

吴恩达《机器学习》课程总结(5)Octave教程
推荐使用python,本节略。
最近发现了一个好玩的包itchat,通过调用微信网页版的接口实现收发消息,获取好友信息等一些功能,各位可以移步itchat项目介绍查看详细信息。
# -*- coding: utf-8 -*-
import itchat
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
import jieba
import re
from scipy.misc import imread
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
itchat.login()
#登陆网页版微信,需要手机扫码确认
warnings.filterwarnings("ignore")
friends = itchat.get_friends(update=True)
for counter,content in enumerate(friends[1:]):
if counter == 0:
df=pd.DataFrame(content)
df.columns=content.keys()
else:
df.loc[counter]=content.values()
print '获取到%d位好友信息'%counter
df.columns
Index([u'UserName', u'City', u'DisplayName', u'UniFriend', u'MemberList',
u'PYQuanPin', u'RemarkPYInitial', u'Sex', u'AppAccountFlag',
u'VerifyFlag', u'Province', u'KeyWord', u'RemarkName', u'PYInitial',
u'IsOwner', u'ChatRoomId', u'HideInputBarFlag', u'EncryChatRoomId',
u'AttrStatus', u'SnsFlag', u'MemberCount', u'OwnerUin', u'Alias',
u'Signature', u'ContactFlag', u'NickName', u'RemarkPYQuanPin',
u'HeadImgUrl', u'Uin', u'StarFriend', u'Statues'],
dtype='object')
df['City'][df['Province']==u'北京']= u'北京'
df['City'][df['Province']==u'上海']= u'上海'
df['City'][df['Province']==u'重庆']= u'重庆'
#微信对于直辖市将city字段填写为区
plt.figure(figsize = (15,12))
data_temp = df[df['City']!='']
#剔除城市未填写的记录
data_temp = data_temp.groupby(['City'])['UserName'].count().reset_index()
data_temp = data_temp.nlargest(15,'UserName')
data_temp.columns = ['City','Count']
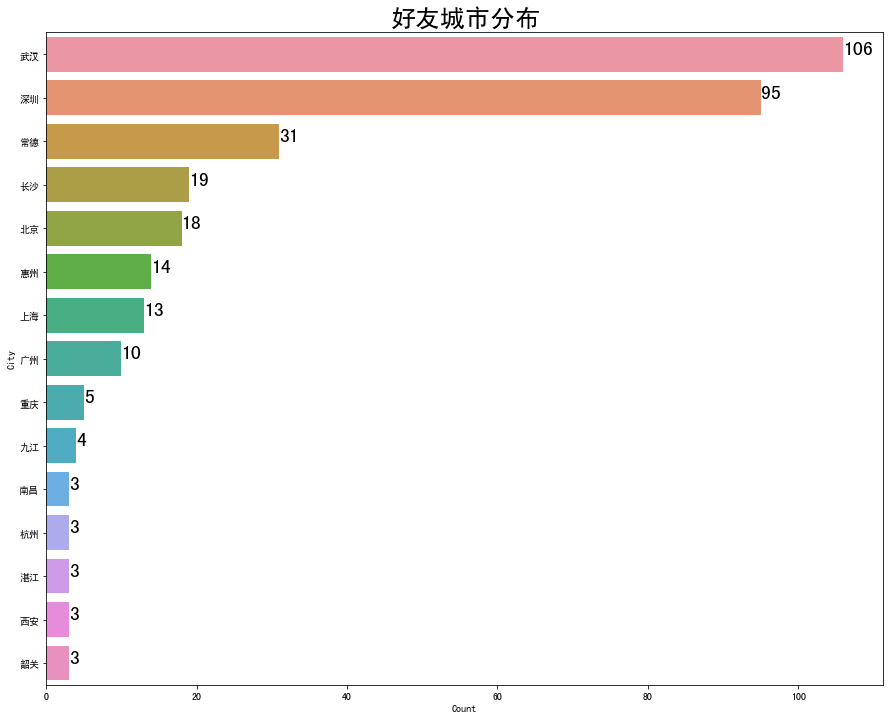
sns.barplot(data=data_temp ,y='City',x='Count')
for y,x in enumerate(data_temp['Count']):
plt.text(x,y,x,fontsize = 20)
plt.title(u'好友城市分布',fontsize =25)
plt.show()
只取了前15位,效果如下:
df['Sex'] = df['Sex'].replace({0:u'性别不明',1:u'男',2:u'女'})
plt.figure(figsize = (15,8))
plt.subplot(1,2,1)
data_temp = df.groupby(['Sex'])['UserName'].count().reset_index()
data_temp = data_temp.sort_values('UserName')
data_temp.columns = ['Sex','Count']
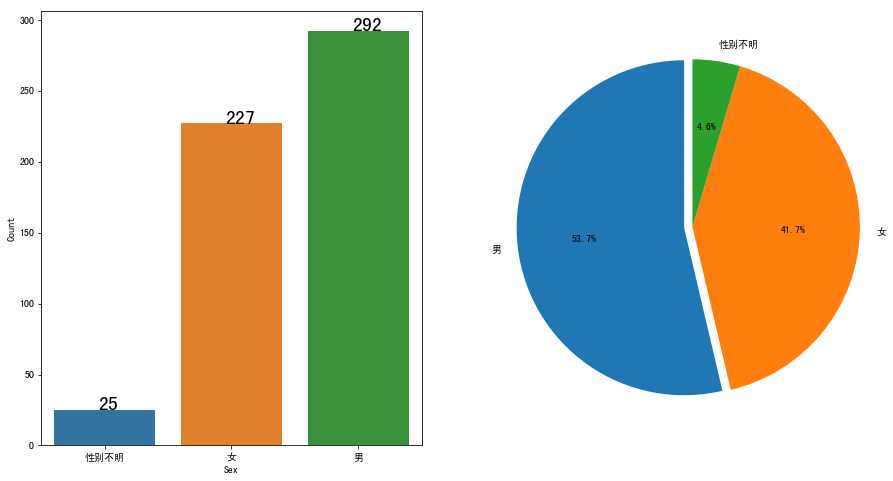
sns.barplot(data=data_temp ,x='Sex',y='Count')
for x,y in enumerate(data_temp['Count']):
