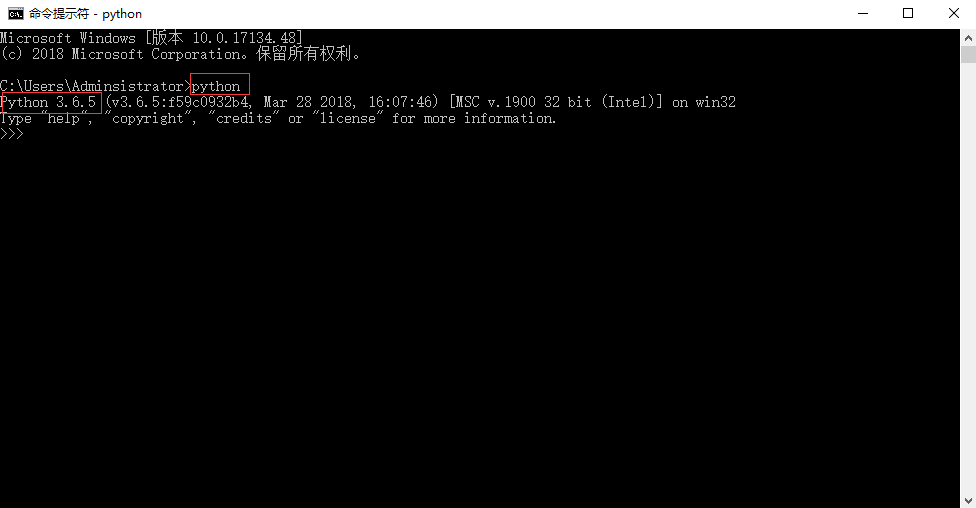
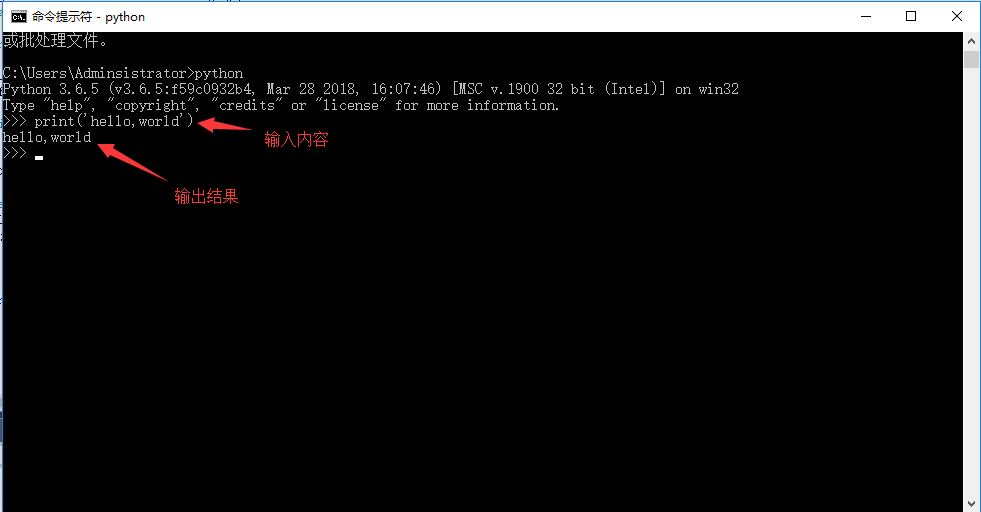
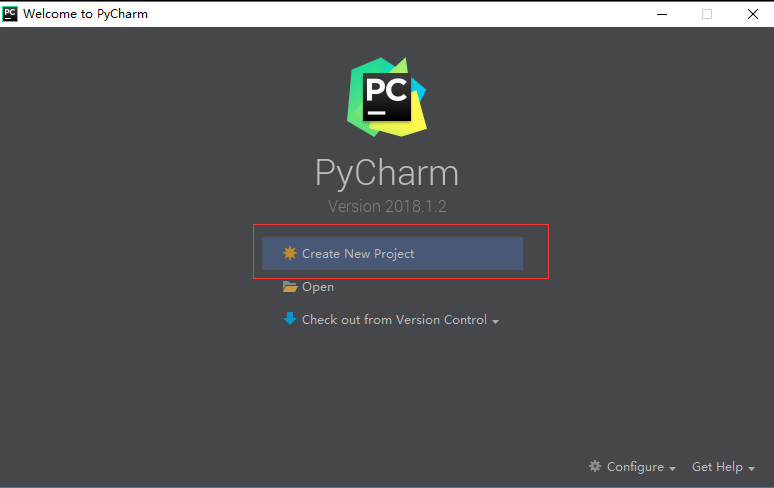
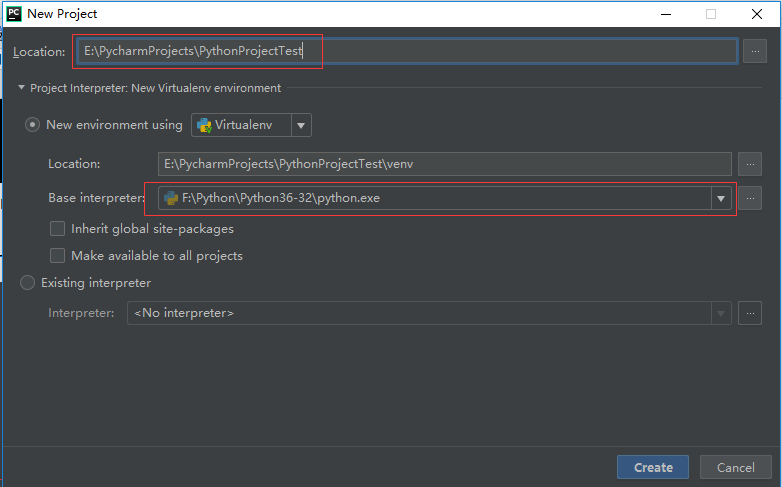
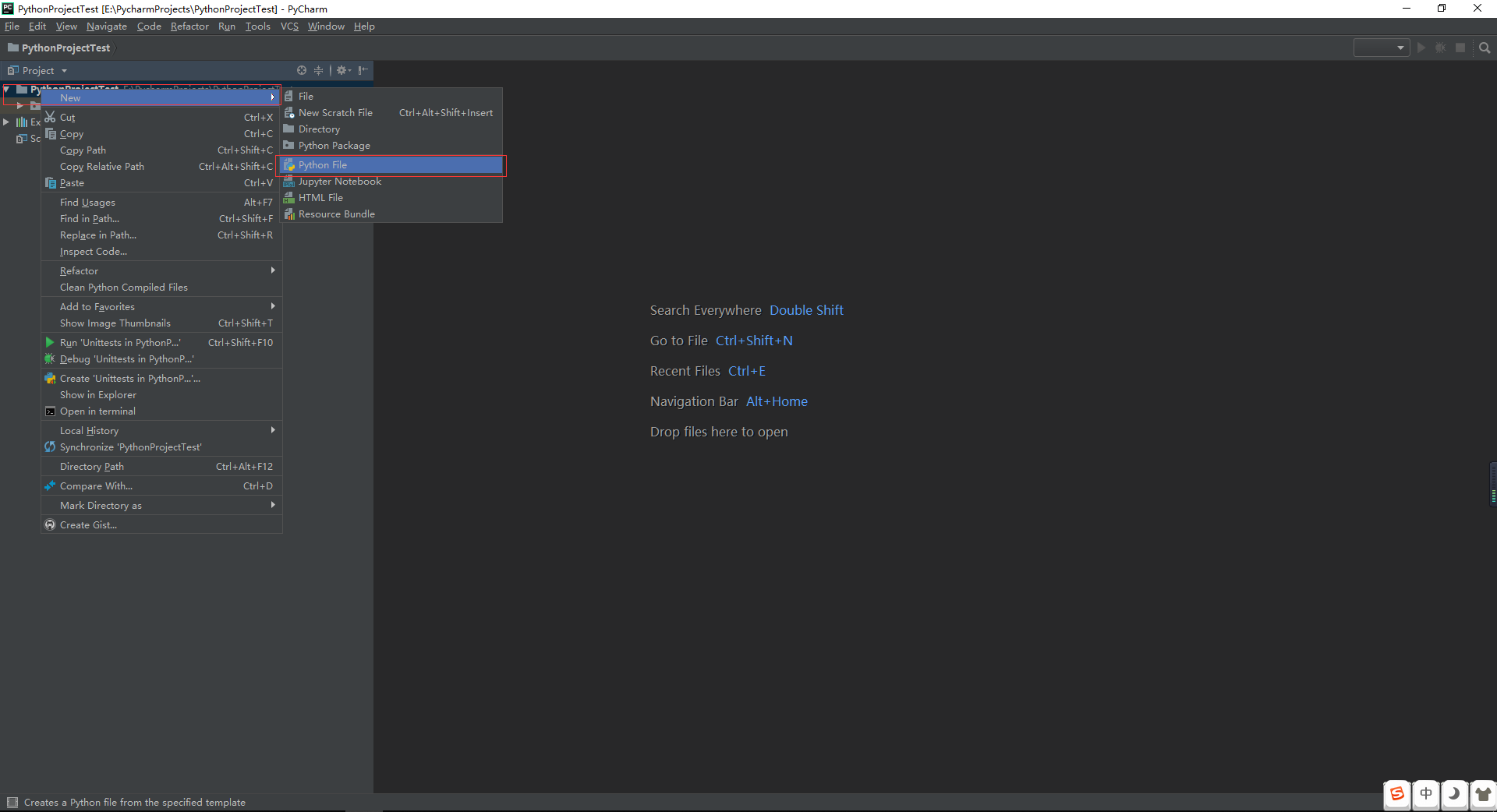
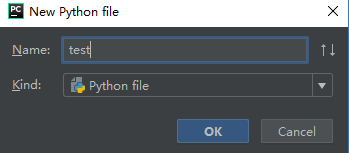
