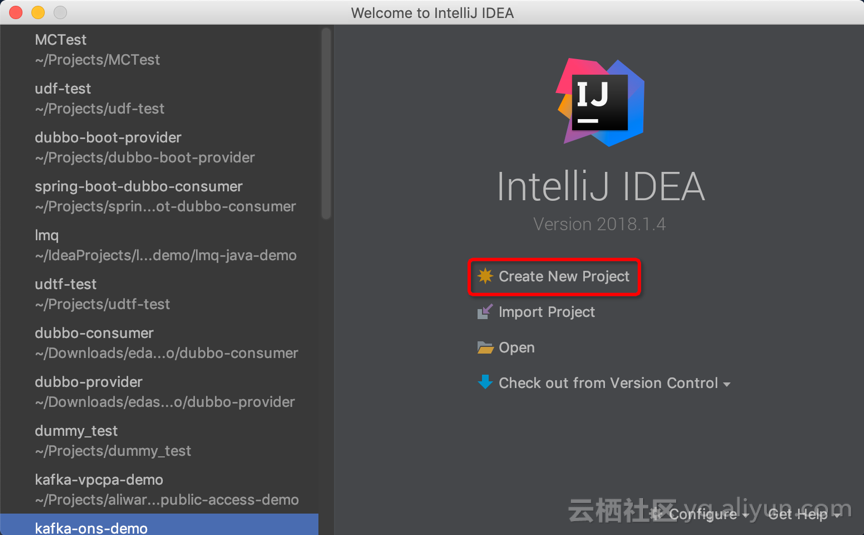
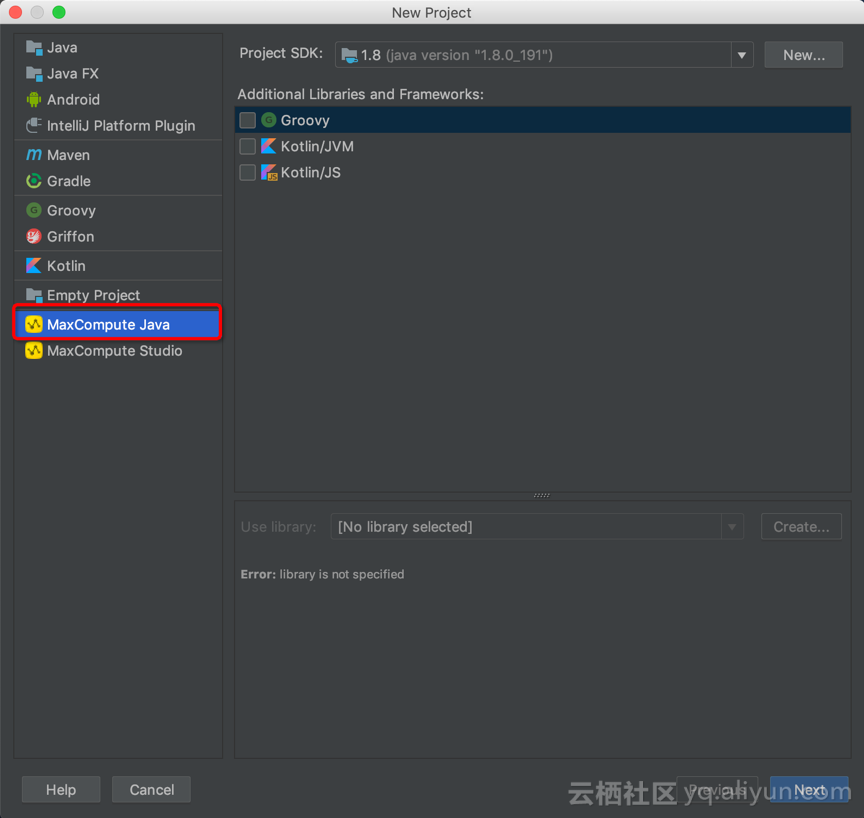
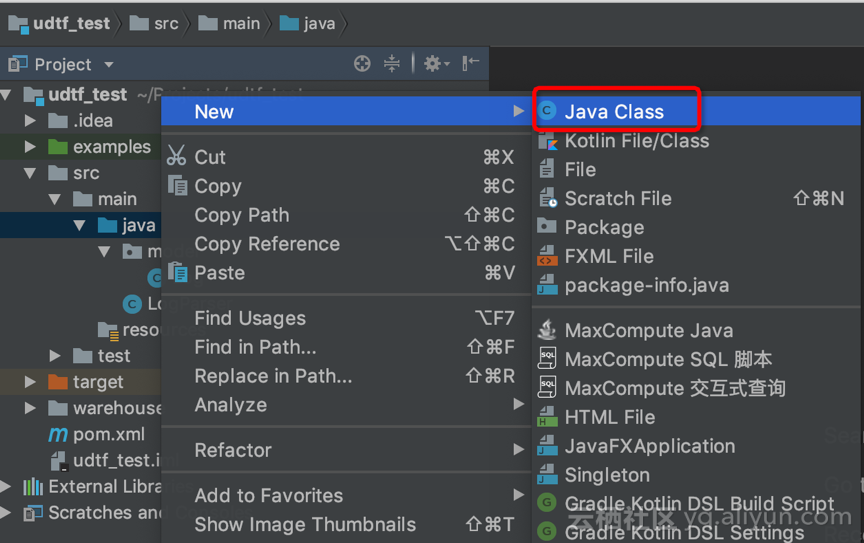
1. IDEA 创建 MaxCompute Java 项目
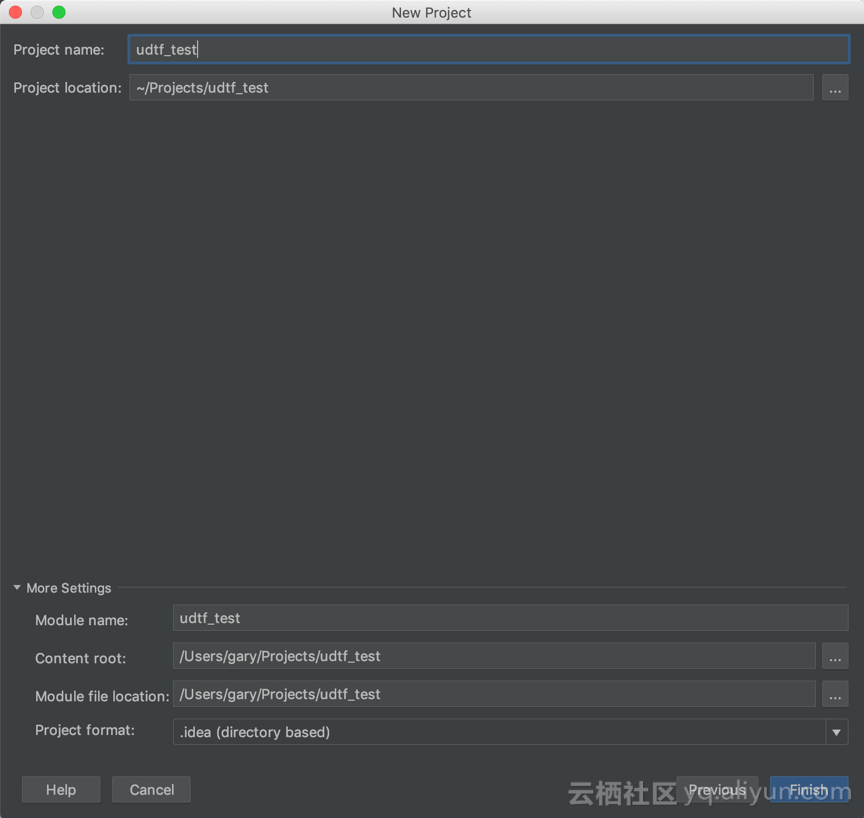
【Create New Project】->【MaxCompute Java】->输入项目名,例如:“udtf_test”
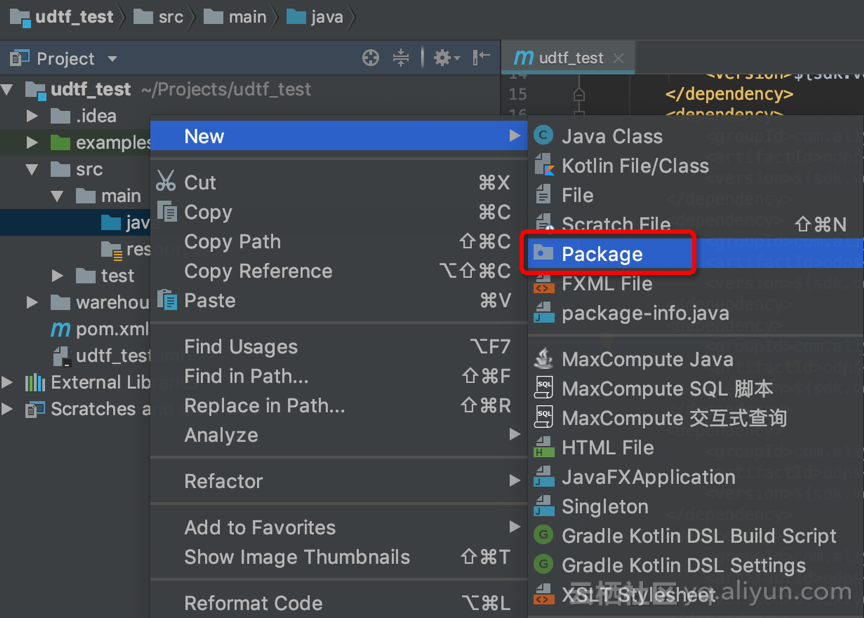
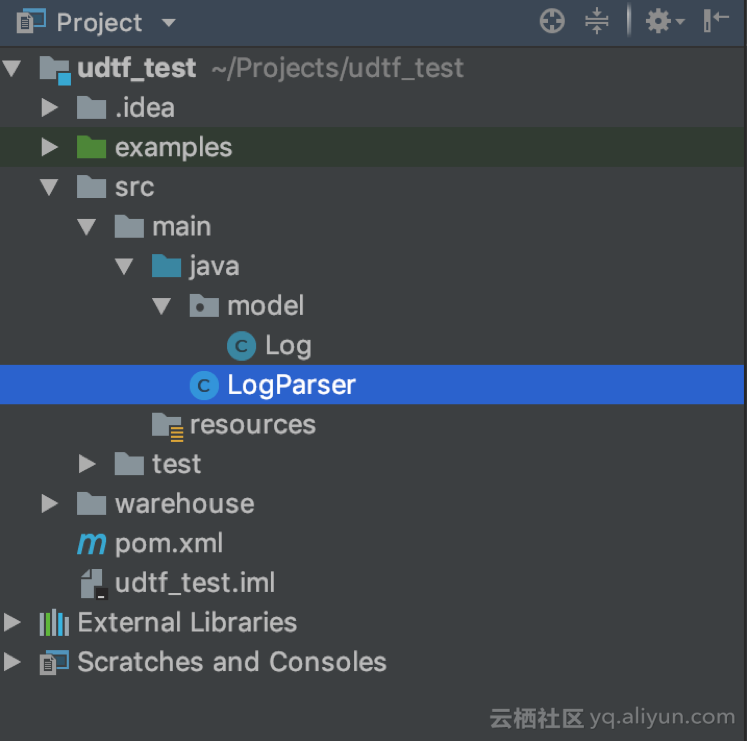
2. 创建日志 model(Log.java)
