咱们的 Python 教程代码已经可以免安装在线运行了。但如果你希望在本地克隆运行环境,请参考本文的步骤说明。
疑惑
这些日子,我用课余时间,忙着把自己知识星球的分享文章转移到语雀平台,以便于订阅用户阅读和获得即时推送。目前该分享空间已经初具规模。
回过头来一看,专栏和微信公众号后台,积攒了不少用户的提问。
例如这位用户问:
为什么我在binder上新建的文件再次打开后就丢失了?
问题来自于我的《如何用iPad运行Python代码?》一文。
咱们用 mybinder ,是为了给读者们提供一个一致性的代码运行环境。
你可以免安装,运行样例代码。可以修改代码重新运行,甚至可以上传数据文件,做自己的分析。
我需要补充说明一个重要事项—— mybinder 为咱们提供的 Python 运行环境资源,是共享的,并非永久独占空间。
每个同学,打开相同的一个链接后,mybinder 都开启一个独立的环境,大家互不干扰。
但是,Python 环境的运行,是需要后台的资源支持的。
你每打开一个 mybinder 的链接,后台都要给你提供对应的 CPU、内存、硬盘等一系列资源。
如果这些资源被大量用户长期占用,平台无法承受。新的用户也就无法再加入使用了。
mybinder 平台和用户的约定,是如果你超过十分钟“不活跃”(inactivity),系统就会关闭你的会话(session),以回收资源,服务更多有需要的用户。
你运行结束关闭浏览器,超过10分钟,再用该链接重新访问,所做的改动自然就都不见了。
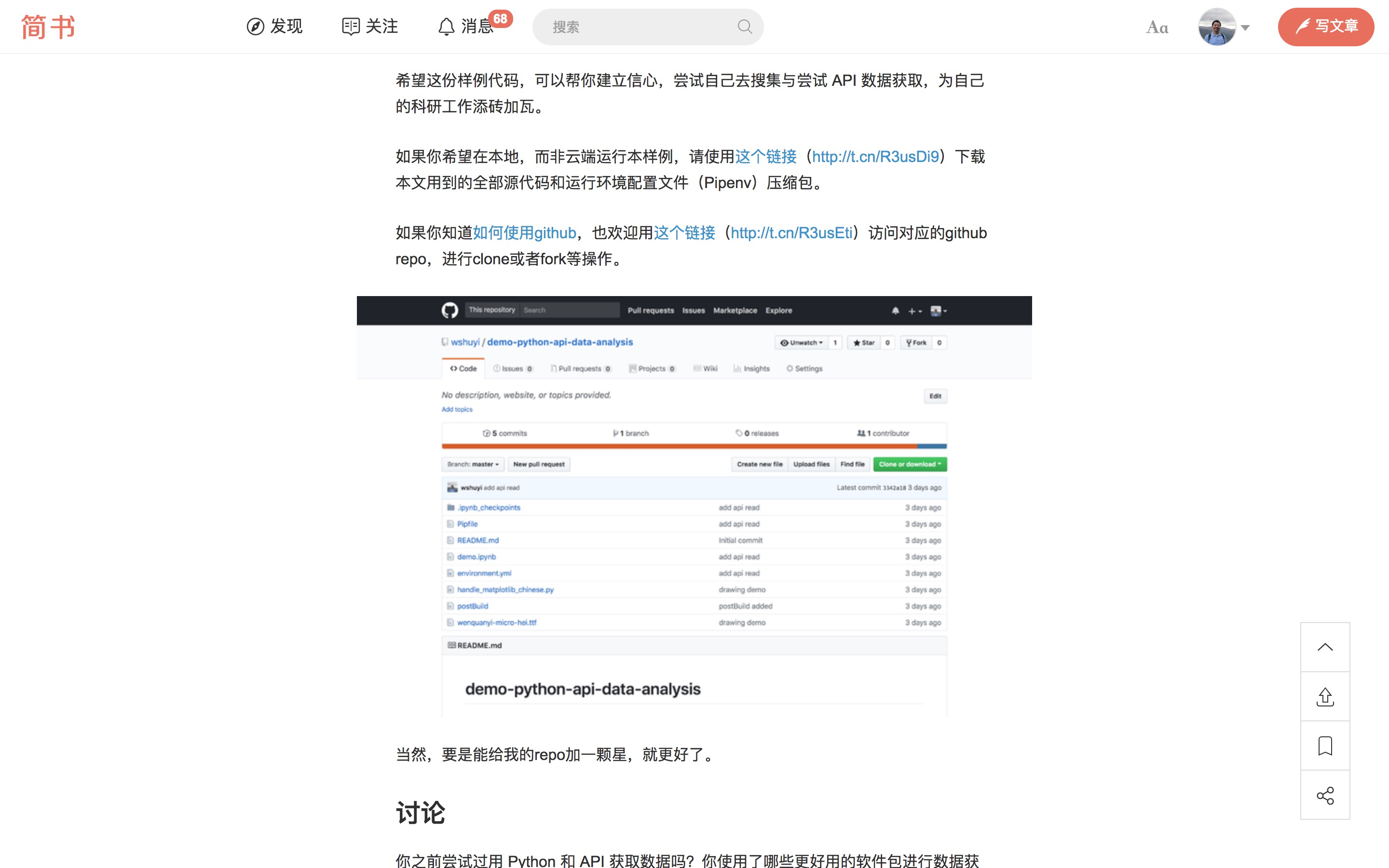
也正因如此,我才在教程的末尾,为你提供了源代码的 github repo 地址。
你可以选择在自己的机器上,克隆教程 Python 运行环境。
哪些情况下,你会需要在本地克隆 Python 运行环境呢?
