本文将从以下几个方面介绍
前言
HashSet 的特点
类图
源码分析
HashSet 如何保证元素的不重复
总结
前言
在工作中,经常有这样的需求,需要判断某个ID是否在某个组的管理之下等,就需要查询该组下的ID放到一个集合中,且集合中元素不能有重复,之后判断该集合是否包含我们的目标ID;这时,我们可以使用 HashSet 来存放我们的ID,HashSet可以自动的帮助我们去重,比如HashSet<String> set = new HashSet<>(list) 等。接下来看下 HashSet 的内部是怎么实现的。
HashSet的特点
从 HashSet 的 Javadoc 的说明中,可以得到以下信息:
1. HashSet 底层是使用 HashMap 来保存元素的
2.它不保证集合中存放元素的顺序,即是无序的,且这种顺序可能会随着时间的推移还会改变
3.允许 null 值,且只有一个
4.HashSet 不是线程安全的,底层的 HashMap 不是线程安全的,它自然就不是啦,可以使用 Collections.synchronizedSet(new HashSet()) 来创建线程安全的 HashSet;synchronizedSet 方法底层会根据 Set 来创建 SynchronizedSet 对象,而 SynchronizedSet 类继承了 SynchronizedCollection,在 SynchronizedCollection 中的所有方法都加上了 synchronized 关键字,所以它是线程安全的,可以被多线程并发访问。
5.集合中的元素不会重复
类图
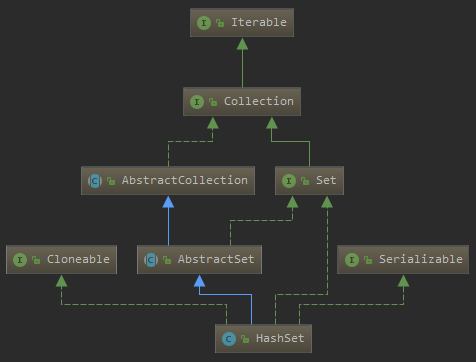
先来看看 HashSet 的一个类图
![]()
从类图中,可以看到, HashSet 继承了 AbstractSet 抽象类, 而 AbstractSet 又继承了 AbstractCollection 抽象类,此外,HashSet 还实现了 Set 接口等。
AbstractSet 抽象类主要实现了两个方法 equals 和 hashcode 方法,因为 HashSet 中没有重复元素,就是根据这两个方法来进行判断的:
public boolean equals(Object o) {
if (o == this)
return true;
if (!(o instanceof Set))
return false;
Collection<?> c = (Collection<?>) o;
if (c.size() != size())
return false;
try {
return containsAll(c);
} catch (ClassCastException unused) {
return false;
} catch (NullPointerException unused) {
return false;
}
}
public int hashCode() {
int h = 0;
Iterator<E> i = iterator();
while (i.hasNext()) {
E obj = i.next();
if (obj != null)
h += obj.hashCode();
}
return h;
}
Set 接口,它是一个顶层接口,主要定义了一些公共的方法,如 add, isEmpty, size, remove, contains 等一些方法;HashSet, SortedSet,TreeSet 都实现了该接口。
源码分析
接下来看下它的内部实现,它内部使用 HashMap 来存放元素,它的所有方法基本上都是调用 HashMap 的方法来实现的,相等于对HashMap包装了一层,关于 HashMap 的实现,可以参考 HashMap源码分析-jdk1.6和jdk1.8的区别。
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable
{
// 用来存放元素的 HashMap
private transient HashMap<E,Object> map;
// 因为 HashMap 是存放键值对的,而 HashSet 只会存放其中的key,即当做 HashMap 的key,
// 而value 就是这个 Object 对象了,HashMap 中所有元素的 value 都是它
private static final Object PRESENT = new Object();
// 无参构造,创建 HashMap 对象,初始大小为 16
public HashSet() {
map = new HashMap<>();
}
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
// 根据初始大小和加载因子创建 HashSet
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
// 根据初始大小创建 HashSet
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
// 迭代器
public Iterator<E> iterator() {
return map.keySet().iterator();
}
........................
}
从上面声明可看到,HashSet 底层是使用 HashMap 来存放元素的,且 HashMap 中所有元素的 value 都是同一个 Object 对象,且它被 final 修饰。
接下来看下它的方法实现:
// 返回集合中元素的个数
public int size() {
return map.size();
}
// 判断集合是否为空
public boolean isEmpty() {
return map.isEmpty();
}
// 集合中是否包含某个值,即判断 HashMap 中是否包含该key
public boolean contains(Object o) {
return map.containsKey(o);
}
// 添加元素,在这里可以看到,添加元素的时候,会向 HashMap 中添加,且 HashMap中的value都是同一个 Object对象
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
// 删除元素
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
// 清楚集合
public void clear() {
map.clear();
}
以上就是 HashSet 源码的全部实现了,看着很简单,但是要知道 HashMap 的实现过程才会清楚。
HashSet 如何保证元素的不重复
接下来,看下 HashSet 的 add 方法,看下它是如何保证添加的元素不重复的
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
之后来看下 HashMap 的 put 方法:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
put 方法会调用 putVal 方法进行添加元素,来看下 putVal 方法的实现:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 如果 key 的 hashcode 在 Node 数组中不存在,即 集合中没有改元素,则创建 Node 节点,加入到 Node 数组中,添加元素成功
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
// 如果在 Node 数组中该 key ,则在 Node 数组该索引上的链表进行查找
Node<K,V> e; K k;
// 链表上已经存在该元素
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
// 在该链表上找不到该key,则创建,插入到链表上
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 如果 key 已存在,则返回旧的值
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
// 如果元素不存在,则返回 null
return null;
}
所以,在向 HashSet 添加元素的时候,如果要添加元素的 hashcode 已存在,且 equals 相等,则会替换掉旧的值。
关于 HashMap 的其他方法实现,可以参考 HashMap源码分析-jdk1.6和jdk1.8的区别
以上就是 HashSet 的实现。看起来很简单,但是前提是得知道 HashMap 的实现。
总结
HashSet的特点
1. HashSet 底层是使用 HashMap 来保存元素的
2.它不保证集合中存放元素的顺序,即是无序的,且这种顺序可能会随着时间的推移还会改变
3.允许 null 值,且只有一个
4.HashSet 不是线程安全的,底层的 HashMap 不是线程安全的,它自然就不是啦,可以使用 Collections.synchronizedSet(new HashSet()) 来创建线程安全的 HashSet
5.集合中的元素不会重复