a. (可选)创建 Package
b. 在该 Package 中创建 Log.java
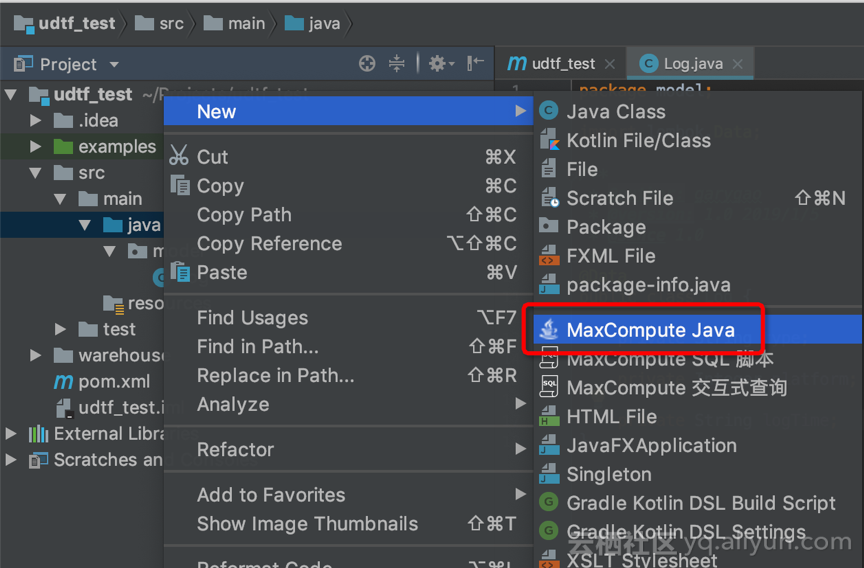
3. 创建 UDTF
a. 【New】->【Maxcompute Java】
b. Name: 输入类名,例如:“LogParser”
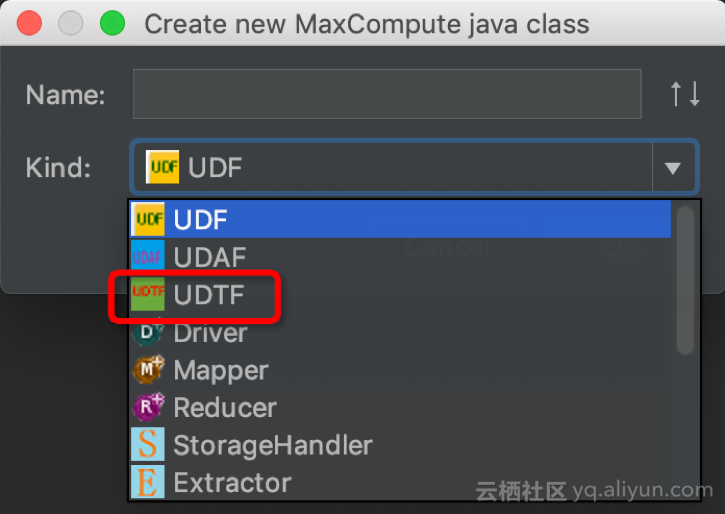
c. Kind: 选择【UDTF】
4. 代码开发
pom.xml
上文中提到的两个依赖,添加到 pom 文件中
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.16.10</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency>