如果你的数据比较大,或者安全性要求较高,上传到云端不方便;
如果你怕因为网络稳定性的原因,导致代码运行中途网络出现问题,前功尽弃;
如果你运行的深度学习模型,需要 GPU 或者大容量内存的支持……
遇到上述情况,不要紧。
下面我给你介绍如何使用 pipenv ,方便地克隆教程指定的 Python 运行环境,在本地运行 Jupyter Notebook。
流程
咱们以《如何用 Python 和 API 收集与分析网络数据?》这篇文章为例。
文章结尾部分,我给你提供了对应的 github repo 的代码地址(http://t.cn/R3usEti)。
你也可以直接通过这个链接(http://t.cn/R3usDi9),直接下载包含源代码与运行环境的压缩包。
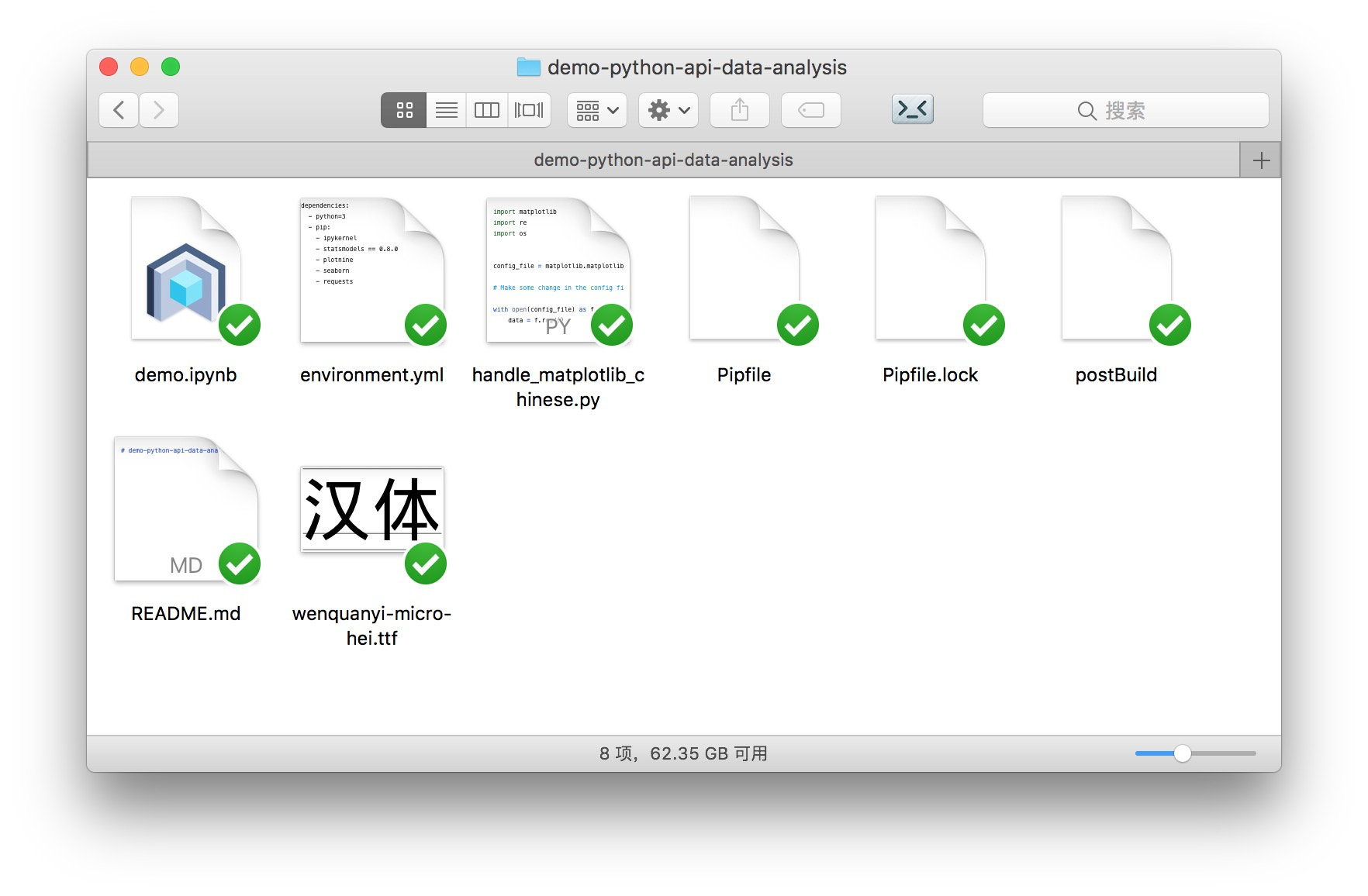
解压之后,你会看到目录中包含以下配置相关文件:
- environment.yml
- postBuild
- Pipfile
其中 environment.yml 和 postBuild 是为 mybinder 使用的。本地克隆运行环境的时候,你可以忽略它们。
请注意其中的 Pipenv 文件。
我们打开 Pipenv 文件,看看内容:
[[source]]
url = "https://pypi.org/simple"
verify_ssl = true
name = "pypi"
[packages]
ipykernel = "*"
plotnine = "*"
requests = "*"
[dev-packages]
[requires]
