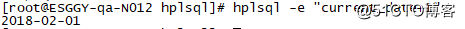环境要求:
Java 1.6 及以上版本
Hadoop 1.x 或 2.x版本
本例环境信息:
Linux version:CentOS release 6.8 (Final)
Hadoop version:hdp 2.4.0.0-169
Java version:jre-1.8.0-openjdk.x86_64
下载hpl/sql安装包
下载地址:http://www.hplsql.org/download
下载完成后上传到linux平台
解压安装包并安装到/opt:
tar -zvxf hplsql-0.3.31.tar.gz -C /opt
in -s /opt/hplsql-0.3.31 /opt/hplsql
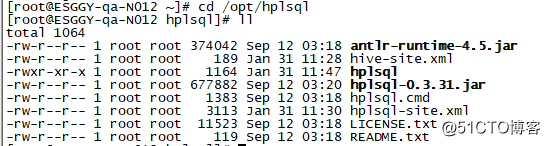
解压后包含以下文件
hplsql
hplsql.cmd
hplsql-x.x.x.jar
hplsql-site.xml
antlr-runtime-4.5.jar
![LINUX下安装HPL/SQL]()
修改权限:
chmod +x /opt/hplsql
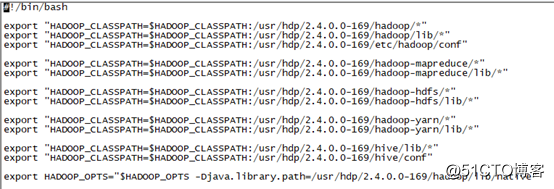
配置CLASSPATH
cd /opt/hplsql
vi hplsql
如果是hadoop为CDH
删除hplsql文件中所有的export “HADOOP_CLASSPATH=…”
添加export “HADOOP_CLASSPATH=/opt/cloudera/parcels/CDH/jars/*”
如果是hadoop为HDP
检查/usr/hdp/x.x.x.x-x目录,并修改hplsql文件中所有的export “HADOOP_CLASSPATH=…”路径为/usr/hdp/x.x.x.x-x对应的路径。
![LINUX下安装HPL/SQL]()
其他版本的hadoop,请检查/usr/lib下是否有hadoop的jars,并在phlsql文件做对应的修改。
测试是否安装成功
/opt/hplsql –version
cd /opt/hplsql
./hplsql –version
![LINUX下安装HPL/SQL]()
如果以上命令能返回hplsql的版本信息,则表示安装成功。
添加hplsql到PATH变量
export PATH=$PATH:/opt/hplsql
设置PATH后就可以直接通过hplsql命令调用HPL/SQL
Hplsql <option>
![LINUX下安装HPL/SQL]()
配置
cd /opt/hplsql
vi hplsql-site.xml
修改
<property>
<name>hplsql.conn.init.hive2conn</name>
<value></value>
</property>
为:
<property>
<name>hplsql.conn.init.hive2conn</name>
<value>
set mapred.job.queue.name=dev;
set hive.execution.engine=mr;
use sales_db;
</value>
</property>
运行HPL/SQL
hplsql -e “CURRENT_DATE+1”
hplsql -e “SELECT * FROM src LIMIT 1”
hplsql -f script.sql
![LINUX下安装HPL/SQL]()
在shell脚本中使用HPL/SQL
从HPL/SQL脚本中获取一个值
MDATE=$(hplsql -e “NVL(MIN_PARTITION_DATE(sales,local_dt,code=’A’),’1970-01-01’)”)
START=$(hplsql -e ‘CURRENT_DATE – 1’)
本文转自 天黑顺路 51CTO博客,原文链接:http://blog.51cto.com/mjal01/2067249,如需转载请自行联系原作者