
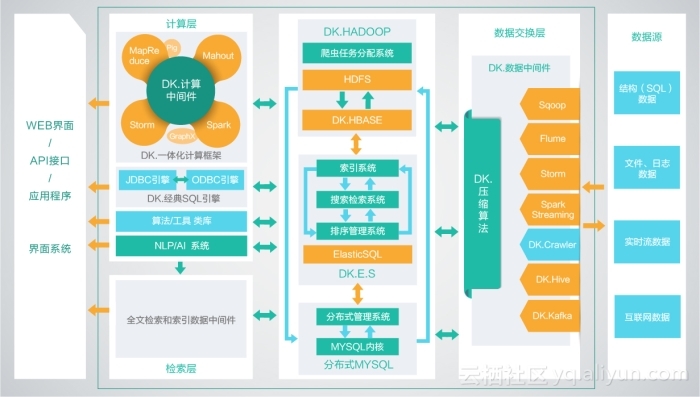

自定义hadoop map/reduce输入文件切割InputFormat
hadoop会对原始输入文件进行文件切割,然后把每个split传入mapper程序中进行处理,FileInputFormat是所有以文件作为数据源的InputFormat实现的基类,FileInputFormat保存作为job输入的所有文件,并实现了对输入文件计算splits的方法。至于获得记录的方法是有不同的子类进行实现的。 那么,FileInputFormat是怎样将他们划分成splits的呢?FileInputFormat只划分比HDFS block大的文件,所以如果一个文件的大小比block小,将不会被划分,这也是Hadoop处理大文件的效率要比处理很多小文件的效率高的原因。 hadoop默认的InputFormat是TextInputFormat,重写了FileInputFormat中的createRecordReader和isSplitable方法。该类使用的reader是LineRecordReader,即以回车键(CR = 13)或换行符(LF = 10)为行分隔符。 但大多数情况下,回车键或换行符作为输入文件的行分隔符并不能满足我们的需求,通常用户很有可能会输入回车键...