python_version = "3.6"
其中 requires 区域,说明了本教程使用的环境,是 Python 3.6 版本。
packages 区域,告诉 pipenv ,需要给我们准备的软件包都有哪些。
下面我们看看如何用 pipenv 克隆运行环境。
你需要检查是否已经安装了 Anaconda 3。
如果你还没有安装,请参考我之前为你制作的这篇教程 《如何安装Python运行环境Anaconda?(视频教程)》把它安装好,并且学习如何在终端进入解压后的压缩包。
我把后续的详细操作步骤,录了一段视频,你可以直接点开这个链接(http://t.cn/R1cWIWr),播放该视频。
如果你之前有安装经验,也可以根据下面的文字说明操作。
之后,执行以下语句:
pip install pipenv
这会为我们安装 pipenv 工具,以便处理 Pipfile。
第二步,执行:
pipenv install --skip-lock
这个命令,可以让 Python 根据我们目前的 Pipenv 配置,自动构建环境,并且从网上把所有需要用到的依赖软件包,都弄下来,安装好。
第三步,执行:
pipenv run python -m ipykernel install --user --name=wangshuyi
这条命令,帮你给 Jupyter Notebook ,安装一个核心组块,把你刚才安装的这些软件包信息,都放在这个组块里。
为了便于在系列教程中重复使用代码,我给这个组块命名为 wangshuyi。
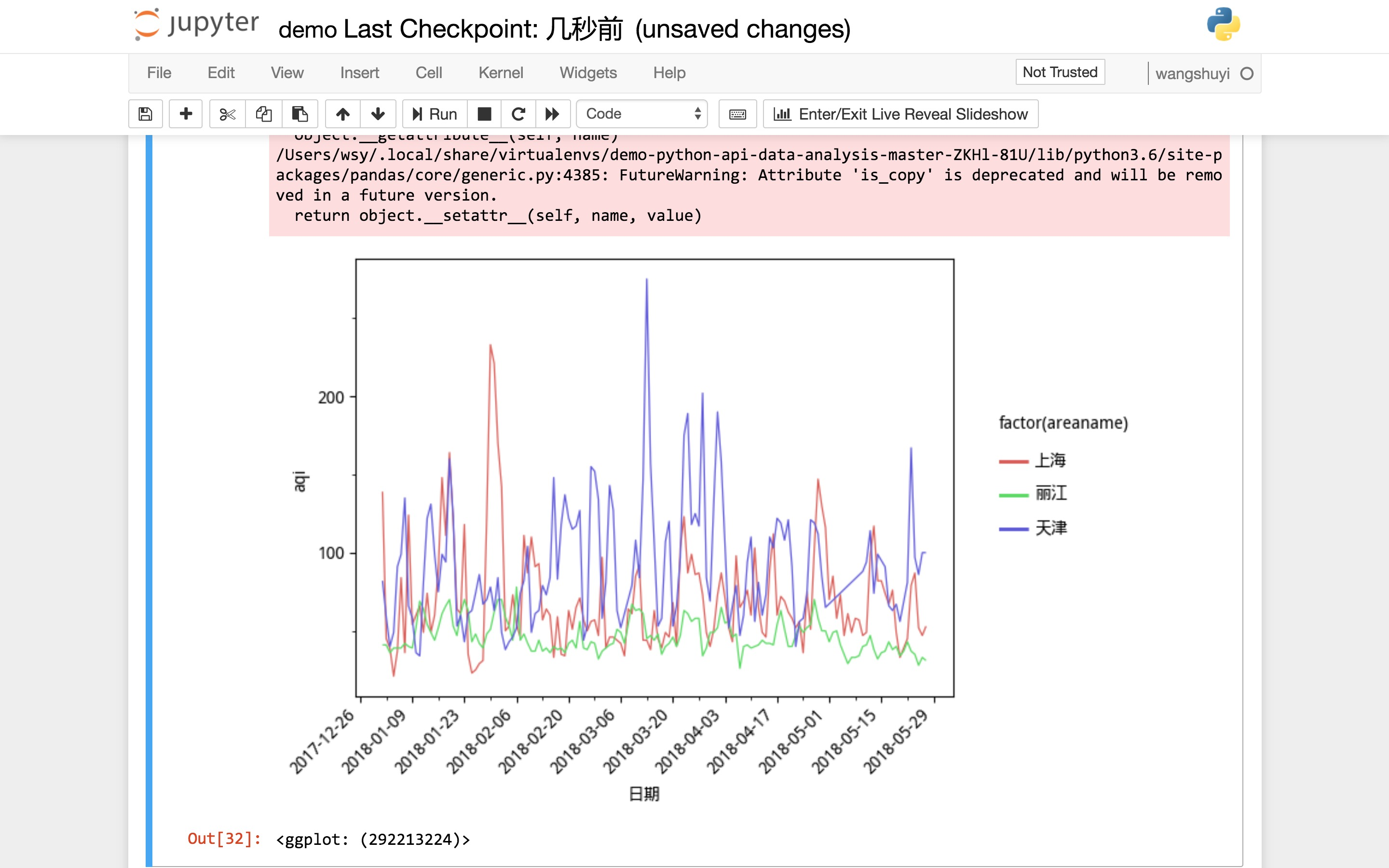
