概述
集群资源是非常有限的,在多用户、多任务环境下,需要有一个协调者,来保证在有限资源或业务约束下有序调度任务,YARN资源调度器就是这个协调者。
YARN调度器有多种实现,自带的调度器为Capacity Scheduler和Fair Scheduler。YARN资源调度器均实现Resource Scheduler接口,是一个插拔式组件,用户可以通过配置参数来使用不同的调度器,也可以自己按照接口规范编写新的资源调度器。默认情况下,YARN采用的是Capacity Scheduler调度器。
Capacity Scheduler
Capacity Scheduler简介
Capacity Scheduler(计算能力调度器)是由Yahoo贡献的,主要是解决HADOOP-3421中提出的,在调度器上完成HOD(Hadoop On Demand)功能,克服已有HOD的性能低效的缺点。它适合于多用户共享集群的环境的调度器。在多用户的情况下,达到最大化集群的吞吐和利用率的目的。
Capacity 调度器允许多个组织共享整个集群,每个组织可以获得集群的一部分计算能力。通过为每个组织分配专门的队列,然后再为每个队列分配一定的集群资源,这样整个集群就可以通过设置多个队列的方式给多个组织提供服务了。除此之外,队列内部又可以垂直划分,这样一个组织内部的多个成员就可以共享这个队列资源了,在一个队列内部,资源的调度是采用的是先进先出(FIFO)策略。
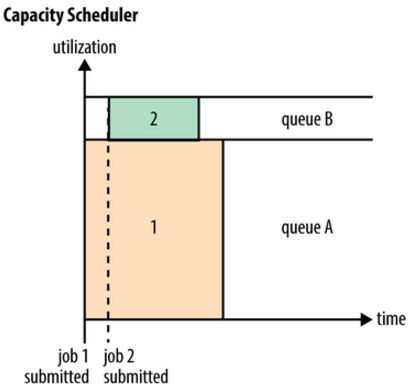
一个job可能使用不了整个队列的资源。然而如果这个队列中运行多个job,如果这个队列的资源够用,那么就分配给这些job,如果这个队列的资源不够用了呢?其实Capacity调度器仍可能分配额外的资源给这个队列,这就是弹性队列(queue elasticity)的概念。
在正常的操作中,Capacity调度器不会强制释放Container,当一个队列资源不够用时,这个队列只能获得其它队列释放后的Container资源。当然,我们可以为队列设置一个最大资源使用量,以免这个队列过多的占用空闲资源,导致其它队列无法使用这些空闲资源,这就是弹性队列需要权衡的地方。
![capacitySheduler]()
Capacity Scheduler特点
- 容量保证:每个队列都分配了一部分容量,他们可以支配着部分资源。提交到特定队列的应用程序,可以使用该队列的资源。管理员可以配置每个队列容量的最低保证和资源使用上限。
- 安全性:每个队列都有严格的ACL(控制访问列表),它可以控制用户提交应用程序到特定队列上。同时保证用户不能查看或修改其它用户提交的应用程序,并且队列管理员和集群系统管理员可以对其进行维护。
- 灵活性:队列的空闲资源可以分配各其它队列使用。如果某队列的资源分配未达到队列资源使用上限,在其需要更多资源时,将分配其它队列的空闲资源给该繁忙队列。
- 多用户性:支持多用户共享集群,一些列的综合设置可以防止单个应用程序、用户或队列独占队里或集群的全部资源。
- 可操作性:支持运行时配置和队列停止。队列的属性(例如:资源容量分配、ACL等)可以在运行时由管理员以一种安全的方式更改,从而减少了对用户的影响。同时提供给管理员和用户一个界面,用于查看当前队列资源的使用情况。管理员可以在集群运行时添加新队列,可以在停止运行的队列的同时保证队列上的任务运行完成,而新的任务不能提交到该队列上。注意现在不支持在运行时删除队列,如果需要删除队列,需要重启集群。
- 层级队列:层级队列可确保资源在该组织的子队列之间被共享,从而提供更多的可控制性和预测性。
- 基于资源的调度:支持资源密集型的应用程序,允许应用程序使用的资源量高于默认值,从而该调度器可以支持不同资源需求的应用程序。目前只支持内存资源的配置,通过配置可支持CPU资源。
Fair Scheduler