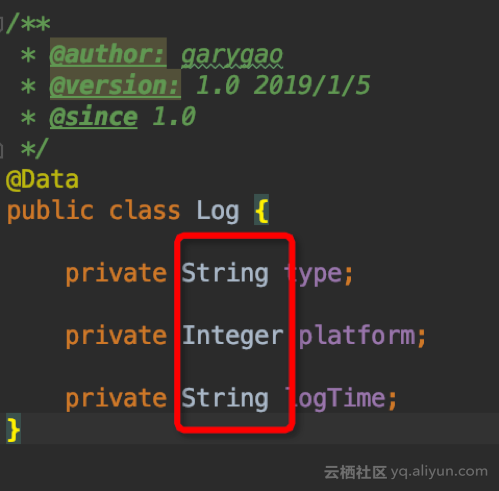
Log.java
日志 JSON 文件的字段定义,可以根据具体的日志字段来定义,引入 lombok.Data,省去了 getter, setter 方法的定义。
package model;
import lombok.Data;
/**
* @author: garygao
* @version: 1.0 2019/1/5
* @since 1.0
*/
@Data
public class Log {
private String type;
private Integer platform;
private String logTime;
}
LogParser.java(UDTF)
import com.aliyun.odps.udf.ExecutionContext;
import com.aliyun.odps.udf.UDFException;
import com.aliyun.odps.udf.UDTF;
import com.aliyun.odps.udf.annotation.Resolve;
import model.Log;
import com.alibaba.fastjson.JSONObject;
/**
* @author: garygao
* @version: 1.0 2019/1/5
* @since 1.0
*/
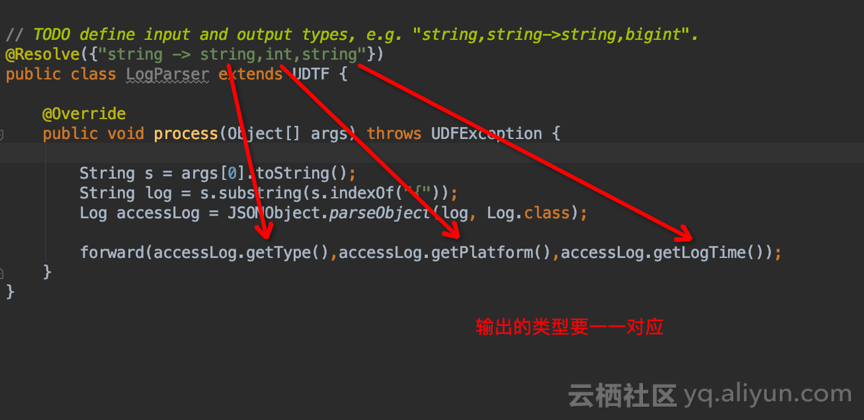
// TODO define input and output types, e.g. "string,string->string,bigint".
