容器通常是为了解决一个单一的、特定的问题;如微服务,但在现实世界中,通常需要多个容器,来实现一个完整的解决方案。在这篇文章中,我们将谈论结合多个容器集成进单一的Kubernetes节点,即容器互联通信。
什么是Kubernetes节点?
首先让我们解释一下容器节点是什么。容器节点即POD,它是可以由Kubernetes部署和管理的最小单位。换句话说,如果你需要运行在Kubernetes的一个容器,你需要创建一个POD。同时,一个POD可以容纳多个容器,通常是因为这些容器是相对紧密耦合的。如何紧密耦合?好吧,这样想:POD中的容器代表了原来在同一物理服务器上运行的进程。
这是有道理的。因为在许多方面,一个POD就像一台服务器。例如,每个容器可以访问在POD其他容器,就像访问本地主机上的不同端口。
Kubernetes为什么将POD作为最小的可部署单元,而不是一个单一的容器?
虽然直接部署单个容器似乎比较简单,但是有充分的理由需要添加一个由POD表示的抽象层。容器是一个实体,它指一个特定的事物。这个具体的事物可能Docker容器,但它也可能是一个rkt的容器,或由virtlet管理的虚拟机。每一种都有不同的要求。
更重要的是,Kubernetes需要更多的信息来管理一个容器,如重新启动策略,它定义了当容器终止时,或活性的探针时,进行哪些动作;从应用程序的角度,它定义了检测动作,判断容器进程是否还活着,如Web服务器响应HTTP请求。
区别于在现有的“实体”上超载附加属性,Kubernetes决定使用一个新的实体,POD。POD可以被认为是逻辑容器,包含一个或多个容器(包装),作为一个单一的实体被管理。
Kubernetes为什么让一个POD里放置多个容器?
POD中的容器运行在“逻辑主机”上;它们使用相同的网络namespace(换句话说,相同的IP地址和端口空间),以及相同的IPC名称空间。它们还可以使用共享卷。这些属性使得这些容器能够有效地通信,确保数据本地化。此外,POD使您可以以一个单元的模式管理几个紧密耦合的应用程序容器。
如果应用程序需要在同一主机上运行多个容器,为什么不将单个容器与所需的所有内容组合起来呢?首先,这样做很可能违反“一个容器一个进程”的原则。这很重要,因为同一个容器中有多个过程,系统将很难排错。因为来自不同过程的日志将被混合在一起,很难管理进程的生命周期,例如当父进程死亡后处理“僵尸”的过程。其次,一个应用程序使用多个容器将使系统更简单、更透明,并能使软件依赖关系解耦。同时,更精细颗粒的容器可以在团队之间重复使用。
多容器POD的用例
多容器POD的主要用途是支持主要应用程序的共定位、共管辅助进程。在POD中使用辅助进程,有一些通用的模式:
●跨斗容器“帮助”主容器。示例包括日志或数据更改监视程序、监视适配器等。例如,日志监视程序可以由一个团队创建一次,并在不同的应用程序中重用。另一个例子,一个跨斗容器是一个文件或数据装载器,为主容器生成数据。