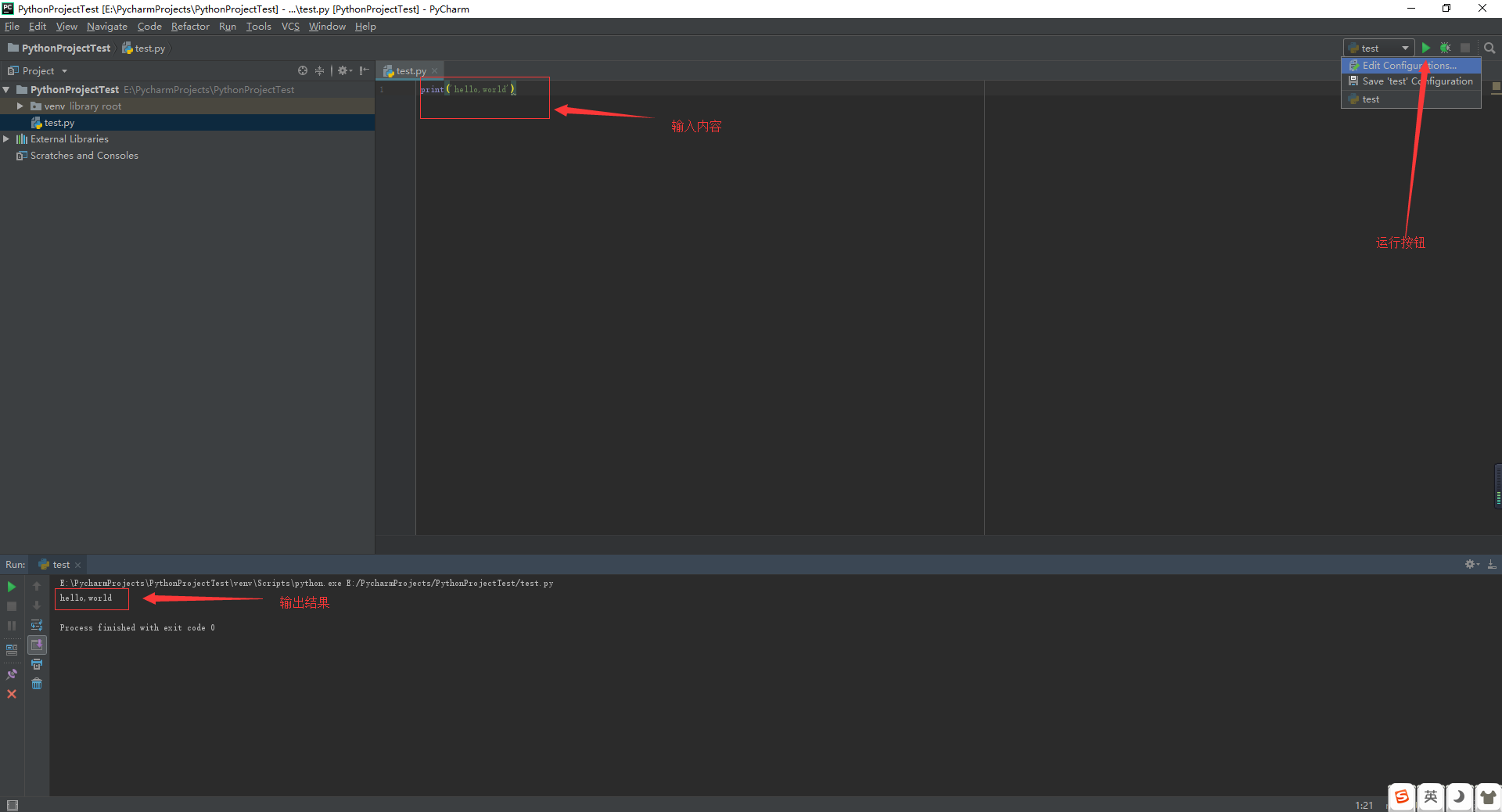

手把手教你在Python中实现文本分类(附代码、数据集)
文本分类是商业问题中常见的自然语言处理任务,目标是自动将文本文件分到一个或多个已定义好的类别中。文本分类的一些例子如下: 分析社交媒体中的大众情感 鉴别垃圾邮件和非垃圾邮件 自动标注客户问询 将新闻文章按主题分类 目录 本文将详细介绍文本分类问题并用Python实现这个过程: 文本分类是有监督学习的一个例子,它使用包含文本文档和标签的数据集来训练一个分类器。端到端的文本分类训练主要由三个部分组成: 1. 准备数据集:第一步是准备数据集,包括加载数据集和执行基本预处理,然后把数据集分为训练集和验证集。 特征工程:第二步是特征工程,将原始数据集被转换为用于训练机器学习模型的平坦特征(flat features),并从现有数据特征创建新的特征。 2. 模型训练:最后一步是建模,利用标注数据集训练机器学习模型。 3. 进一步提高分类器性能:本文还将讨论用不同的