对于一般的教程源代码,上述步骤就可以了。但是因为《如何用 Python 和 API 收集与分析网络数据?》这篇文章,涉及到绘图,而且里面出现中文显示。
我们需要进行一些处理,以便让程序顺利运行,保证中文字符正常显示。
方法是执行下面这条语句:
pipenv run python handle_matplotlib_chinese.py
最后一步,开启 Jupyter Notebook :
jupyter notebook
这时候,你就可以看到熟悉的 Jupyter Notebook 界面了。
注意这个示例代码中,需要你输入自己的 AppCode,所以你需要把其中的“Your AppCode here”字样,替换为你自己的 AppCode值。否则下面的运行会报错。
替换之后,点击菜单栏中的“Cell”,选择“Run All”,看能否正常运行全部代码,并且显示分析结果图形。
如果一切正常,意味着你的 Python 运行环境克隆工作顺利完成。
祝贺你!
背景
有读者留言询问,为什么用了两套不同的虚拟软件包管理工具。
因为很遗憾,本文写作时, mybinder 还不支持 Pipfile 配置文件。
其实,我们这里用到的 Pipfile ,不是 pipenv 这个软件专用的配置文件格式。
它是未来 Python 软件包管理工具 pip 的官方指定配置文件格式。
在未来,如果你用 pip 安装软件,就要跟 Pipfile 打交道。
不过,Python 开源社区的很多举动,进展都很缓慢。
例如 Python 3,已经出来这么久了, Python 2 还没有退休呢。
pip 这种底层的包管理方式,哪是一两天就能发生根本改变的?
