这一段,主要是 Spark 的基本概念,以及Anaconda的基本组成。
理解Spark
Hadoop 随着数据的增长水平扩展,可以运行在普通的硬件上, 所以是低成本的. 数据密集型应用利用可扩展的分布处理框架在大规模商业集群上分析PB级的数据. Hadoop 是第一个map-reduce的开源实现. Hadoop 依赖的分布式存储框架叫做 HDFS(Hadoop Distributed File System). Hadoop 在批处理中运行map-reduce任务.Hadoop 要求在每个 map, shuffle,和reduce 处理步骤中将数据持久化到硬盘. 这些批处理工作的过载和延迟明显地影响了性能.
Spark 是一个面向大规模数据处理的快速、分布式、通用的分析计算引擎. 主要不同于Hadoop的特点在于Spark 通过数据管道的内存处理允许不同阶段共享数据. Spark 的独特之处在于允许四种不同的数据分析和处理风格. Spark能够用在:
- Batch: 该模式用于处理大数据集典型的是执行大规模map-reduce 任务。
- Streaming: 该模式用于近限处理流入的信息。
- Iterative: 这种模式是机器学习算法,如梯度下降的数据访问重复以达到数据收敛。
- Interactive: 这种模式用于数据探索,有用大数据块位于内存中,所以Spark的响应时间非常快。
下图描述了数据处理的4种方式:
![Spark Processing Styles]()
Spark 有三种部署方式: 单机单节点和两种分布式集群方式Yarn(Hadoop 的分布式资源管理器)或者Mesos(Berkeley 开发的开源资源管理器,同时可用于Spark):
![Spark Components]()
Spark 提供了一个Scala, Java, Python, and R的多语言接口.
Spark libraries
Spark 时一个完整的解决方案, 有很多强大的库:
- SparkSQL: 提供 类SQL 的能力 来访问结构化数据,并交互性地探索大数据集
- SparkMLLIB: 用于机器学习的大量算法和一个管道框架
- Spark Streaming: 使用微型批处理和滑动窗口对进入的流数据T实现近限分析
- Spark GraphX: 对于复杂连接的尸体和关系提供图处理和计算
PySpark实战
Spark是使用Scala实现的,整个Spark生态系统既充分利用了JVM环境也充分利用了原生的HDFS. Hadoop HDFS是Spark支持的众多数据存储之一。 Spark与其相互作用多数据源、类型和格式无关.
PySpark 不是Spark的一个Python转写,如同Jython 相对于Java。PySpark 提供了绑定Spark的集成 API,能够在所有的集群节点中通过pickle序列化充分使用Python 生态系统,更重要的是, 能够访问由Python机器学习库形成的丰富的生态系统,如Scikit-Learn 或者象Pandas那样的数据处理。
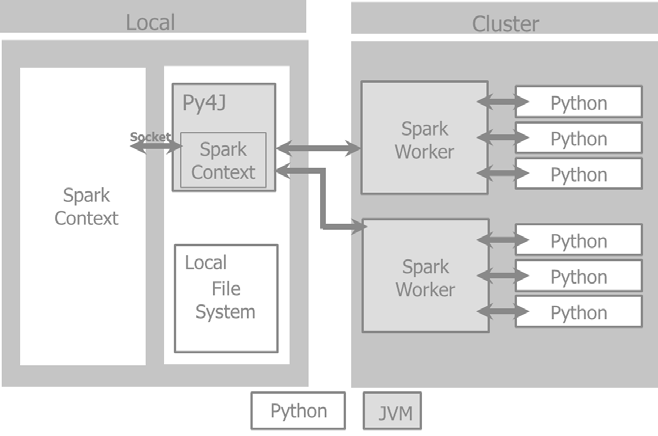
当我们着有一个Spark 程序的时候, 程序第一件必需要做的事情是创建一个SparkContext 对象,来告诉Spark如何防蚊鸡群。Python程序会创建PySparkContext。Py4J 是一个网关将Spark JVM SparkContex于python程序绑定。应用代码JVM SparkContextserializes
和闭包把他们发送给集群执行.
集群管理器分配资源,调度,运送这些闭包给集群上的 Spark workers,这需要激活 Python 虚拟机.
在每一台机器上, 管理 Spark Worker 执行器负责控制,计算,存储和缓存.
