


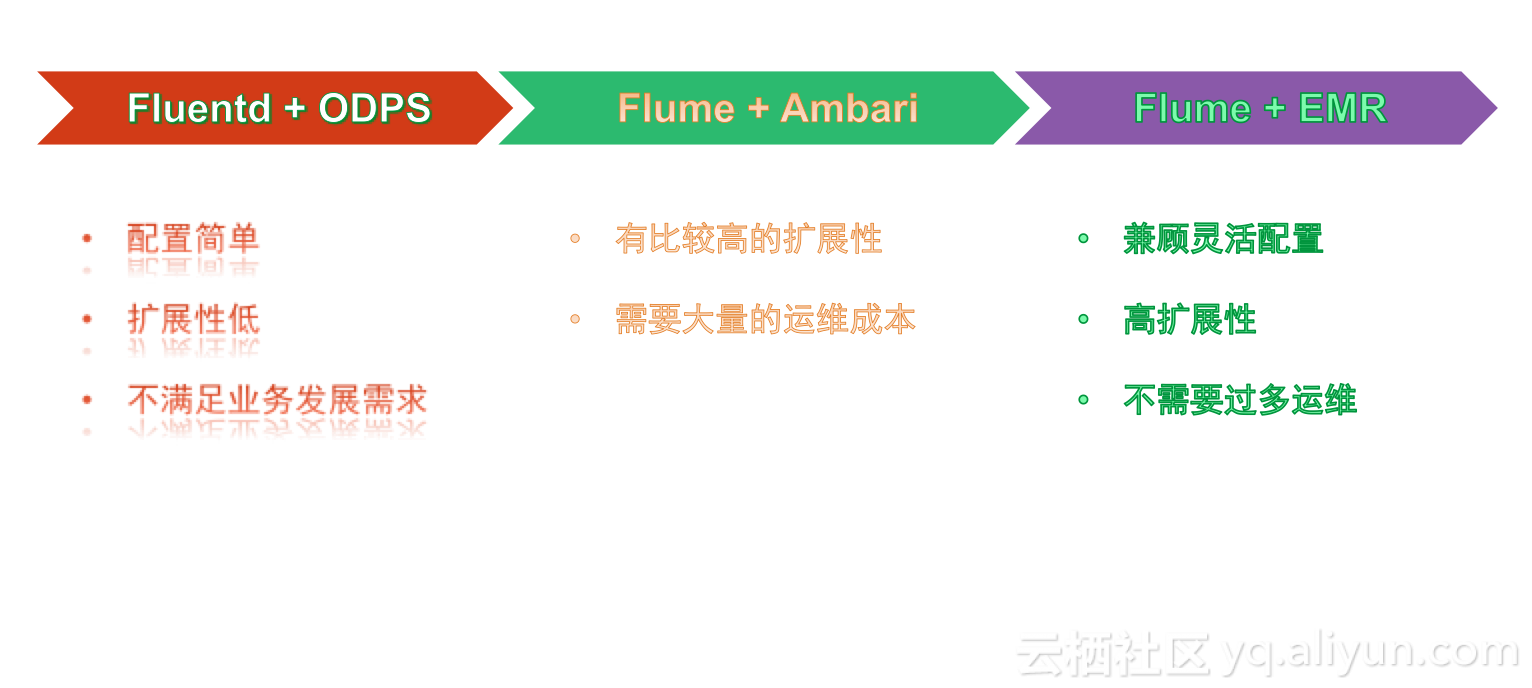
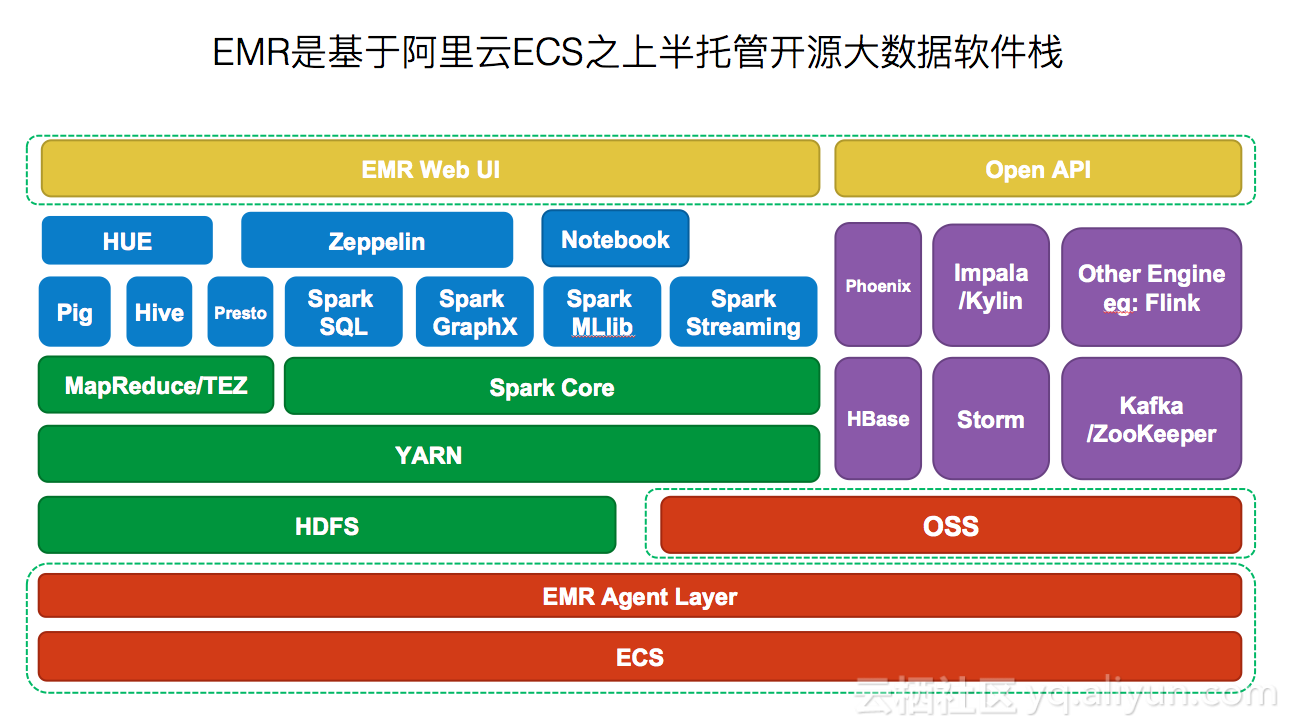

regionserver启动后又关闭
欢迎关注大数据和人工智能技术文章发布的微信公众号:清研学堂,在这里你可以学到夜白(作者笔名)精心整理的笔记,让我们每天进步一点点,让优秀成为一种习惯! 今天启动hbase shell,输入hbase命令时报错: ERROR [regionserver/regionserver1/172.18.0.61:16020] reggionserver.HRegionServer: Shutdown / close of WAL failed: org.apache.hadoop.hdfs..server.namenode.LeaseExpiredException: No lease on /hbase/WALs/regionserver1.shaadownet,16020,1522226971485/regionserver1.shadownet%2C16020%2C1522226971485.defauult.1522237781682 (inode 16832): File does not exist. Holder DFSClient_NONMAPREDUUCE_-210251064...