pipenv 出现,是因为人们不想等了。
现在,就是现在,我们要用最符合人性的 Python 软件包管理工具。
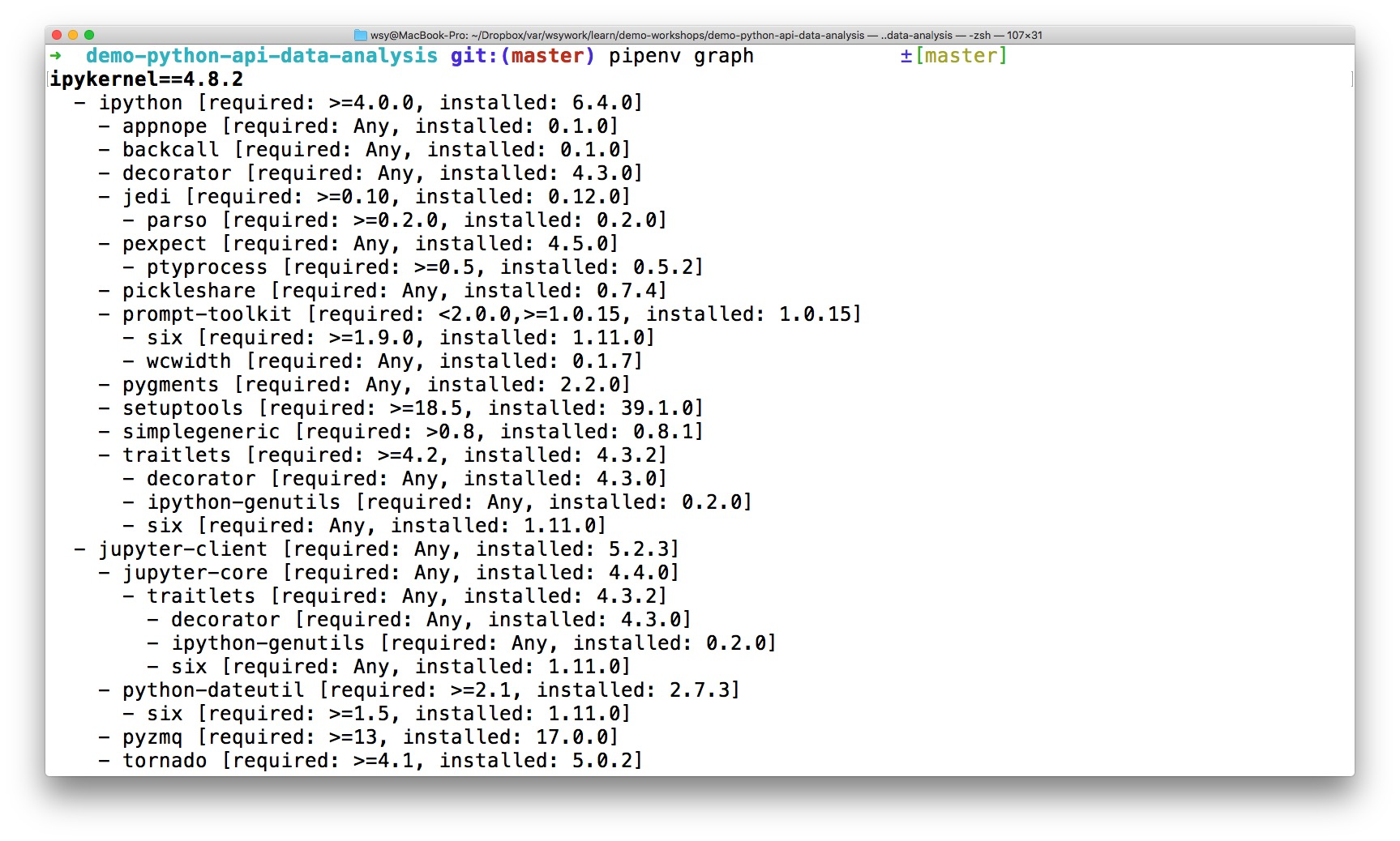
使用 pipenv,好处有很多。
仅举一例,用 pipenv ,你可以用一条命令,查看当前项目软件包之间的依赖关系。
感觉怎么样?
如果你对 pipenv 感兴趣,想了解它的特性、演进过程,请点击这个链接(http://t.cn/R1cYQSU),查看 PyCon 2018 大会上 Kenneth Reitz 的讲解。
Kenneth Reitz 是谁?
如果你读过我的《如何用 Python 和 API 收集与分析网络数据?》一文,你已经用过他的作品了。
对,“给人用的” (for humans) HTTP 工具,requests,就是他写的。
讨论
你更喜欢在 mybinder 直接在线运行 Python 教程代码,还是喜欢在本地克隆一个完整的运行环境呢?为什么?欢迎留言,把你的经验和思考分享给大家,我们一起交流讨论。
喜欢请点赞。还可以微信关注和置顶我的公众号“玉树芝兰”(nkwangshuyi)。
如果你对数据科学感兴趣,不妨阅读我的系列教程索引贴《如何高效入门数据科学?》,里面还有更多的有趣问题及解法。
延伸阅读