Fair Scheduler是由Facebook贡献的,是Hadoop上一个可插拔式的调度器,允许YARN应用程序在一个大的集群上公平地共享资源。
公平调度是一种为应用程序分配资源的方法,多用户的情况下,强调用户公平地使用资源。默认情况下Fair Scheduler根据内存资源对应用程序进行公平调度,通过配置可以修改为根据内存和CPU两种资源进行调度。当集群中只有一个应用程序运行时,那么此应用程序占用这个集群资源。当其他的应用程序提交后,那些释放的资源将会被分配给新的应用程序,所以每个应用程序最终都能获取几乎一样多的资源。
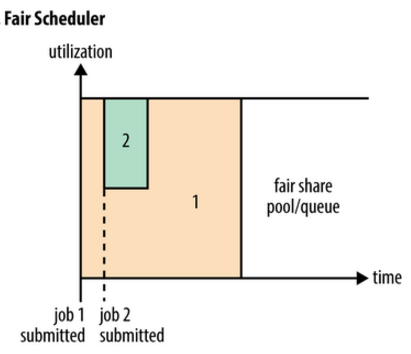
在Fair Scheduler中,不需要预先占用一定的系统资源,Fair Scheduler会动态调整应用程序的资源分配。例如,当第一个大job提交时,只有这一个job在运行,此时它获得了所有集群资源;当第二个小任务提交后,Fair调度器会分配一半资源给这个小任务,让这两个任务公平的共享集群资源。
需要注意的是,在下图Fair Scheduler中,从第二个任务提交到获得资源会有一定的延迟,因为它需要等待第一个任务释放占用的Container。小任务执行完成之后也会释放自己占用的资源,大任务又获得了全部的系统资源。
![FairScheduler]()
Fair Scheduler将应用程序支持以队列的方式组织,这些队列之间公平的共享资源。默认,所有的用户共享一个队列。如果应用程序在请求资源时指定了队列,那么请求将会被提交到指定的队列中。也可以通过配置,根据用户名称来分配队列。在每个队列内部,应用程序基于内存公平共享或FIFO共享资源。
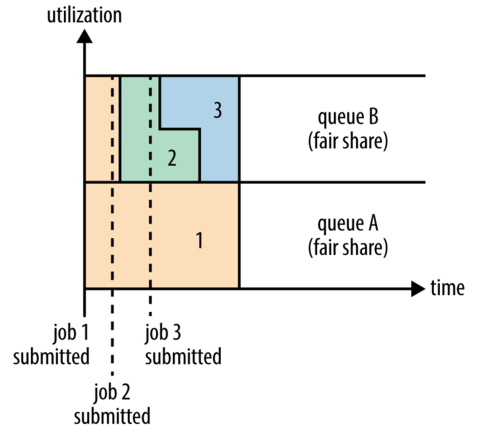
举个例子,假设有两个用户A和B,他们分别拥有一个队列。当A启动一个job而B没有任务时,A会获得全部集群资源;当B启动一个job后,A的job会继续运行,不过一会儿之后两个任务会各自获得一半的集群资源。如果此时B再启动第二个job并且其它job还在运行,则它将会和B的第一个job共享B这个队列的资源,也就是B的两个job会用于四分之一的集群资源,而A的job仍然用于集群一半的资源,结果就是资源最终在两个用户之间平等的共享。过程如下图所示:
![FairScheduler4Queue]()
Fair Scheduler允许为队列分配担最小的共享资源量,这样可以保证某些用户、groups或者应用程序总能获取充足的资源。当一个队列中有正在运行的应用程序时,它至少能够获取设置的最小资源,当队列中无任务时,它的资源将会被拆分给其他运行中的任务。
Fair Scheudler在默认情况下允许所有的任务运行,但是这也可以通过配置文件来限制每个用户下和每个队列下运行的任务个数。处于限制时,新提交的任务不会提交失败,而是在Scheduler queue中等待,直到先前的任务结束,再执行。
Fair Scheduler vs Capacity Scheduler
- 相同点
- 都支持多用户多队列,即:适用于多用户共享集群的应用环境
- 都支持层级队列
- 支持配置动态修改,更好的保证了集群的稳定运行。
- 均支持资源共享,即某个队列中的资源有剩余时,可共享给其他缺资源的队列
- 单个队列均支持优先级和FIFO调度方式
- 不同点
Capacity Scheduler与Fair Scheduler最大的区别为调度策略的不同
- Capacity Scheduler的调度策略是,可以先选择资源利用率低的队列,然后在队列中通过FIFO或DRF进行调度。
- Fair Scheduler的调度策略是,可以使用公平排序算法选择队列,然后再队列中通过Fair(默认)、FIFO或DRF的方式进行调度。
本文转自 张冲andy 博客园博客,原文链接:http://www.cnblogs.com/andy6/p/8417809.html ,如需转载请自行联系原作者