感谢 大家的支持 你们的阅读评价就是我最好的更新动力 我会坚持吧排版做的越来越好
每天坚持 一天一篇 点个订阅吧 灰常感谢 当个死粉也阔以![]()
![]()
Python人工智能从入门到精通
函数:
tyup(x) 用来返回x对应的数据类型
range(x) 返回可迭代对象
sublime编辑器:
中文空格查找方法 空格中间没有小点
行首小黑点 语法不规范 大黑点语法错误 中文空格也会出错
元组 tuple:
元组是不可变的序列,同list一样,元组可以存放任意数据类型的容器
元组的表示方法:
用小括号()括起来,单个元素括起来后面加 “,”逗号区分单个对象还是元组
元组的小括号可以省略 但元素低于2个 “,” 不能省略
元组的构造函数:
tuple() 生成一个空元组,等同于()
tuple(iterable) 用可迭代对象生成一个元组
元组的运算:
+ += * *=
< > <= >= == !=
in , not in
索引[ ], 切片[ : ] [ : : ]
+ 拼接元组
* 生成重复元组
元祖的比较:
规则与列表规则完全相同
in , not in
规则与列表规则完全相同
索引和切片:
索引取值和切片取值的规则与列表相同
元组不支持索引赋值和切片赋值(因为元组是不可变的序列)
元组的方法:
T.index(v[, begin[, end]]) 返回对应圆的索引下表
T.count(x) 返回对应元素个数
序列相关函数:
len(x)、max(x)、min(x)、sum(x)、any(x)、all(x)
str(x) 创建字符串
构造函数:
(构造函数一定是他的类型名 返回对应类型)
list(inerable) 创建列表
tuple(inerable) 创建元组
reversed(x) 返回反向顺序的可迭代对象
sorted(inerable,key = None,reverse = false) 返回已排列列表
inerable:可迭代对象 (key = None,reverse = false:后面将)
例如:
t = (4, 5, 8, 3, 2, 1)
L = [x for x in reversed(t)]
print(L)
容器小结:
字符串str # 不可变序列, 只能存字符
列表 list # 可变序列,可存任意数据
元组 tuple #不可变序列,可以存任意数据
字典 dict:
1.字典是一种可变容器,可以储存任意类型数据
2.字典中的每个数据都是用“键”(key)进行索引
,而不像序列可以用整数下标来进行索引
3.字典中的数据没有先后关系,字典的储存是无序的
4.字典的数据以键(key)- 值(value)对形式进行映射储存
5.字典的键不能重复,只能用不可变类型作为字典的键
字典的字面值的表示方法:
字典的表示方式是以{ }括起来的,以冒号开头“:”
分隔键-值对,各键-值对之间用逗号分开
创建字典:
d = { } #空字典
d = { “Nemo”:“yang”,“age”: 35} #非空字典
键:“Nemo”值:“yang”(一个键值对)
键(只能用不可变类型) 值可以任意类型
字符串str 列表 list 元组 tuple 字典 dict 都是可以任意包含关系的
字典的构造函数dict:
dict() 生成一个字的字典 等同于{ }
dict(iterable) 用可迭代对象初始化一个字典
dict(** keargs) 用关键字传参形式创建字典
关键字传参:(dict(name = “tarena”,age = 15))
索引:d [key ]
字典的key:
不可变数据类型:
bool,int,float,complex,str,tuple,frozeset,bytes
可变数据类型有四种:
list 列表
dict 字典
set 集合
bytearray 字节数组
字典的基本操作:
键索引 用 [ ] 运算符获取字典内“键”对应的值
也可以修改 字典[ 键 ] = 值
如果键不存在时,创建键,并绑定对应的值
当存在时,修改键绑定的值
del 字典 [ 键 ] (删除元素)
字典的成员资格判断 in 运算符:
可以用 in 运算符判断一个键是否存在于字典中,如果存在则返回true
否则返回false
not in 与 in 结果相反
例如:
d = {"name": "Gabriel", "age": 20}
if "name" in d:
print("name 在字典中 ")
只判断键 不判断值
字典的迭代访问:
字典是可迭代对象,字典只能对键进行迭代访问
例如:
d = {"name":"tarena", age: 15}
for x in d:
print(x, d[ x ])