@Resolve({"string -> string,int,string"})
public class LogParser extends UDTF {
@Override
public void process(Object[] args) throws UDFException {
String s = args[0].toString();
String log = s.substring(s.indexOf("{"));
Log accessLog = JSONObject.parseObject(log, Log.class);
forward(accessLog.getType(),accessLog.getPlatform(),accessLog.getLogTime());
}
}
![3ebaebf5e5e0bec542dc5a89a5119028fab3db60]()
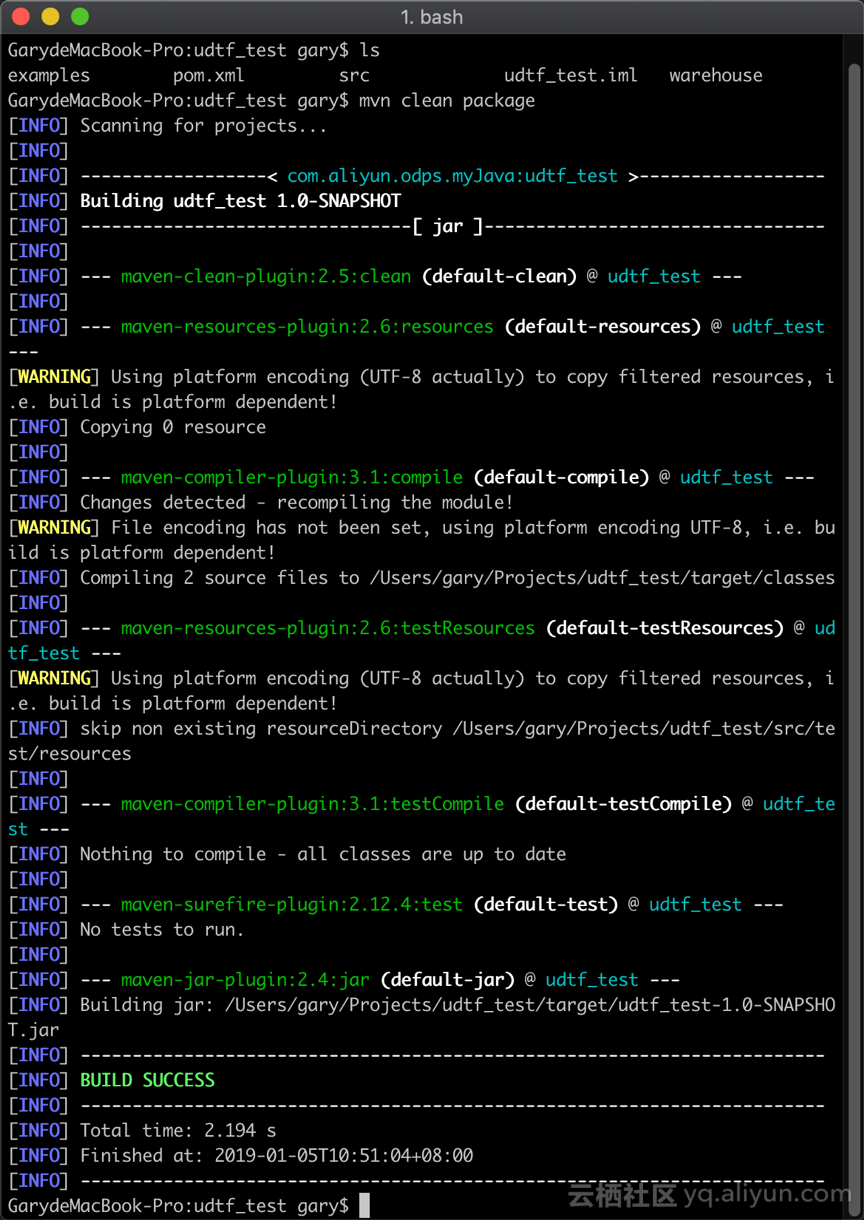
5. 导出 Jar 文件
进入到该项目的根目录,使用 maven 打包,导出 Jar 文件。
mvn clean package
6. 第三方依赖单独下载
本例中使用到 fastjson,下载地址:fastjson
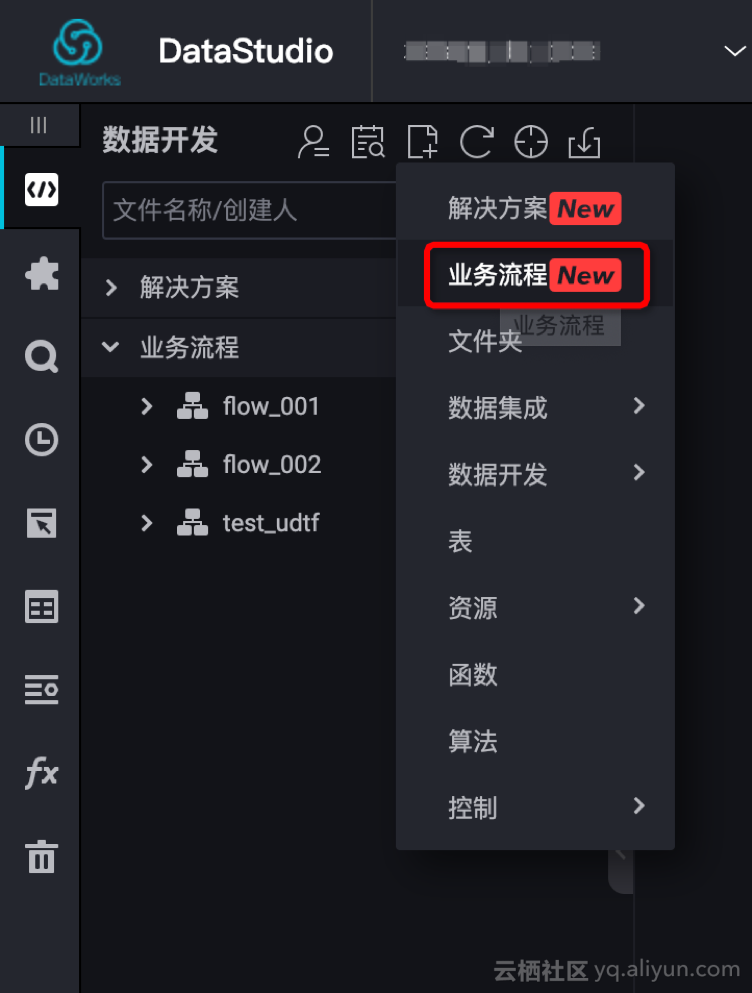
7. 进入 DataWorks 工作空间使用该 UDTF 函数
a. 创建业务流程,本例命名:“test_udtf”
![6d5b09f8c24c6253a68b7eebe1c53a71a1422d31]()