●代理、网桥和适配器将主容器与外部世界连接起来。例如,Apache HTTP服务器或Nginx可以提供静态文件。它还可以充当主容器中Web应用程序的反向代理,以记录和限制HTTP请求。另一个例子是辅助容器,它将请求从主容器路由到外部网络。这使得主容器可以连接到本地主机访问,例如,外部数据库,但不需任何的服务发现。
虽然你可以在单个POD中托管多层应用程序(如WordPress),但推荐的方法是为每个层使用单独的POD,原因很简单,你可以独立地扩展每层,并将它们分布在集群节点上。
Pod中容器间的通信
在一个POD中有多个容器,使它们相对简单地进行通信。他们可以用几种不同的方法做这件事。
在Kubernetes Pod中共享卷
在Kubernetes,你可以使用一个共享的Kubernetes卷作为一种简单而有效的方式,在一个POD内容器间进行数据共享。在大多数情况下,在主机上使用与容器内所有容器共享的目录,是足够的。
Kubernetes卷数据支持容器重启,但这些卷与POD寿命一样。这意味着卷容量(所拥有的数据)和POD存在时间一样。如果那个POD被删除,即使同类更换创建,共享卷被销毁和创建。
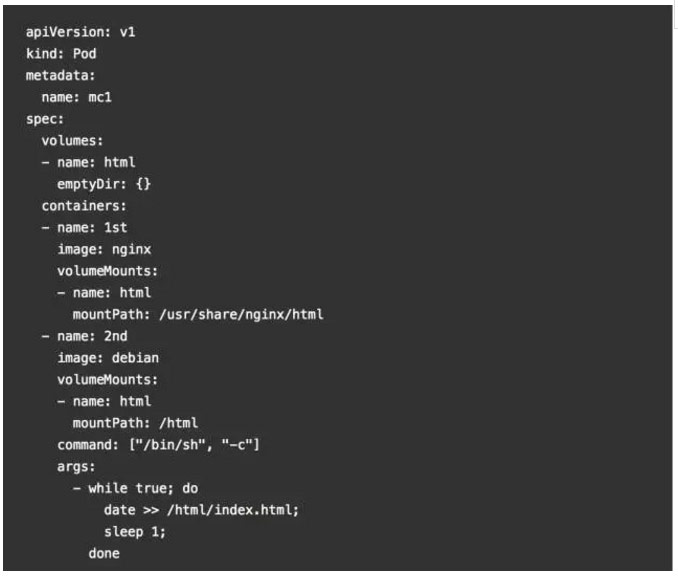
一个使用共享卷的标准多容器POD的用例是,在一个容器写日志和其他文件到共享目录中,其他容器从这个共享目录中可以读取数据。例如,我们可以创建一个POD:
![]()
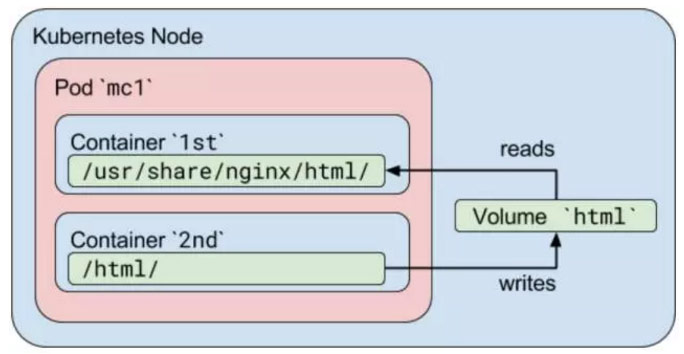
在这个例子中,我们定义了一个名为HTML的卷。它的类型是emptyDir,这意味着当一个POD被分配到一个节点时,卷先被创建,并只要Pod在节点上运行时,这个卷仍存在。正如名字所说,它最初是空的。第一容器运行nginx的服务器并将共享卷挂载到目录/ usr /share/ Nginx /HTML。第二容器使用Debian的镜像,并将共享卷挂载到目录/HTML。每一秒,第二容器添加当前日期和时间到index.html文件中,它位于共享卷。当用户发出一个HTTP请求到POD,nginx的服务器读取该文件并将其传递给响应请求的用户。
![]()
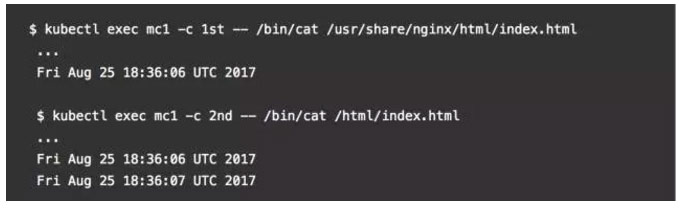
你可以检查一下,POD可以通过暴露nginx端口并使用您的浏览器访问它,或通过直接检查容器中的共享目录:
![]()
进程间通信(IPC)
一个POD里的容器共享相同的IPC命名空间,这意味着他们也可以互相使用标准进程间通信,如SystemV信号系统或POSIX共享内存。
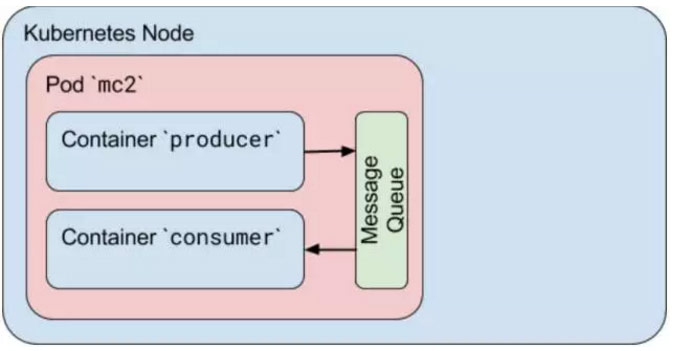
