1.概述
在Hadoop应用,随着业务指标的迭代,而使其日趋复杂化的时候,管理Hadoop的相关应用会变成一件头疼的事情,如:作业的依赖调度,任 务的运行情况的监控,异常问题的排查等,这些问题会是的我们日常的工作变得复杂。那么,在没有条件和精力去开发一套调度系统的情况下,我们去选择一款第三 方开源的调度系统,来尽量减轻和降低我们日常工作的复杂度,也是极好的。今天,笔者给大家比较几种常见的调度系统,供大家去选择。
2.内容
2.1 Oozie
Oozie目前是托管在Apache基金会的,开源。在之前的博客《Oozie调度》 一文当中,介绍相关Oozie的调度,如何去调度Hadoop的相关,大家可以从博客的文中所描述的内容看出,配置的过程略显繁琐和复杂,配置相关的调度 任务比较麻烦,然其可视化界面也不是那么的直观,另外,对UI界面要求较高的同学,此调度系统估计会让你失望。若是对改调度系统感兴趣的同学可以到《Oozie调度》一文中做相关细节的了解。这里就不多做赘述了。
2.2 Zeus
它是一个Hadoop的作业平台,从Hadoop任务的调试运行到生产任务的周期调度,它支持任务的整个生命周期。从其功能来看,它支持以下任务:
- Hadoop的MapReduce任务调度运行
- Hive任务的调度运行
- Shell任务的运行
- Hive元数据的可视化展示查询及数据预览
- Hadoop任务的自动调度
其开源地址在Github上面,可在Github搜索Zeus,即可找到相关工程。Zeus是由阿里巴巴开源出来的,文档在Github上描述的也比较详细,其相关安装步骤及使用方法可参考Github上的官方文档,这里就不多做赘述了。
2.3 Azkaban
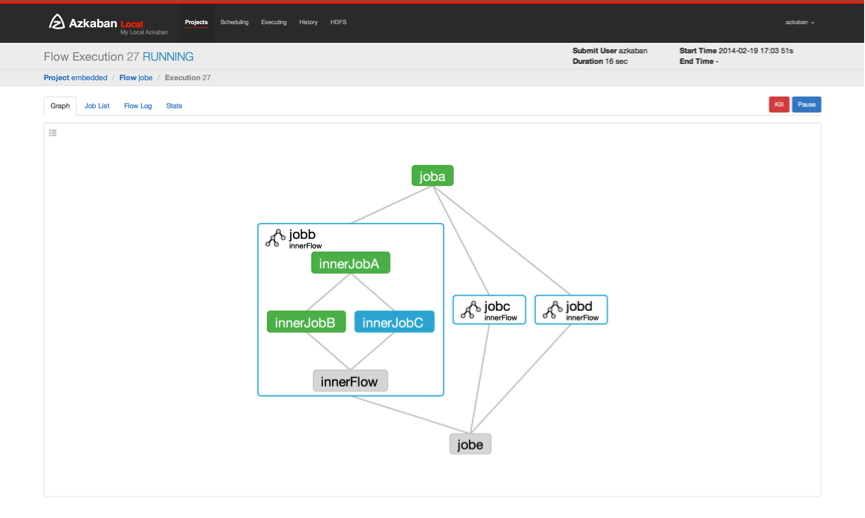
这是由LinkedIn创建的一个批处理工作流,用于跑Hadoop的Jobs。Azkaban提供了一个易于使用的用户界面来维护和跟踪你的工作流程。其可视化界面如下所示:
![]()
另外,Github上贡献的Azkaban调度系统的源码量不大,做二次开发难度不大。其功能点涉及以下内容:
- 兼容Hadoop版本
- 易用的Web UI
- 简单的Web和Http工作流的上传
- 项目工作区
- 工作流调度
- 模块化和插件化
- 认证和授权
- 用户行为跟踪
- 邮件告警失败和成功
- SLA告警
- 重启失败的Jobs
Azkaban的设计之初主要是基于可用性的考虑。在LinkedIn运行的有些年头了,一直驱动着它们的Hadoop和数据仓库。
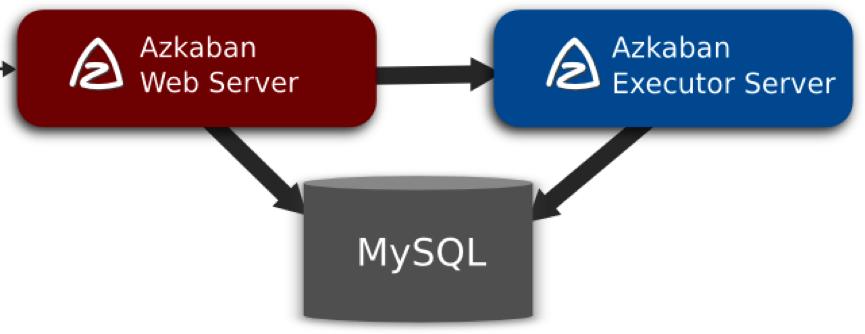
它由3个关键部分组成,分别是:
- 关系行数据库(MySQL):Azkaban使用MySQL去做一些状态的存储。AzkabanWebServer和AzkabanExecutorServer这两个服务都需要接入到DB库当中。
- AzkabanWebServer:WebServer使用DB的原因如下:
- 项目管理:对项目权限和上传文件的管理。
- 执行流程状态:对正在执行的程序进行跟踪。
- 之前的流程或Jobs:通过搜索先前的工作和流程,去访问它们的日志文件。
- 调度程序:保持预定的工作状态。
- SLA:保持所有的SLA规则。
- AzkabanExecutorServer:另外,ExecutorServer使用DB的原因如下所示:
- 获取项目:从数据库中检索项目文件。
- 执行工作流或Jobs:检索和更新流的数据,并执行。
- Logs:存储作业的输出日志,并将其流入数据库。
- 不同的依赖进行交流:如果一个流在不同的执行器上运行,它将从数据库中取取状态。
三者的关系图,如下所示:
![]()
关于其相关配置和使用,官方给出的文档比较详细,这里就不多赘述了。大家可以到Github去阅读官方给出的文档。
3.总结
关于调度系统的选择,这里就比较了这3种,大家可以适情况而定,另外,若是条件允许或是有精力也可以参考这些调度系统的原理,开发一套满足自己当前业务的调度系统,也不失为一种选择。
4.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!