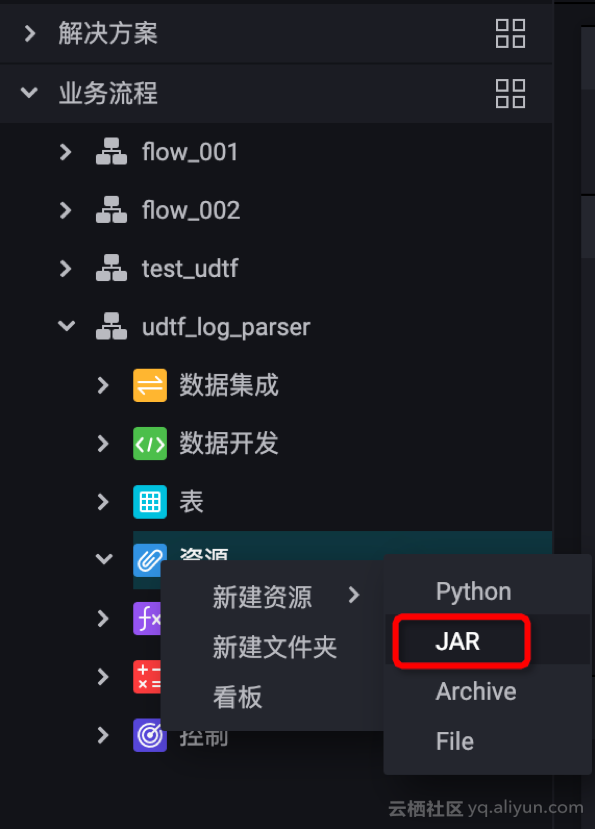
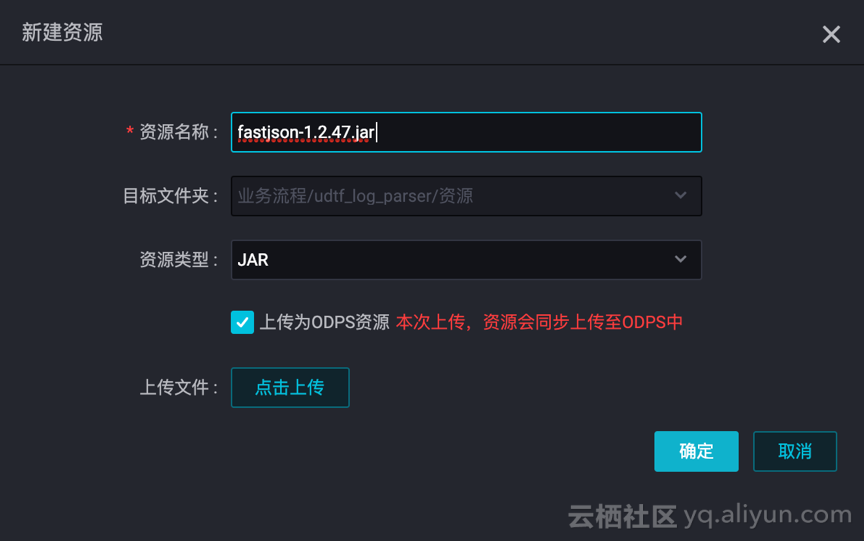
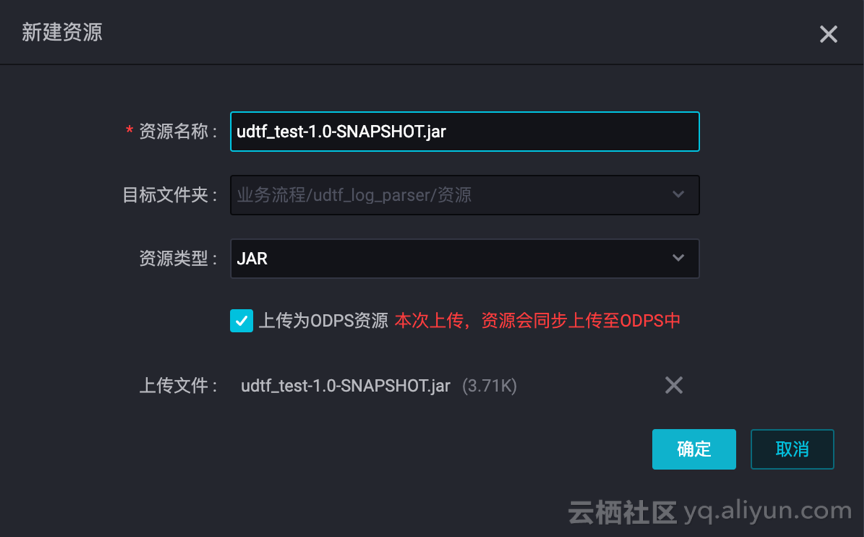
b. 新建资源,UDTF 与第三方依赖都要上传!!
![4568ef98c9a24f435a2384e9666ed2cd95a40f4e]()
![2415c7a997e2b33006c776fc987fd242fa971e94]()
![4dc94a798d5b49e7a8b05ad2fa4d4cbeecb3d48d]()
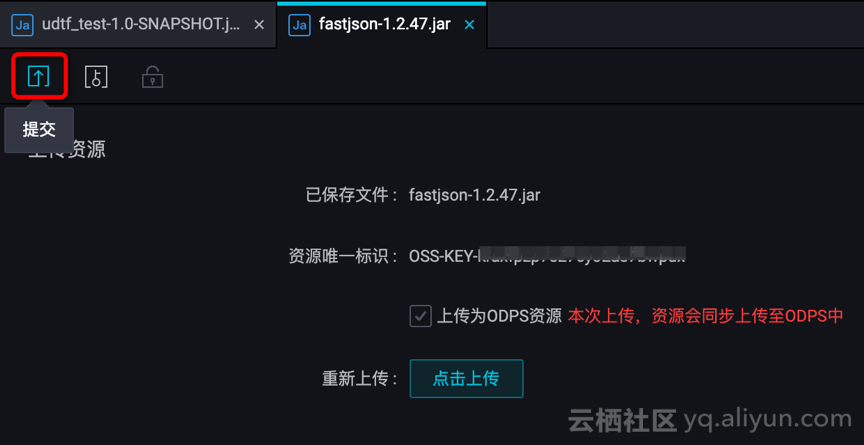
c. 提交资源,UDTF 与第三方依赖都要提交!!