这个例子展示了 Spark driver 在本地文件系统上如何管理PySpark context 和Spark context以及如何通过集群管理器与 Spark worker完成交互。
![PySpark]()
弹性分布数据集(RDS,Resilient Distributed Dataset)
Spark 应用包含了一个驱动程序来运行用户的主函数,在集群上创建分布式数据集, 并在这些数据集上执行各种并行操作
(转换和动作 )。 Spark 应用运行在独立的进程集合, 与一个驱动程序中的一个 SparkContext 协调工作。SparkContext 将从集群管理器中分配系统资源 (主机, 内存, CPU)。
SparkContext管理执行器,执行器来管理集群上的多个worker .驱动程序中有需要运行的Spark 工作。这些工作被分拆成多个任务,提交给执行器来完成。执行器负责每台机器的计算,存储和缓存。Spark 中的核心构建块是 RDD (Resilient Distributed Dataset). 一个已选元素的数据集。分布意味着数据集可以位于集群的任何节点。弹性意味着数据集在不伤害数据计算进程的条件下可以全部或部分丢失,spark 将重新计算内存中的数据关系,例如操作 DAG (Directed Acyclic Graph) 基本上,Spark 将RDD的一个状态的内存快照放入缓存。如果一台计算机在操作中挂了, Spark 将从缓存的RDD中重建并操作DAG,从而使RDD从节点故障中恢复。
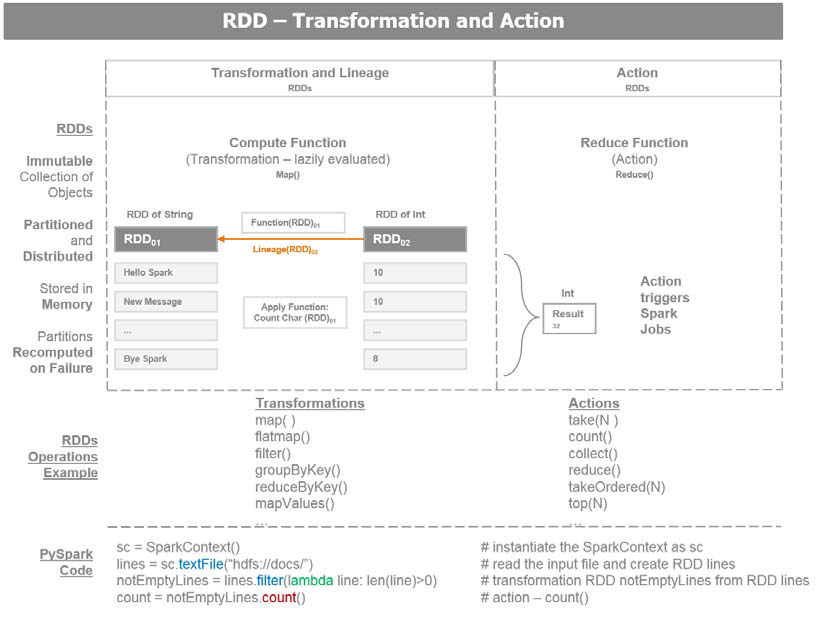
这里有两类的RDD 操作:
• Transformations: 数据转换使用现存的RDD,并生产一个新转换后的RDD指针。一个RDD是不可变的,一旦创建,不能更改。 每次转换生成新的RDD. 数据转换的延迟计算的,只有当一个动作发生时执行。如果发生故障,转换的数据世系重建RDD
.
• Actions: 动作是一个RDD触发了Spark job,并缠上一个值。一个动作操作引发Spark 执行数据转换操作,需要计算动作返回的RDD。动作导致操作的一个DAG。 DAG 被编译到不同阶段,每个阶段执行一系列任务。 一个任务是基础的工作单元。
这是关于RDD的有用信息:
-
RDD 从一个数据源创建,例如一个HDFS文件或一个数据库查询 .
有三种方法创建 RDD:
∞从数据存储中读取
∞ 从一个现存的RDD转换
∞使用内存中的集合
RDDs 的转换函数有 map 或 filter, 它们生成一个新的RDD.
- 一个RDD上的一个动作包括 first, take, collect, 或count 将发送结果到Spark 驱动程序. Spark驱动程序是用户与Spark集群交互的客户端。
下图描述了RDD 数据转换和动作:
![RDD]()
理解 Anaconda
Anaconda 是由 Continuum(https://www.continuum.io/)维护的被广泛使用的Python分发包. 我们将使用 Anaconda 提供的流行的软件栈来生成我们的应用. 本书中,使用 PySpark和PyData生态系统。PyData生态系统由Continuum维护,支持并升级,并提供 Anaconda Python 分发包。Anaconda
Python分发包基本避免了python 环境的安装过程恶化从而节约了时间;我们用它与Spark对接. Anaconda 有自己的包管理工具可以替代传统的 pip install 和easy_install. Anaconda 也是完整的解决方案,包括一下有名的包如 Pandas, Scikit-Learn, Blaze, Matplotlib, and Bokeh. 通过一个简单的命令久可以升级任何已经安装的库:
`$ conda update`
通过命令可以我们环境中已安装库的列表:
$ conda list
主要组件如下:
* Anaconda: 这是一个免费的Python分发包包含了科学,数学,工程和数据分析的200多个Python包
* Conda: 包管理器负责安装复杂软件栈的所有依赖,不仅限于 Python ,也可以管理R和其它语言的安装进程。
* Numba: 通过共性能函数和及时编译,提供了加速Python代码的能力。
* Blaze: 通过统一和适配的接口来访问提供者的数据来实现大规模数据分析,包括Python 流处理, Pandas, SQLAlchemy, 和Spark.
* Bokeh: 为巨型流数据集提供了交互数据的可视化.
* Wakari: 允许我们在一个托管环境中分享和部署 IPython Notebooks和其它应用
下图展示了 Anaconda 软件栈中的部分组件:
![Anaconda Stack]()