在下面的示例中,我们定义了一个带有两个容器的POD。我们使用相同的容器镜像。第一个容器,生产者,创建一个标准的Linux消息队列,写一些随机消息,然后写一个特殊的退出消息。第二个容器,消费者,打开相同的消息队列以便读取和读取消息,直到接收到退出消息。我们还将重启策略设置为“从不”,所以只有在两个容器都终止后POD停止。
![]()
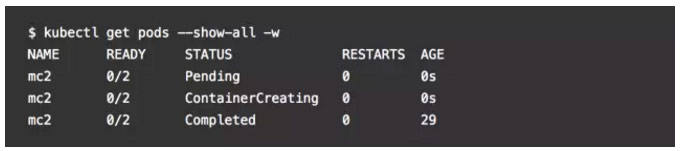
为了验证这一点,使用kubectl 创建POD,并观察POD状态:
![]()
现在您可以检查每个容器的日志,并验证第二个容器接收了来自第一个容器的所有消息,包括退出消息:
![]()
![]()
不过,这个POD有一个主要问题,它与容器的启动有关。
容器依赖项和启动顺序
目前,POD中的所有容器都是并行启动的,没有办法定义一个容器必须在其他容器之后启动。例如,在IPC示例中,第二个容器可能在第一个容器启动之前已经结束,并创建了消息队列。在这种情况下,第二个容器将失败,因为它期望消息队列已经存在。
一些方案提供某种程度的对容器启动控制,如Kubernetes初始化容器,开始第一次(依次),正在开发中,但在云的原生环境,最好准备好直接控制之外的失败的应对计划。例如,解决此问题的一种方法是更改应用程序以等待创建消息队列。
容器间网络通信
一个POD里的容器都可以通过“localhost”访问;他们使用相同的网络名称空间。另外,对于容器,可观察的主机名是POD的名称。因为容器共享相同的IP地址和端口空间,所以您应该在容器中使用不同的端口来进行连接。换句话说,POD中的应用程序必须协调端口的使用。
在下面的例子中,我们将创建一个多容器的POD,nginx运行在POD一个容器中作为反向代理,为另一个运行一个简单的Web应用程序中的第二容器提供支持。
步骤1、用nginx的配置文件创建一个configmap。通过HTTP端口80输入的请求将被转发到本地端口5000去:
步骤2、创建一个多容器POD,其上运行2个容器,分别运行简单的Web应用程序和Nginx。注意,POD,我们只定义了Nginx的端口80。端口5000不能被POD外部访问。
步骤3、使用nodeport服务来暴露POD:
步骤4、标识并转发给POD节点上的端口:
现在,您可以使用浏览器(或curl)导航到节点的端口,通过反向代理访问Web应用程序,如:
http://myhost:31418
这个请求将被转发到webapp容器的5000端口。
在一个POD中暴露多个容器
虽然这个示例展示了如何使用单个容器访问POD中的其他容器,但在一个POD中的几个容器在POD不同的端口上侦听是很常见的——所有这些端口都需要公开。要做到这一点,你可以创建一个多端口暴露的服务,或者你可以为每一个想暴露的端口创建一个单一的服务。
本文转自中文社区-多容器POD及Kubernetes容器通信