![bdd5bf5cebfd9fc2ae453414979056c1c6f02f24]()
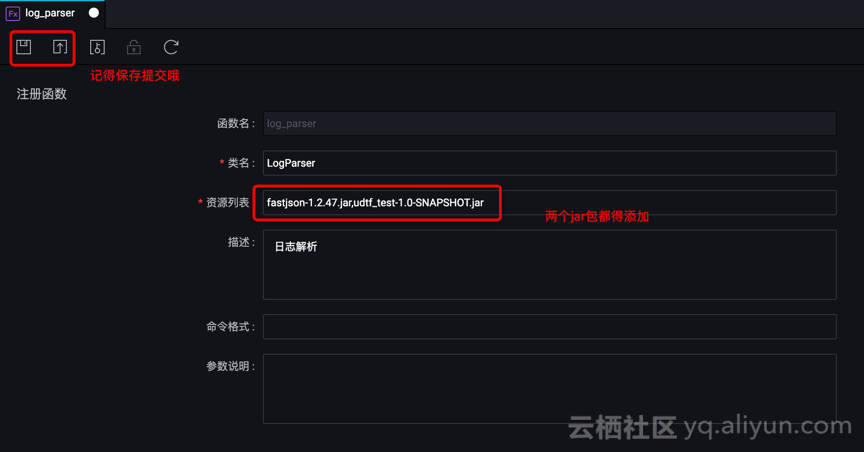
d. 注册函数
资源列表:两个 Jar 文件都要手工输入,记得保存、提交!!
![ffc911911bb02463e464b0898adea1781efd7e7e]()
![e92f0a008d9017a4f313a8338d1ca715dc80a5ca]()
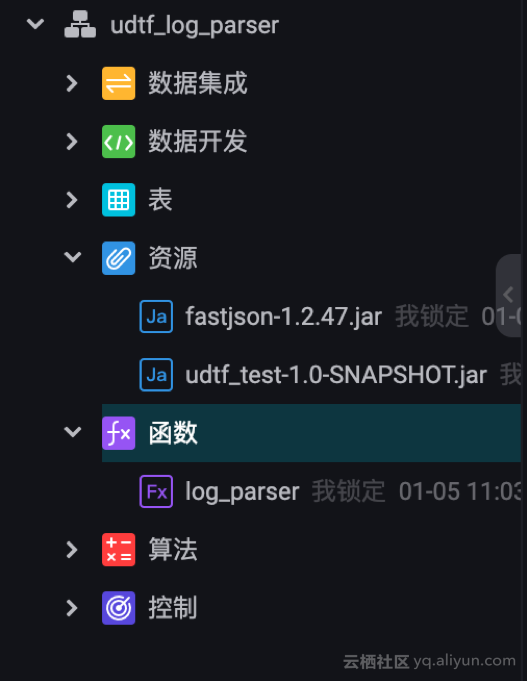
最终的业务流程如下:2个资源 + 1个函数
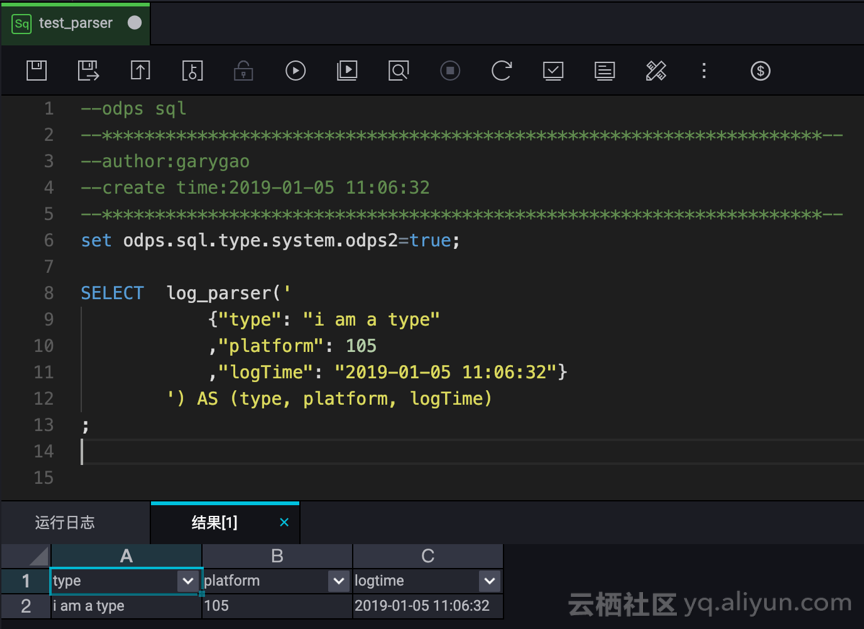
e. 创建 SQL 节点,测试 UDTF
测试成功!JSON 数据解析为三个字段。
![22.gif]()
set odps.sql.type.system.odps2=true;
SELECT log_parser('
{"type": "i am a type"
,"platform": 105
,"logTime": "2019-01-05 11:06:32"}
') AS (type, platform, logTime)
;
注意:Int 为 MaxCompute 2.0 支持的新数据类型,需要设置 odps.sql.type.system.odps2=true,运行时,两个语句全部选中,再执行。