内建函数:(内建:代表系统内直接有的函数)
len(d) 返回的是键值对个数
max(d) 返回的是键最大值
min(d) 返回的是键最小值
sum(d) 返回的是键得和
any(d) 一个键为true则为true
all(d)所有键为true 则为true
字典的方法:
函数 说明
D代表字典对象
D.clear() 清空字典
D.pop(key) 移除键,同时返回此键所对应的值
D.copy() 返回字典D的副本,只复制一层(浅拷贝)
D.update(D2) 将字典 D2 (合并)到D中,如果键相同,则此键的值取D2的值作为新值
D.get(key, default) 返回键key所对应的值,如果没有此键,则返回default
D.keys() 返回可迭代的 dict_keys 集合对象(返回键)
D.values() 返回可迭代的 dict_values 值对象(返回值)
D.items() 返回可迭代的 dict_items 对象(返回键值对)
字典推导式:
是用可迭代对象创建字典的表达式
语法:
{键表达式:值表达式 for 变量 in 可迭代对象 if 真值表达式}
if子句可以省略
d = { x:x ** 2 for x in range(10)}
字典VS列表:
1.都是可变对象
2.索引方式不同,列表用整数(下标)索引 ,字典用键(key)索引
3.字典的插入,删除,修改数据的速度可能会快于列表
4.列表的存储是有序的(内存中一般用排列算法),字典的储蓄是无序的(内存中一般用散列算法插入数据)
练习:
1.已知有两个等长的列表 list1 和 list2
以list1中的元素为键,以list2中的元素为值,生成相应的字典
list1 = [1001, 1002, 1003, 1004] list2 = ['Tom', 'Jerry', 'Spike', 'Tyke']
答案:
list1 = [1001, 1002, 1003, 1004]
list2 = ['Tom', 'Jerry', 'Spike', 'Tyke']
d = {list1[x]: list2[x] for x in range(len(list1))}
print(d)
![]()
2.
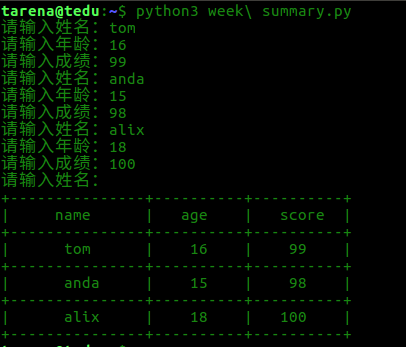
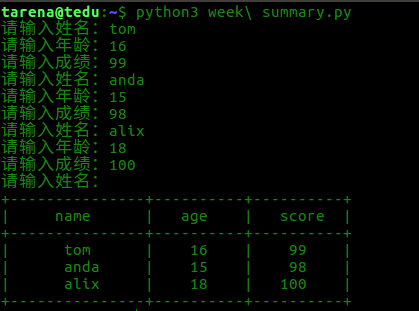
输入任意个学生的姓名,年龄,成绩,每个学生的信息存入字典中,然后放入至列表中,每个学生的信息需要手动输入
当输入姓名为空时结束输入:
如:
请输入姓名: xiaozhang
请输入年龄: 20
请输入成绩: 100
请输入姓名: xiaoli
请输入年龄: 18
请输入成绩: 98
请输入姓名: <回车> 结束输入
要求内部存储格式如下:
[{'name':'xiaozhang', 'age':20, 'score':100},
{'name':'xiaoli', 'age':18, 'score':98}]
打印所有学生的信息如下:
+---------------+----------+----------+
| name | age | score |
+---------------+----------+----------+
| xiaozhang | 20 | 100 |
| xiaoli | 18 | 98 |
+---------------+----------+----------+
答案:
L = []
while True:
n = input("请输入姓名:")
if n == '':
break
a = int(input("请输入年龄:"))
s = int(input("请输入成绩:"))
d = {}
d['name'] = n
d['age'] = a
d['score'] = s
L.append(d)
# print(L)
print("+---------------+----------+----------+")
print("| name | age | score |")
print("+---------------+----------+----------+")
for d in L:
n = d['name'].center(15)
a = str(d['age'])
ac = a.center(10)
s = str(d['score'])
sc = s.center(10)
line = "|%s|%s|%s|" % (n, ac, sc)
print(line)
print("+---------------+----------+----------+")
![]()
![]()