plt.text(x-0.05,y,y,fontsize = 20)
plt.subplot(1,2,2)
sex_list = [u'男',u'女',u'性别不明']
countlist = [292,227,25]
explode = (0.05,0,0)
plt.pie(countlist,labels = sex_list,explode =explode,startangle = 90,autopct = '%3.1f%%')
plt.axis('equal')
plt.show()
效果如下:
back_color = imread('tencent.jpg') # 解析该图片
wc = WordCloud(background_color='white', # 背景颜色
max_words=1000, # 最大词数
mask=back_color, # 以该参数值作图绘制词云,这个参数不为空时,width和height会被忽略
max_font_size=100, # 显示字体的最大值
font_path="/Users/tangwenpan/Downloads/simhei.ttf", # 解决显示口字型乱码问题
random_state=42, # 为每个词返回一个PIL颜色
)
text=''
xx= u"[\u4e00-\u9fa5]" #保留汉字
for x in df['Signature']:
pattern = re.compile(xx)
text_temp = pattern.findall(x)
for xxx in text_temp:
text = text +xxx
def word_cloud(texts):
words_list = []
word_generator = jieba.cut(texts, cut_all=False) # 返回的是一个迭代器
for word in word_generator:
if len(word) > 1: #去掉单字
words_list.append(word)
return ' '.join(words_list)
text = word_cloud(text)
wc.generate(text)
# 基于彩色图像生成相应彩色
image_colors = ImageColorGenerator(back_color)
plt.figure(figsize = (15,15))
plt.axis('off')
# 绘制词云
plt.imshow(wc.recolor(color_func=image_colors))
plt.axis('off')
# 保存图片
wc.to_file('comment.png')
print 'comment.png has bee saved!'
使用背景图片
效果如下:
peace~

微信关注我们
转载内容版权归作者及来源网站所有!
低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
为解决软件依赖安装时官方源访问速度慢的问题,腾讯云为一些软件搭建了缓存服务。您可以通过使用腾讯云软件源站来提升依赖包的安装速度。为了方便用户自由搭建服务架构,目前腾讯云软件源站支持公网访问和内网访问。
Spring框架(Spring Framework)是由Rod Johnson于2002年提出的开源Java企业级应用框架,旨在通过使用JavaBean替代传统EJB实现方式降低企业级编程开发的复杂性。该框架基于简单性、可测试性和松耦合性设计理念,提供核心容器、应用上下文、数据访问集成等模块,支持整合Hibernate、Struts等第三方框架,其适用范围不仅限于服务器端开发,绝大多数Java应用均可从中受益。
Rocky Linux(中文名:洛基)是由Gregory Kurtzer于2020年12月发起的企业级Linux发行版,作为CentOS稳定版停止维护后与RHEL(Red Hat Enterprise Linux)完全兼容的开源替代方案,由社区拥有并管理,支持x86_64、aarch64等架构。其通过重新编译RHEL源代码提供长期稳定性,采用模块化包装和SELinux安全架构,默认包含GNOME桌面环境及XFS文件系统,支持十年生命周期更新。
WebStorm 是jetbrains公司旗下一款JavaScript 开发工具。目前已经被广大中国JS开发者誉为“Web前端开发神器”、“最强大的HTML5编辑器”、“最智能的JavaScript IDE”等。与IntelliJ IDEA同源,继承了IntelliJ IDEA强大的JS部分的功能。
扫码在手机上查看文章
扫描二维码,手机阅读更方便
有任何问题或合作意向欢迎联系我们
Email: 99873273@qq.com
QQ: 99873273