Python远程连接服务器上的Oracle数据库
![]()
1、正确的开启方式
在你的IPython或者是Anaconda的jupyter中输入一下代码,其中:
‘username’—— 用户名
‘password’——密码
‘192.168.1.1:1521/service_name’——IP/端口号/服务名称
import cx_Oracle
conn = cx_Oracle.connect('username','password','192.168.1.1:1521/service_name')
如果以上代码不会报错,那么你应该是已经成功连接数据库了。而如果报错,检查一下是什么问题。
2、暴露问题
(1)cx_Oracle未安装
如果上位安装cx_Oracle包,可以在cmd状态下,到Python安装目录下,使用pip命令完成安装。
pip install cx_Oracle
(2)缺少instanctclient
如果本机没有安装Oracle数据库,又要通过Python访问远程服务器上的Oracle,那么需要在本机上安装instantclient。安装可以从Oracle官网获取安装包,如果没有账号可以自行注册。注册完成后可以免费获取不同版本的instantclient。下载地址:http://www.oracle.com/technetwork/database/database-technologies/instant-client/overview/index.html
![这里写图片描述]()
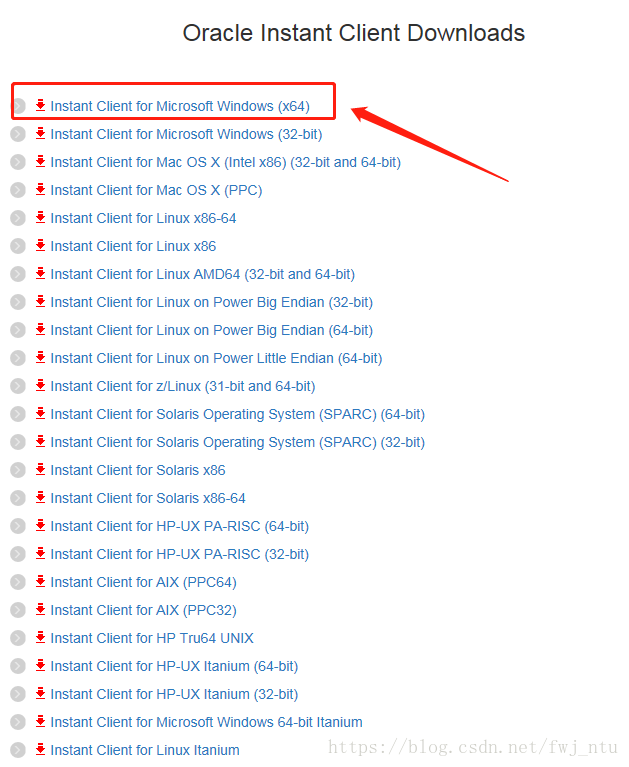
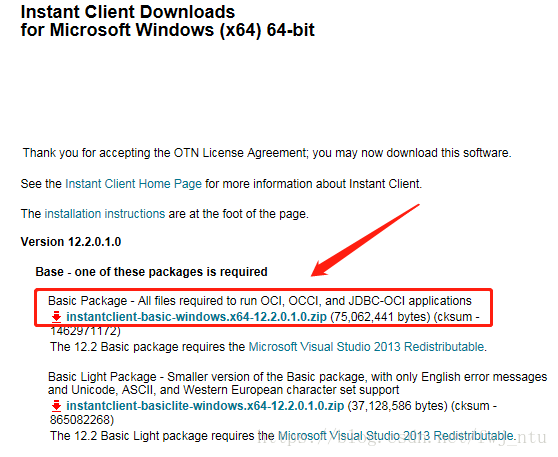
比如要下载这个64位版本的,点进去,下载这个文件就可以了:
![这里写图片描述]()
下载完成后,解压缩到相应的位置。完成以下几步:
(1)将解压缩文件的文件路径追加到PATH环境变量中
(2)在解压缩的文件夹下创建一个命名为‘ tnsnames.ora ’的文件
在文件中写入以下内容,根据实际情况修改HOST、SERVICE_NAME内容
orcl =
2. (DESCRIPTION =
3. (ADDRESS_LIST =
4. (ADDRESS = (PROTOCOL = TCP)(HOST = localhost)(PORT = 1521))
5. )
6. (CONNECT_DATA =
7. (SERVER = DEDICATED)
8. (SERVICE_NAME = sys)
9. )
10. )
(3)将解压的文件夹中的 oci.dll, oraocci12.dll,oraociei12.dll 拷贝到python安装目录下的lib/site-packages中
3、解决问题
再次尝试以下代码,应该就没有问题了。
import cx_Oracle
2.
3.conn=cx_Oracle.connect('user','password', '127.0.0.1:1521/database')
4.print('连接成功!')
5.
6.cursor = conn.cursor()
7.
8.sql="""
9. select count(*) from table_a
10.
11. """
12.
13.cursor.execute(sql)
14.alldata = cursor.fetchall()
15.
16.cursor.close()
17.conn.close()
原文地址http://www.bieryun.com/3588.html